这篇文章主要讲解了“fastText和GloVe怎么使用”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“fastText和GloVe怎么使用”吧!
数据包括7613条tweet(Text列)和label(Target列),不管他们是否在谈论真正的灾难。有3271行通知实际灾难,有4342行通知非实际灾难。

文本中真实灾难词的例子:
“ Forest fire near La Ronge Sask. Canada “
使用灾难词而不是关于灾难的例子:
“These boxes are ready to explode! Exploding Kittens finally arrived! gameofkittens #explodingkittens”
数据将被分成训练(6090行)和测试(1523行)集,然后进行预处理。我们将只使用文本列和目标列。
from sklearn.model_selection import train_test_split
data = pd.read_csv('train.csv', sep=',', header=0)
train_df, test_df = train_test_split(data, test_size=0.2, random_state=42, shuffle=True)此处使用的预处理步骤:
小写
清除停用词
标记化
from sklearn.utils import shuffle
raw_docs_train = train_df['text'].tolist()
raw_docs_test = test_df['text'].tolist()
num_classes = len(label_names)
processed_docs_train = []
for doc in tqdm(raw_docs_train):
tokens = word_tokenize(doc)
filtered = [word for word in tokens if word not in stop_words]
processed_docs_train.append(" ".join(filtered))
processed_docs_test = []
for doc in tqdm(raw_docs_test):
tokens = word_tokenize(doc)
filtered = [word for word in tokens if word not in stop_words]
processed_docs_test.append(" ".join(filtered))
tokenizer = Tokenizer(num_words=MAX_NB_WORDS, lower=True, char_level=False)
tokenizer.fit_on_texts(processed_docs_train + processed_docs_test)
word_seq_train = tokenizer.texts_to_sequences(processed_docs_train)
word_seq_test = tokenizer.texts_to_sequences(processed_docs_test)
word_index = tokenizer.word_index
word_seq_train = sequence.pad_sequences(word_seq_train, maxlen=max_seq_len)
word_seq_test = sequence.pad_sequences(word_seq_test, maxlen=max_seq_len)使用fastText和Glove的第一步是下载每个预训练过的模型。我使用google colab来防止我的笔记本电脑使用大内存,所以我用request library下载了它,然后直接在notebook上解压。
我使用了两个词嵌入中最大的预训练模型。fastText模型给出了200万个词向量,而GloVe给出了220万个单词向量。
import requests, zipfile, io
zip_file_url = “https://dl.fbaipublicfiles.com/fasttext/vectors-english/wiki-news-300d-1M.vec.zip"
r = requests.get(zip_file_url)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall()import requests, zipfile, io
zip_file_url = “http://nlp.stanford.edu/data/glove.840B.300d.zip"
r = requests.get(zip_file_url)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall()FastText提供了加载词向量的格式,需要使用它来加载这两个模型。
embeddings_index = {}
f = codecs.open(‘crawl-300d-2M.vec’, encoding=’utf-8')
# Glove
# f = codecs.open(‘glove.840B.300d.txt’, encoding=’utf-8')
for line in tqdm(f):
values = line.rstrip().rsplit(‘ ‘)
word = values[0]
coefs = np.asarray(values[1:], dtype=’float32')
embeddings_index[word] = coefs
f.close()采用嵌入矩阵来确定训练数据中每个词的权重。
但是有一种可能性是,有些词不在向量中,比如打字错误、缩写或用户名。这些单词将存储在一个列表中,我们可以比较处理来自fastText和GloVe的词的性能
words_not_found = []
nb_words = min(MAX_NB_WORDS, len(word_index)+1)
embedding_matrix = np.zeros((nb_words, embed_dim))
for word, i in word_index.items():
if i >= nb_words:
continue
embedding_vector = embeddings_index.get(word)
if (embedding_vector is not None) and len(embedding_vector) > 0:
embedding_matrix[i] = embedding_vector
else:
words_not_found.append(word)
print('number of null word embeddings: %d' % np.sum(np.sum(embedding_matrix, axis=1) == 0))fastText上的null word嵌入数为9175,GloVe 上的null word嵌入数为9186。
你可以对超参数或架构进行微调,但我将使用非常简单的一个架构,它包含嵌入层、LSTM层、Dense层和Dropout层。
from keras.layers import BatchNormalization
import tensorflow as tf
model = tf.keras.Sequential()
model.add(Embedding(nb_words, embed_dim, input_length=max_seq_len, weights=[embedding_matrix],trainable=False))
model.add(Bidirectional(LSTM(32, return_sequences= True)))
model.add(Dense(32,activation=’relu’))
model.add(Dropout(0.3))
model.add(Dense(1,activation=’sigmoid’))
model.summary()
from keras.optimizers import RMSprop
from keras.callbacks import ModelCheckpoint
from tensorflow.keras.callbacks import EarlyStopping
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
es_callback = EarlyStopping(monitor='val_loss', patience=3)
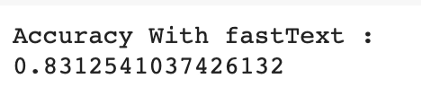
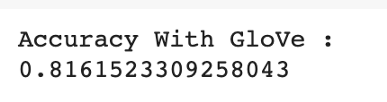
history = model.fit(word_seq_train, y_train, batch_size=256, epochs=30, validation_split=0.3, callbacks=[es_callback], shuffle=False)fastText的准确率为83%,而GloVe的准确率为81%。与没有词嵌入的模型(68%)的性能比较,可以看出词嵌入对性能有显著的影响。
fastText 嵌入的准确度
GloVe 嵌入的准确度
没有词嵌入的准确度

感谢各位的阅读,以上就是“fastText和GloVe怎么使用”的内容了,经过本文的学习后,相信大家对fastText和GloVe怎么使用这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4253699/blog/4563715



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



