本篇文章为大家展示了R语言抓取网站数据,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
今天看到有人用Python爬取了链家网成都站的楼盘信息,我尝试用R做了同样的事情,具体代码如下:
library(rvest)
url0 <- 'http://cd.fang.lianjia.com/loupan/'
name=area=price=type=address=status=NULL
for(i in 1:10)
{
url <- paste(url0,"pg",i,sep = '')
web <- read_html(url)
name <- c(name,web %>% html_nodes('div.info-panel') %>%
html_nodes('a') %>% html_text())
address <- c(address,web %>% html_nodes('div.info-panel') %>%
html_nodes('div.where') %>% html_nodes('span.region') %>%
html_text())
b=web %>% html_nodes('div.info-panel') %>% html_nodes('div.area')
are=rep(0,length(b))
for (i in 1:length(b))
{
if (str_length(b[i]) > 60){
are[i] = b[i]%>% html_nodes('span') %>% html_text()
}else{
are[i] = 0
}
}
area=c(area,ifelse(are=='0','0',unlist(str_extract(are,'[0-9]+~[0-9]+|[0-9]+'))))
a <- web %>% html_nodes('div.info-panel') %>% html_nodes('div.average')
price=rep(0,length(a))
for (i in 1:length(a))
{
if (str_length(a[i]) > 100){
price[i] = a[i]%>% html_nodes('span.num') %>% html_text()
}else{
price[i] = 0
}
}
price=c(price,price)
type <-c(type, web %>% html_nodes('div.info-panel') %>%
html_nodes('div.type') %>% html_nodes('span.live') %>% html_text())
status <-c(status, web %>% html_nodes('div.info-panel') %>%
html_nodes('div.type') %>% html_nodes('span.onsold') %>% html_text())
}
data=data.frame(name,address,area,price=as.numeric(price),type,status)
DT::datatable(data)
部分结果如下

然后又爬取了北京、上海、深圳、广州等17个城市的新建楼盘,然后进行了分析
#雷达图

#绘制面积图
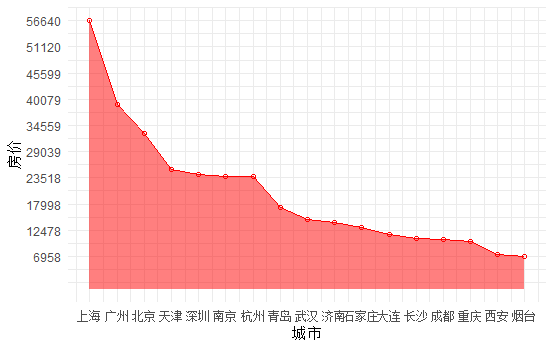
##条形图
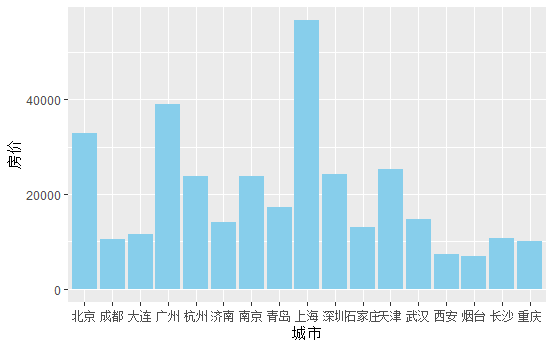
##层次聚类
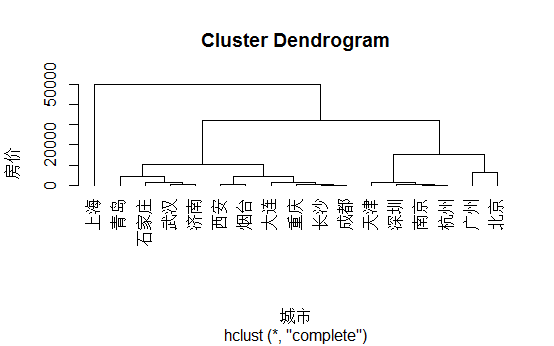
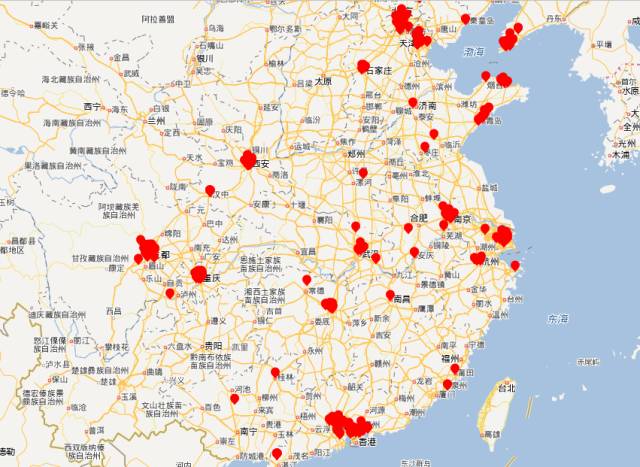
##楼盘在哪里(有些坐标可能有误,但总体趋势还行)
上述内容就是R语言抓取网站数据,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





