Insert的性能为啥这么差,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
最近发现单位某些系统的的插入性能不是很好,诚然知道物理存储的性能不是很好,在关键系统都在使用SSD 的时代,我们还没有进入SSD的怀抱。但另一个点,为什么有的地方使用费SSD 的设备,其实插入的性能还好,或者说如果换装SSD 设备后,其实也看不出区别。 排除数据量小的问题,其实数据库对插入的优化也是需要的。
那么我们分析一下,插入其中会遇到哪些问题,这里我们可能不会限定某种数据库,而是大范围的讨论,当然有些问题可能是针对某些数据库,这边会有所体现。
1 问题, 我们是使用自增的方式 还是使用散列的方式进行数据的插入
其实这是一个好问题,有人说自增型的插入符合了某些数据库的物理数据存放的属性,所以查找快,有人说散列的方式插入快,我把KEY都打散,插入,一定比顺序的方式好。
我个人其实对“一定”这个词不是很有好感,活了这么多年,一定这个词在我这属于不靠谱的词汇 LIST。
那到底是不是这样,我们来进行分析,如果是自增的方式,在大量数据插入的时候,会出现热点问题,我们现已MYSQL 为例
线程 1
insert into table (......) values (.........),(.........).......
线程2
insert into table select .... from table 2
我们来看一下上面的语句,如果同时运行,而且我们还是用了MYSQL的 自增方式会出现什么问题。
对,自增主键的热点,这也就是MYSQL 在5.5之前在大量数据插入的时候,被诟病的问题。那后来MYSQL 是怎么解决的,这里就要说到MYSQL的 自增的 三个参数,我们现在大部分选择
innodb_autoinc_lock_mode = 2
这样的选择,有什么问题?显而易见,ID 在大量的插入的时候,可能出现不连续的问题。

我们通过上面的语句可以看到什么,一个插入的语句要使用 using where using temporary, 为什么? 大家可以思考一下这个问题,并且想想如果这个select后面的语句是大量的数据,对一个高频词运行效率优先的系统,是不是一件好事情。文章结尾会有一个简单的说明。
另外我们需要考虑一下,如果我们不使用自增的方式,通过类似MONGODB 散列的方式生成主键插入, (其实还不是,类似UUID 这样的东西才是散列),且我们这边将MONGODB 的 OBJECT ID 视为散列(无序)。
MONGODB 中的主键主要是由几个方面产生的,unix 时间,MONGODB的机器码标识,一个随机数,等等生成的,这里便宜一个话题,如果想使用雪花算法,可以考虑借鉴一下 MONGODB 的OBJECT_ID的生成方法,当然MONGODB的 OBJECT_ID 考虑了很多,所以对数以亿万的数据也不会有撞库的风险。
以下就是MONGODB 的数据存储的方式,这点方式和 HEAP 表的存储方式类似,当然由于非事务性性(请别说4.0有事务,那个事务充其量算是对某些场合的数据操作的有益补充,不能和传统数据库做比较)
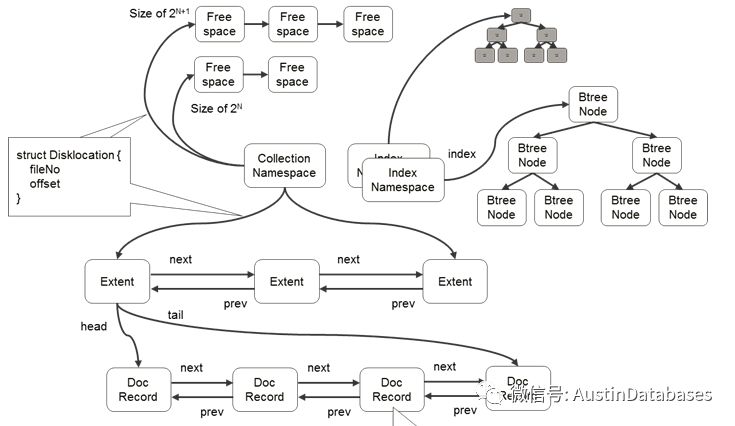
所以今天我们谈了几个问题
1 数据的插入与生成的主键的方式有关
2 数据插入速度,和INSERT 语句的写法有关
3 数据的插入和附加信息有关(INDEX,外键,每行的附加信息,PAGE页面的设计存储方式)有关(这点本次么有提到)
4 数据的插入和数据的插入行中的某些附加的函数运算或者一些附加信息有关(本次没有提到)
5 数据的插入方式,与数据库LOG的关系(本次没有提到)
凡是,没有提到的问题,会在找一期来说说
结尾,一个高频插入的系统,在每种数据库的插入设计的时候,对HOT表都要有严格的要求,从表的设计,主键的设计,表插入行的方式设计,索引的设计,都要有考量,如果 在高频系统中出现 insert into select 这样的语句,大方向我是不对其看好的。因为插入的时候,有的数据库系统是会对表的插入也要加锁 类似 next-key lock 这样的锁。
关于Insert的性能为啥这么差问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4582201/blog/4582479



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



