这篇文章给大家介绍如何进行MYSQL MGR崩溃后的修复和问题查找,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
MYSQL 的 GROUP REPLICATION 估计大多数的公司都没有用,即使用也不是在主要的项目和关键的地方。所以网上相关MYSQL Group Replicaiton 的的修复的东西也不多。赶巧,最近我们的测试系统的 MGR 崩溃了。
我们的MGR 的测试系统是三台MYSQL 5.7.23 + Proxysql 组成的,曾经坏过一台机器(网络原因),但MGR 稳稳的提供数据库服务,这次的崩溃和上次比,没有那么简单。三台机器挂了两台。其实和监控不到位有关,但因为是测试机,也都没有上什么监控,才有了本次的探索)
从第二台机器上(Secondary)上看primary 机器无法访问,三号机根本就不在member list 中, 三号机,在本机看是ERROR 的状态,主库虽然看似活着,但是已经无法登陆了。
project manager 和 开发都要用这个测试系统,所以分析,解决问题只能要一个字,快。(其实我是想详细的分析一下到底哪里出了问题)。
在保存了错误日志后,我尝试恢复,主库,重启启动后可以登录,并且再次重新运行命令,一般你要重新来过,最好要知道,崩溃中的那个库时最后的主库,然后在那个主库上操作下面的命令。(这点是很重要的和后面的恢复有关)
SET GLOBAL group_replication_bootstrap_group=ON;
start group_replication;
SET GLOBAL group_replication_bootstrap_group=OFF;
在操作命令后主库已经启动了,生成了下面的日志

到第二台机器上进行恢复,
重新执行
CHANGE MASTER TO MASTER_USER='repl', MASTER_PASSWORD='password' FOR CHANNEL 'group_replication_recovery';
SET GLOBAL group_replication_allow_local_disjoint_gtids_join=ON; (此命令在MYSQL 8不在存在)
start group_replication;
SET GLOBAL group_replication_allow_local_disjoint_gtids_join=OFF;
执行完毕后,稍等片刻

两台机器已经恢复了,应该可以正常对外工作了,从proxysql 上已经可以访问到集群了。
目前还差一台机器,但这台机器着实是恢复的过程没有那么简单,在重新将第三台机器添加进集群的过程中,发现问题,
[ERROR] Error reading packet from server for channel 'group_replication_recovery': The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires. (server_errno=1236)
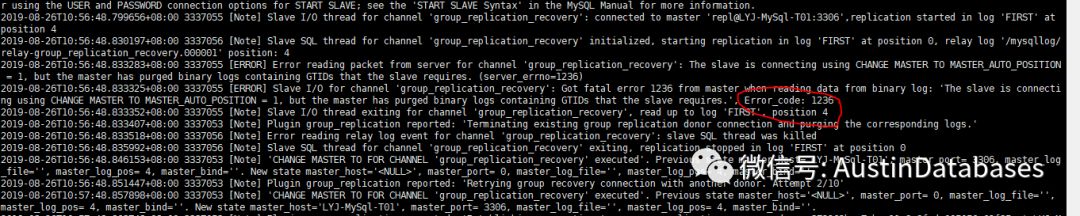
通过这个错误,我至少可以推断出两件事
1 这个服务器想直接加入到集群中,大概率是不大可能了,日志已经跟不上了
2 这个服务器和集群脱离的时间,一定早于集群出现故障的时间。
后面在分析错误日志的过程中,证明了我上面的猜测。
怎么进行恢复这第三台机器,最快速的就是备份后再恢复了,XTRABACKUP 备份了主库后,发现在perpare 的时候非常慢,并且备份的时候,在日志的备份显示中,也是非常的慢,估计里面必有蹊跷。
在恢复的过程中,很奇怪的是,将备份文件恢复到了第三台机器后,提示

在回来翻看曾经的primary 的一号机,的确是crash了

并且 doublewrite 也有问题,有部分数据可能是没有写进去,这也就导致后面恢复第三号机的时候,使用主机的备份导致三号机还是起不来的问题。
后面因为2号机的数据库还是正常的,所以直接resetart 1号MYSQL,下面的图也就是后边备份1号机在备份的时候,和XTRABACKUP PERPARE 的时候异常慢的一个原因。大部分数据要进行UNDO

目前的状况是 1 2 号机都正常启动的情况下,这里还是根据当时的状态,来还让 1号机作为primary (在配置文件中已经设置了MGR的权重), 这里重新操作MGR 初始化的操作就略去了(之前写过MGR 安装的文字),
很快1 和 2 号机,恢复了正常,集群也恢复正常,对外的访问也正常了。
下面回到了最后的3号机怎么恢复的问题,通过备份和恢复,3号机已经正常了,在启动后,3号机自动开始接入到集群中,但结果是失败的,最后在经过10次的尝试,被集群提了出来,错误原因也很简单,就是数据有冲突,我们直接根据备份时候 XTRABAKCUP 文件中的 GTID 信息,直接将
这段GTID PURGED 掉就OK了

再次将三号机加入到集群当中,OK

整体的集群就恢复了。
通过错误日志和相关一些指导来看,大致问题是 3号机由于网络原因已经有一段时间和集群脱离了,而集群不可用的问题,大致是测试人员对系统进行了压测,上面图上也贴出来,清理线程无法将内存的脏页及时刷新到磁盘导致的。但当时具体执行了什么语句,估计是查不到了,后期会考虑安装audit 功能,记录相关的语句,为问题的处理提供更多的信息。
关于如何进行MYSQL MGR崩溃后的修复和问题查找就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4582201/blog/4581703



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



