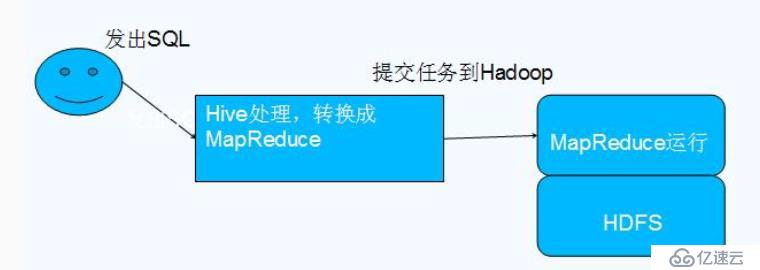
直接使用 MapReduce 所面临的问题:
1、人员学习成本太高
2、项目周期要求太短
3、MapReduce实现复杂查询逻辑开发难度太大
为什么要使用 Hive:
1、更友好的接口:操作接口采用类 SQL 的语法,提供快速开发的能力
2、更低的学习成本:避免了写 MapReduce,减少开发人员的学习成本
3、更好的扩展性:可自由扩展集群规模而无需重启服务,还支持用户自定义函数
1、可扩展性,横向扩展,Hive 可以自由的扩展集群的规模,一般情况下不需要重启服务 横向扩展:通过分担压力的方式扩展集群的规模 纵向扩展:一台服务器cpu i7-6700k 4核心8线程,8核心16线程,内存64G => 128G
2、延展性,Hive 支持自定义函数,用户可以根据自己的需求来实现自己的函数
3、良好的容错性,可以保障即使有节点出现问题,SQL 语句仍可完成执行
1、Hive 不支持记录级别的增删改操作,但是用户可以通过查询生成新表或者将查询结 果导入到文件中(当前选择的 hive-2.3.2 的版本支持记录级别的插入操作)
2、Hive 的查询延时很严重,因为 MapReduce Job 的启动过程消耗很长时间,所以不能 用在交互查询系统中。
3、Hive 不支持事务(因为不没有增删改,所以主要用来做 OLAP(联机分析处理),而 不是 OLTP(联机事务处理),这就是数据处理的两大级别)。
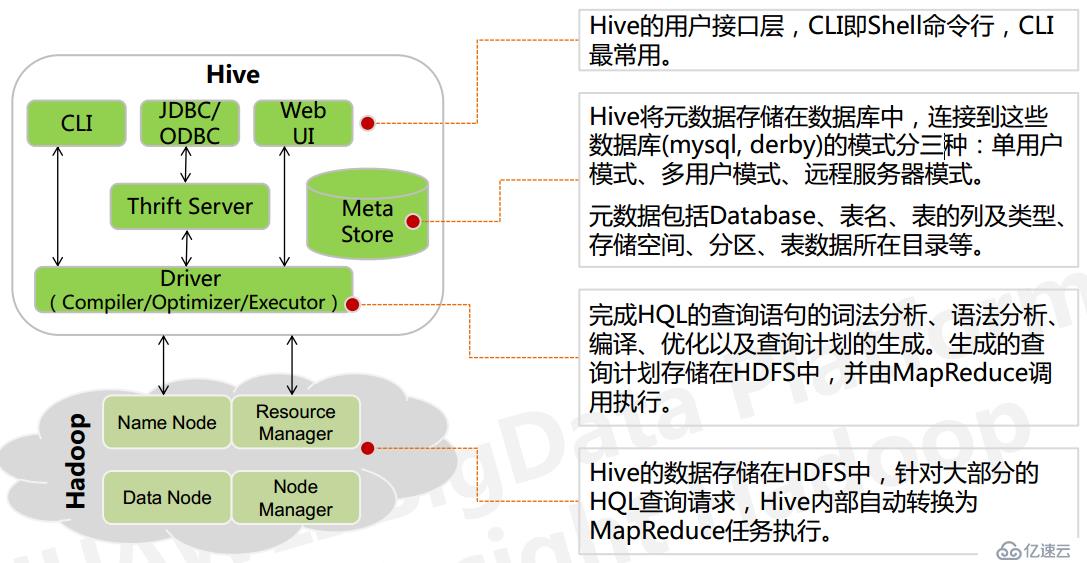
Hive 的元数据存储在 RDBMS 中,除元数据外的其它所有数据都基于 HDFS 存储。默认情 况下,Hive 元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的 测试。实际生产环境中不适用,为了支持多用户会话,则需要一个独立的元数据库,使用 MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。
yum install mariadb-server
启动数据库
systemctl start mariadb
systemctl enable mariadb# 下载安装包
wget https://mirrors.aliyun.com/apache/hive/hive-2.3.3/apache-hive-2.3.3-bin.tar.gz
# 解压安装包
tar xf apache-hive-2.3.3-bin.tar.gz
mv apache-hive-2.3.3-bin /usr/local/hive
# 创建目录
mkdir -p /home/hive/{log,tmp,job}编辑文件/etc/profile.d/hive.sh,修改为如下内容:
# HIVE ENV
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin使HIVE环境变量生效。
source /etc/profile.d/hive.shmysql> grant all privileges on *.* to 'hive'@'%' identified by 'hive123456' with grant option;
mysql> grant all privileges on *.* to 'hive'@'datanode01' identified by 'hive123456' with grant option;
mysql> grant all privileges on *.* to 'thbl_prd_hive'@'%' identified by 'hive123456' with grant option;
mysql> grant all privileges on *.* to 'hive'@'localhost' identified by 'hive123456' with grant option;
mysql> grant all privileges on *.* to 'thbl_prd_hive'@'localhost' identified by 'hive123456' with grant option;
mysql> flush privileges;wget http://mirrors.163.com/mysql/Downloads/Connector-J/mysql-connector-java-5.1.45.tar.gz
tar xf mysql-connector-java-5.1.45.tar.gz
cp mysql-connector-java-5.1.45/mysql-connector-java-5.1.45-bin.jar /usr/local/hive/lib/cd /usr/local/hive/conf
mkdir template
mv *.template template
# 安排配置文件
cp template/hive-exec-log4j2.properties.template hive-exec-log4j2.properties
cp template/hive-log4j2.properties.template hive-log4j2.properties
cp template/hive-default.xml.template hive-default.xml
cp template/hive-env.sh.template hive-env.sh编辑文件/usr/local/hive/conf/hive-env.sh,修改内容如下:
