本篇内容主要讲解“怎么使用Apache Spark实现分布式随机森林”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“怎么使用Apache Spark实现分布式随机森林”吧!
我们使用公共可用的纽约出租车数据集,并训练一个随机森林回归器,该回归器可以使用与乘客接送相关的属性来预测出租车的票价金额。以2017年、2018年和2019年的出租车出行量为训练集,共计300700143个实例。
Spark集群使用Amazon EMR进行管理,而Dask/RAPIDS集群则使用Saturn Cloud进行管理。
两个集群都有20个工作节点,具有以下AWS实例类型:
Spark:r5.2xlarge
8个CPU,64 GB RAM
按需价格:0.504美元/小时
RAPIDS:g4dn.xlarge
4个CPU,16 GB RAM
1个GPU,16 GB GPU RAM(NVIDIA T4)
按需价格:0.526美元/小时
Saturn Cloud也可以用NVIDIA特斯拉V100 GPU来启动Dask集群,但我们在这个练习中选择了g4dn.xlarge,保持与Spark集群相似的小时成本概况。
Apache Spark是一个在Scala中构建的开源大数据处理引擎,它有一个Python接口,可以调用Scala/JVM代码。
它是Hadoop处理生态系统中的一个重要组成部分,围绕MapReduce范例构建,并且具有用于数据帧和机器学习的接口。
设置Spark集群不在本文的讨论范围之内,但是一旦准备好集群,就可以在Jupyter Notebook中运行以下命令来初始化Spark:
import findspark
findspark.init()
from pyspark.sql import SparkSession
spark = (SparkSession
.builder
.config('spark.executor.memory', '36g')
.getOrCreate())findspark包检测系统上的Spark安装位置;如果可以知道Spark包的安装位置,则可能不需要这样做。
要获得有性能的Spark代码,需要设置几个配置设置,这取决于集群设置和工作流。在这种情况下,我们设置spark.executor.memory以确保我们不会遇到任何内存溢出或Java堆错误。
NVIDIA RAPIDS是一个开源的Python框架,它在gpu而不是cpu上执行数据科学代码。类似于在训练深度学习模型时所看到的,这将为数据科学工作带来巨大的性能提升。
RAPIDS有数据帧、ML、图形分析等接口。RAPIDS使用Dask来处理与具有多个gpu的机器的并行化,以及每个具有一个或多个gpu的机器集群。
设置GPU机器可能有点棘手,但是Saturn Cloud已经为启动GPU集群预构建了映像,所以你只需几分钟就可以启动并运行了!要初始化指向群集的Dask客户端,可以运行以下命令:
from dask.distributed import Client
from dask_saturn import SaturnCluster
cluster = SaturnCluster()
client = Client(cluster)数据文件托管在一个公共的S3 bucket上,因此我们可以直接从那里读取csv。S3 bucket的所有文件都在同一个目录中,所以我们使用s3fs来选择我们想要的文件:
import s3fs
fs = s3fs.S3FileSystem(anon=True)
files = [f"s3://{x}" for x in fs.ls('s3://nyc-tlc/trip data/')
if 'yellow' in x and ('2019' in x or '2018' in x or '2017' in x)]
cols = ['VendorID', 'tpep_pickup_datetime', 'tpep_dropoff_datetime', 'passenger_count', 'trip_distance',
'RatecodeID', 'store_and_fwd_flag', 'PULocationID', 'DOLocationID', 'payment_type', 'fare_amount',
'extra', 'mta_tax', 'tip_amount', 'tolls_amount', 'improvement_surcharge', 'total_amount']使用Spark,我们需要单独读取每个CSV文件,然后将它们组合在一起:
import functools
from pyspark.sql.types import *
import pyspark.sql.functions as F
from pyspark.sql import DataFrame
# 手动指定模式,因为read.csv中的inferSchema非常慢
schema = StructType([
StructField('VendorID', DoubleType()),
StructField('tpep_pickup_datetime', TimestampType()),
...
