本篇文章为大家展示了MYSQL Replace into和Insert into duplicate key update的对比分析 ,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
有些同学对MYSQL中两个看似相同功能的语句,在使用中感到疑惑,到底是功能重复还是各有各自的特点,我们需要弄清楚,并在合适的场合对他们加以利用。
我们通过几个操作来详细了解一下他们的使用方式和异同点
情况一, 判断当前ID 是否存在 ID = 1 的记录,如果有就更新数据,如果没有则插入记录
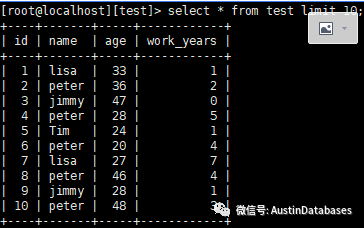
这里如果我们单纯使用UPDATE 语句,则会比较麻烦,首先我们需要判断是否有 ID =1 的记录,并且根据判断后的结果进行下一步的操作。
使用 replace 功能就可以满足上面的要求

数据已经被直接更改了,其实说准确一点,不是更新而是两个操作,细心的同学应该已经发现了上面图中的是 2 rows affected ,本来是一条数据,怎么蹦出来两条了。(注意2 rows affected)
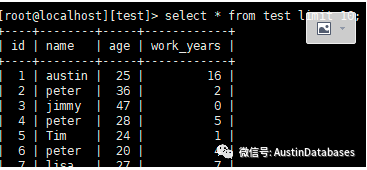
Replace into 语句主要是通过主键和唯一索引来判断数据的重复性,继而 1 先删除数据,2 在插入数据的套路,实际是一条语句,完成了判断,删除,插入的操作,这样的设计可以免除某些程序对表中数据处理的特殊需求。
可能熟悉MYSQL 的同学马上又会问到,不是还有INSERT DUPLICATE KEY 的语句吗,他和 replace into 语句又有什么不同?
需求2 , 现在需要在test 表中插入数据,如果不重复就批量插入数据,如果重复,就更新其中某个值

很明显,操作后重复的数据被更新,而没有重复的数据被插入,那他同学所问的异同点在哪里?
1 replace into 是否可以批量插入数据,insert duplicate key 都是可以的,
2 repace into 和 insert duplicate key 都可以更新数据
3 replace into 后面不可以接 select 语句 不可以, insert into duplicate key 是可以接入select 语句的 ,这在两条语句在适用的环境上有了明显的分割。
4 对数据库表的操作不同,一个是 delete , insert ,一个仅仅是 insert update ,这在数据库的物理操作层面也是根本的不同
最关键的一点不同是是对自增键的处理上,如果我们不指定自增主键的数据,(这里假设我们使用的是通过唯一索引进行判断,而不是自增主键),那结果就大大的不同了,replace into 会删除重复的行,在插入一行新的,而 insert into duplicate key 则是不会改变原有的自增主键,而是直接UPDATE,这在基于自增主键在应用中使用时有根本性的不同,(ORACLE 的亲们可能不大理解这个事情,因为ORACLE 本身在设计之初就没有自增主键,底层数据存储设计不同,造成ORACLE 理解 SQL SERVER MYSQL 某些数据表设计和处理上困难,同理SQL SERVER MYSQL 要理解 ORACLE 在某些数据表设计也有障碍),言归正传MYSQL 的程序员在使用这两条语句我总结了相关使用的场景。
1 少数据量非大批量数据的更新,并且整行数据都要变化的情况下,可以采用REPLACE INTO ,并且如果主键和应用有紧密联系,需要指定主键值,否则原数据行主键消失,这在某些与应用中是有用的,因为就是不要原有的主键,要一条新的ID包含新的值
2 大批量数据更新和插入,两张或多张表,合并插入到一张表,并且去重,或者更新某个字段的VALUE 需要使用 INSERT INTO duplicate key update 语句
如果同样大数据量的情况下,insert into duplicate key update 语句的性能要比 replace into 性能要好,两次操作和 一次操作对操作性能的影响也是不言而喻。
注:测试中,5.X 中在 insert into duplicate key update 中关于自增主键的某些小问题,貌似在8.0上已经消失了,具体还的在测试。看来8.0 的确是值得期待和拥有的。
上述内容就是MYSQL Replace into和Insert into duplicate key update的对比分析 ,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





