本篇文章为大家展示了基于Anyproxyrhrh 使用"中间人攻击"爬取公众号推送,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
以前博客一直使用的是别人制作的框架,typecho、WordPress等都有使用过,但由于是别人的框架,始终不知道其内部运作的原理。这次使用Node.js完全重构了一遍,使得我对整个博客的运作原理清晰了许多,以前看起来很复杂的东西(WordPress 留下的第一印象,虽然WordPress其实不全是用来做博客的),现在看起来竟是这么简单,如果有用框架搭建博客的朋友,建议完全自己做一个试试。当然,这些都不是本次推送的重点,半自动化爬取自己的公众号推送才是重点。
爬取所需要的环境与工具:
后端:Node.js + MongoDB
代理服务器:Anyproxy
一个安卓模拟器
服务器环境:
Node.js + MongoDB
首先介绍一下Anyproxy, 这是一个基于Node.js的代理服务器,本项目中,Anyproxy的作用如下:若把我们本机当做代理服务器,手机模拟器中的微信当成客户端,那么其运作原理可以如下图所示。手机客户端(Client)发送请求给代理服务器(Server,即本机),本机再将这个请求发送给微信服务器,微信服务器返回信息需要经过本机,再由本机传递给手机客户端。
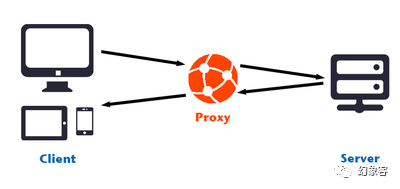
在这个过程中,本机承担中间人的作用,而接受到微信返回的信息后,我们可以对那个信息植入脚本,再发送给手机客户端。这就是中间人攻击。
对了,使用Anyproxy还有一个好处就是,它支持HTTPS,它能够生成证书,使得客户端和代理服务器端互相信任,从而能接收HTTPS请求和回复,而公众号历史消息中,许多请求都是HTTPS的。
步骤如下(参考自 :https://zhuanlan.zhihu.com/p/24302048)
1.新建一个Node.js项目,新建MongoDB数据库(可先在本地上进行调试),新建一个名为blog的库,名为articles的Collections.
2.运行终端执行下面这个命令安装Anyproxy:
sudo npm -g install anyproxy
3.生成证书,使其支持https
sudo anyproxy --root
4.启动Anyproxy, 运行
sudo anyproxy -i
5.在安卓模拟器中安装证书:
启动Anyproxy, 在浏览器中访问 localhost:8002/qr_root 可以获取证书路径的二维码,移动端安装时会比较便捷,使用微信识别二维码即可完成安装。
6.设置代理,打开模拟器的WiFi,修改WiFi-使用代理,代理服务器地址就是运行anyproxy的电脑的ip地址。代理服务器默认端口是8001。
现在微信上任何联网操作,在运行Anyproxy的终端中或打开 http://localhost:8002 应该都可以看到服务器返回的信息了。如图所示:
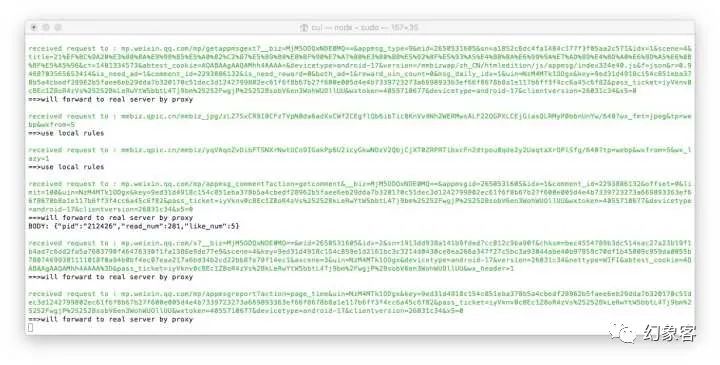
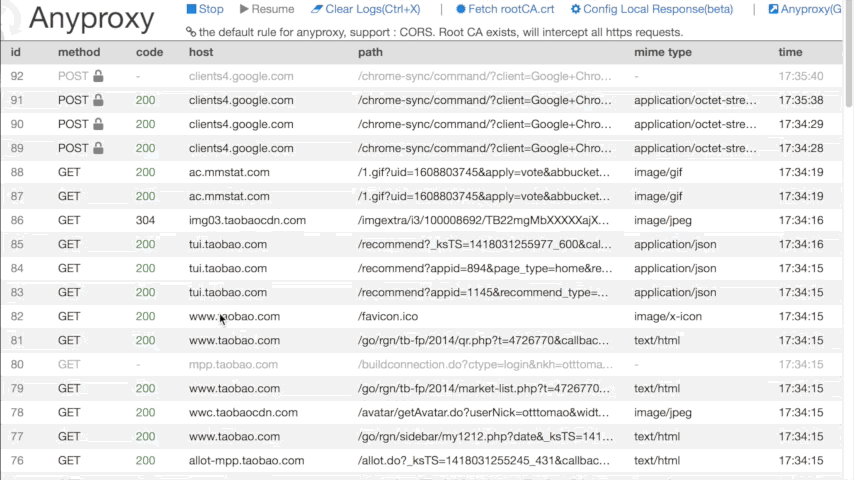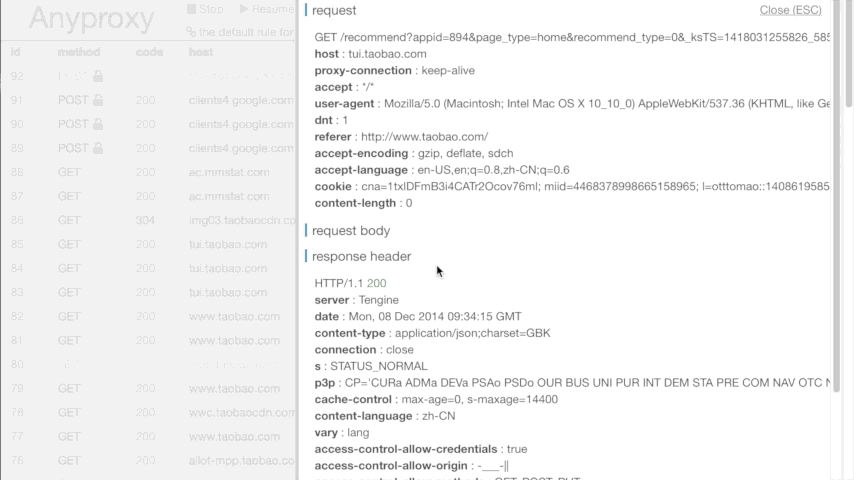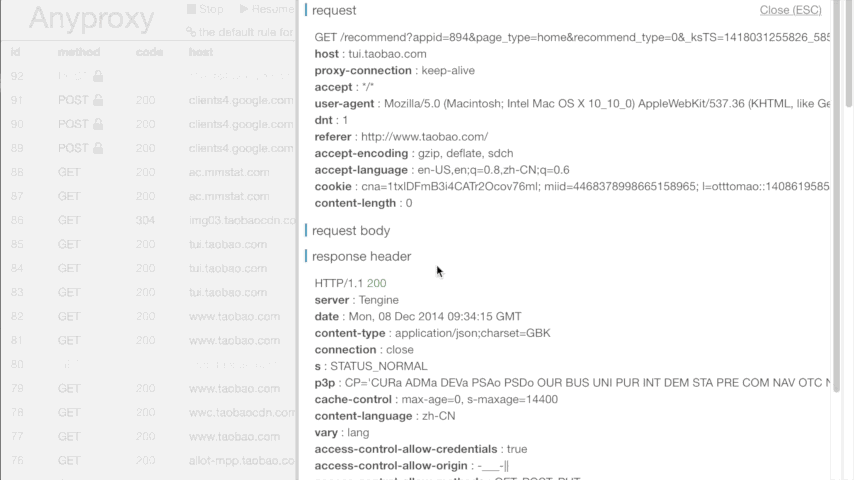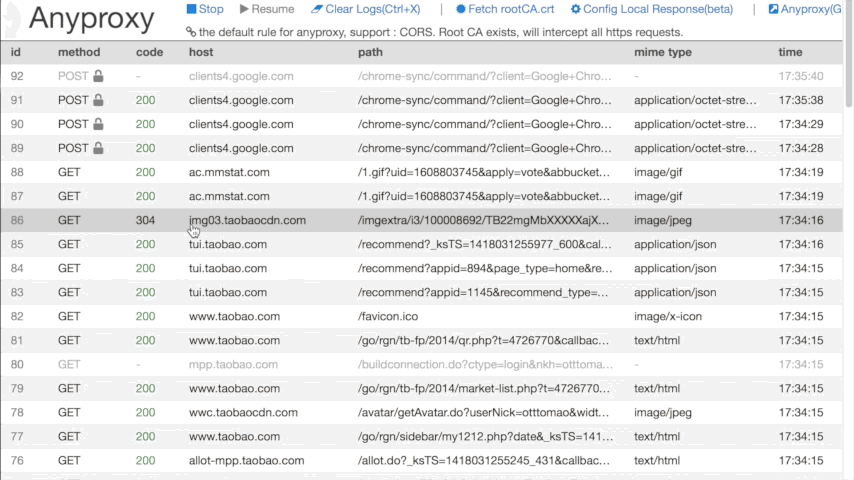
在这过程中,若你有任何疑问,可见最上面感谢的那篇文章。
接下来植入脚本,植入脚本我们是通过修改配置文件实现的。
配置文件地址:
Mac在 /usr/local/lib/node_modules/anyproxy/lib/.
Windows据说在 APPdata\Roaming(若不是的话请找一下Windows npm默认全局安装的位置)。
我们只需要修改rule_default.js内的replaceServerResDataAsync:function(req,res,serverResData,callback) 函数
由于那篇文章里是大型爬虫代码,我只需要爬取个人公众号的,因此对其进行了修改,并转换成了js代码。代码就先不贴了,有兴趣可以见GitHub库:https://github.com/Ckend/GzhToBlog,喜欢请star一下,让我有动力更新。
步骤如下:
1.启动Anyproxy, 打开公众号的历史消息列表,在 localhost:8002 观察Anyproxy接收到的信息中哪一个是消息列表的。最后发现带有profile-ext的链接的是消息列表相关的。
插句题外话,profile-ext里的-其实是_才对,但是公众号推送检测文章里是否引用了别的公众号的文章竟然就是通过这个关键词,惊了个呆,知道我浪费了半小时来找这篇文章的错,最后发现是这里的表情是怎样的吗。
2.于是对带有profile-ext的链接的回复(有两种,一种是页面格式,一种是json(第二页以后就是json))进行植入脚本。将其返回的所有信息存入之前所创建的MongoDB数据库blog里的Collections中(见GitHub里rule_default.js文件的getToMongodb()函数,建议先连接本地的MongoDB,成功后再连接服务器的)。
3.在模拟器上往下拖,保存所有的推送。
4.新建一个js文件,负责通过前面所爬取到的articles里的文章链接爬取文章并保存到数据库中(GitHub里对应crawl.js)。
5.大功告成,接下来就差前端渲染数据展现博客了。
上述内容就是基于Anyproxyrhrh 使用"中间人攻击"爬取公众号推送,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4526838/blog/4583834



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