HADOOP_HOME=/usr/local/hadoop
export HIVE_CONF_DIR=/usr/local/hive/conf
export HIVE_AUX_JARS_PATH=/usr/local/hive/lib编辑文件/usr/local/hive/conf/hive-site.xml,修改内容为如下:
<configuration>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hive/job</value>
<description>hive的本地临时目录,用来存储不同阶段的map/reduce的执行计划</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/hive/tmp/${hive.session.id}_resources</value>
<description>hive下载的本地临时目录</description>
</property>
<property>
<name>hive.querylog.location</name>
<value>/home/hive/log/${system:user.name}</value>
<description>hive运行时结构化日志路径</description>
</property>
<property>
<name>hive.hwi.war.file</name>
<value>lib/hive-hwi-2.1.1.war</value>
<description>HWI war文件路径, 与 ${HIVE_HOME}相关. </description>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/home/hive/log/${system:user.name}/operation_logs</value>
<description>日志开启时的,操作日志路径</description>
</property>
<!--远程mysql元数据库-->
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
<description>启动时自动创建必要的schema</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>Hive数据仓库在HDFS中的路径</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://datanode01:9083</value>
<description>远程metastore的 Thrift URI,以供metastore客户端连接metastore服务端</description>
</property>
<!--mysql元数据库配置-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>JDBC驱动名</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://datanode01:3306/hive_db?createDatabaseIfNotExist=true</value>
<description>JDBC连接名</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>连接metastore数据库的用户名</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive123456</value>
<description>连接metastore数据库的密码</description>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>强制metastore schema的版本一致性</description>
</property>
</configuration>scp /usr/local/hive/conf/* datanode01:/usr/local/hive/conf/
chmod 755 /usr/local/hive/conf/*hive --service hiveserver2 &hive --service metastore &[root@namenode01 ~]# jps
14512 NameNode
14786 ResourceManager
21348 RunJar
15894 HMaster
22047 Jps
[root@datanode01 ~]# jps
3509 DataNode
3621 NodeManager
1097 QuorumPeerMain
9930 RunJar
3935 HRegionServer
10063 Jps[root@namenode01 ~]# hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hive/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in file:/usr/local/hive/conf/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive> show tables;
OK
Time taken: 0.833 seconds亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



