本篇内容介绍了“CART算法的原理是什么”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
1. CART算法的认识
Classification And Regression Tree,即分类回归树算法,简称CART算法,它是决策树的一种实现,通常决策树主要有三种实现,分别是ID3算法,CART算法和C4.5算法。
CART算法是一种二分递归分割技术,把当前样本划分为两个子样本,使得生成的每个非叶子结点都有两个分支,因此CART算法生成的决策树是结构简洁的二叉树。由于CART算法构成的是一个二叉树,它在每一步的决策时只能是“是”或者“否”,即使一个feature有多个取值,也是把数据分为两部分。在CART算法中主要分为两个步骤
(1)将样本递归划分进行建树过程
(2)用验证数据进行剪枝
2. CART算法的原理
上面说到了CART算法分为两个过程,其中第一个过程进行递归建立二叉树,那么它是如何进行划分的 ?
设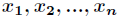 代表单个样本的
代表单个样本的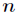 个属性,
个属性,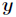 表示所属类别。CART算法通过递归的方式将维的空间划分为不重叠的矩形。
表示所属类别。CART算法通过递归的方式将维的空间划分为不重叠的矩形。
划分步骤大致如下:
(1)选一个自变量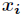 ,再选取的一个值
,再选取的一个值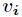 ,把维空间划分为两部分,一部分的所有点都满足
,把维空间划分为两部分,一部分的所有点都满足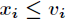 ,另一部分的所有点都满足
,另一部分的所有点都满足 ,对非连续变量来说属性值的取值只有两个,即等于该值或不等于该值。
,对非连续变量来说属性值的取值只有两个,即等于该值或不等于该值。
(2)递归处理,将上面得到的两部分按步骤(1)重新选取一个属性继续划分,直到把整个维空间都划分完。
在划分时候有一个问题,它是按照什么标准来划分的 ? 对于一个变量属性来说,它的划分点是一对连续变量属性值的中点。假设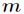 个样本的集合一个属性有个连续的值,那么则会有
个样本的集合一个属性有个连续的值,那么则会有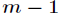 个分裂点,每个分裂点为相邻两个连续值的均值。每个属性的划分按照能减少的杂质的量来进行排序,而杂质的减少量定义为划分前的杂质减去划分后的每个节点的杂质量划分所占比率之和。而杂质度量方法常用Gini指标,假设一个样本共有
个分裂点,每个分裂点为相邻两个连续值的均值。每个属性的划分按照能减少的杂质的量来进行排序,而杂质的减少量定义为划分前的杂质减去划分后的每个节点的杂质量划分所占比率之和。而杂质度量方法常用Gini指标,假设一个样本共有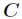 类,那么一个节点
类,那么一个节点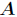 的Gini不纯度可定义为
的Gini不纯度可定义为
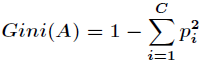
其中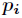 表示属于
表示属于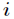 类的概率,当Gini(A)=0时,所有样本属于同类,所有类在节点中以等概率出现时,Gini(A)最大化,此时
类的概率,当Gini(A)=0时,所有样本属于同类,所有类在节点中以等概率出现时,Gini(A)最大化,此时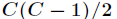 。
。
有了上述理论基础,实际的递归划分过程是这样的:如果当前节点的所有样本都不属于同一类或者只剩下一个样本,那么此节点为非叶子节点,所以会尝试样本的每个属性以及每个属性对应的分裂点,尝试找到杂质变量最大的一个划分,该属性划分的子树即为最优分支。
下面举个简单的例子,如下图
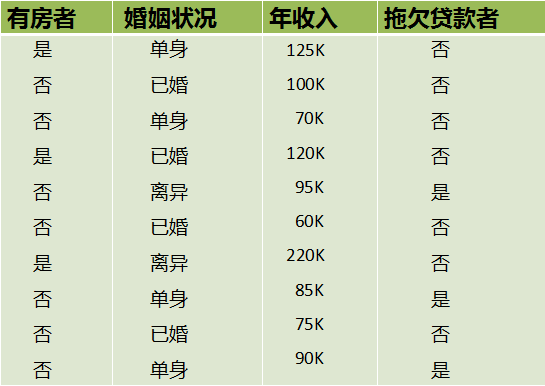
在上述图中,属性有3个,分别是有房情况,婚姻状况和年收入,其中有房情况和婚姻状况是离散的取值,而年收入是连续的取值。拖欠贷款者属于分类的结果。
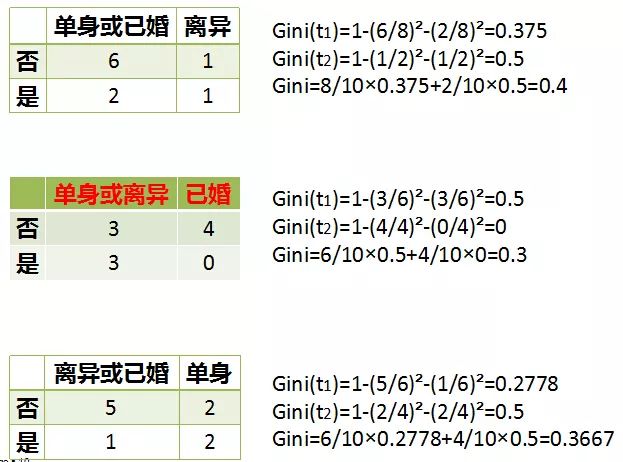
假设现在来看有房情况这个属性,那么按照它划分后的Gini指数计算如下
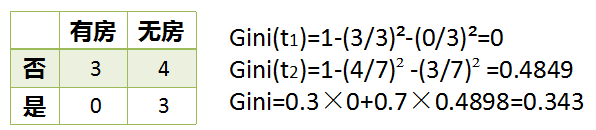
而对于婚姻状况属性来说,它的取值有3种,按照每种属性值分裂后Gini指标计算如下
最后还有一个取值连续的属性,年收入,它的取值是连续的,那么连续的取值采用分裂点进行分裂。如下
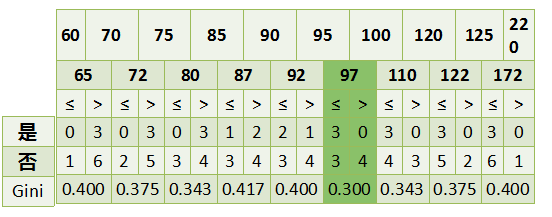
根据这样的分裂规则CART算法就能完成建树过程。
建树完成后就进行第二步了,即根据验证数据进行剪枝。在CART树的建树过程中,可能存在Overfitting,许多分支中反映的是数据中的异常,这样的决策树对分类的准确性不高,那么需要检测并减去这些不可靠的分支。决策树常用的剪枝有事前剪枝和事后剪枝,CART算法采用事后剪枝,具体方法为代价复杂性剪枝法。
“CART算法的原理是什么”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