# 参考notebook获得完整对象模式
])
def read_csv(path):
df = spark.read.csv(path,
header=True,
schema=schema,
timestampFormat='yyyy-MM-dd HH:mm:ss',
)
df = df.select(cols)
return df
dfs = []
for tf in files:
df = read_csv(tf)
dfs.append(df)
taxi = functools.reduce(DataFrame.unionAll, dfs)
taxi.count()使用Dask+RAPIDS,我们可以一次性读取所有CSV文件:
import dask_cudf
taxi = dask_cudf.read_csv(files,
assume_missing=True,
parse_dates=[1,2],
usecols=cols,
storage_options={'anon': True})
len(taxi)我们将根据时间生成一些特征,然后保存数据帧。在这两个框架中,这将执行所有CSV加载和预处理,并将结果存储在RAM中(在RAPIDS的情况下是GPU RAM)。我们将用于训练的特征包括:
features = ['pickup_weekday', 'pickup_hour', 'pickup_minute',
'pickup_week_hour', 'passenger_count', 'VendorID',
'RatecodeID', 'store_and_fwd_flag', 'PULocationID',
'DOLocationID']对于Spark,我们需要将特征收集到向量类中:
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.pipeline import Pipeline
taxi = taxi.withColumn('pickup_weekday', F.dayofweek(taxi.tpep_pickup_datetime).cast(DoubleType()))
taxi = taxi.withColumn('pickup_hour', F.hour(taxi.tpep_pickup_datetime).cast(DoubleType()))
taxi = taxi.withColumn('pickup_minute', F.minute(taxi.tpep_pickup_datetime).cast(DoubleType()))
taxi = taxi.withColumn('pickup_week_hour', ((taxi.pickup_weekday * 24) + taxi.pickup_hour).cast(DoubleType()))
taxi = taxi.withColumn('store_and_fwd_flag', F.when(taxi.store_and_fwd_flag == 'Y', 1).otherwise(0))
taxi = taxi.withColumn('label', taxi.total_amount)
taxi = taxi.fillna(-1)
assembler = VectorAssembler(
inputCols=features,
outputCol='features',
)
pipeline = Pipeline(stages=[assembler])
assembler_fitted = pipeline.fit(taxi)
X = assembler_fitted.transform(taxi)
X.cache()
X.count()对于RAPIDS,我们将所有浮点值转换为float32,以便进行GPU计算:
from dask import persist
from dask.distributed import wait
taxi['pickup_weekday'] = taxi.tpep_pickup_datetime.dt.weekday
taxi['pickup_hour'] = taxi.tpep_pickup_datetime.dt.hour
taxi['pickup_minute'] = taxi.tpep_pickup_datetime.dt.minute
taxi['pickup_week_hour'] = (taxi.pickup_weekday * 24) + taxi.pickup_hour
taxi['store_and_fwd_flag'] = (taxi.store_and_fwd_flag == 'Y').astype(float)
taxi = taxi.fillna(-1)
X = taxi[features].astype('float32')
y = taxi['total_amount']
X, y = persist(X, y)
_ = wait([X, y])
len(X)我们只需要几行代码就可以训练随机森林。
Spark:
from pyspark.ml.regression import RandomForestRegressor
rf = RandomForestRegressor(numTrees=100, maxDepth=10, seed=42)
fitted = rf.fit(X)RAPIDS:
from cuml.dask.ensemble import RandomForestRegressor
rf = RandomForestRegressor(n_estimators=100, max_depth=10, seed=42)
_ = rf.fit(X, y)我们对Spark(CPU)和RAPIDS(GPU)集群上的300700143个纽约出租车数据实例训练了一个随机森林模型。两个集群都有20个工作节点,每小时价格大致相同。以下是工作流每个部分的结果:
| Task | Spark | RAPIDS |
|---|---|---|
| Load/rowcount | 20.6 seconds | 25.5 seconds |
| Feature engineering | 54.3 seconds | 23.1 seconds |
| Random forest | 36.9 minutes | 1.02 seconds |
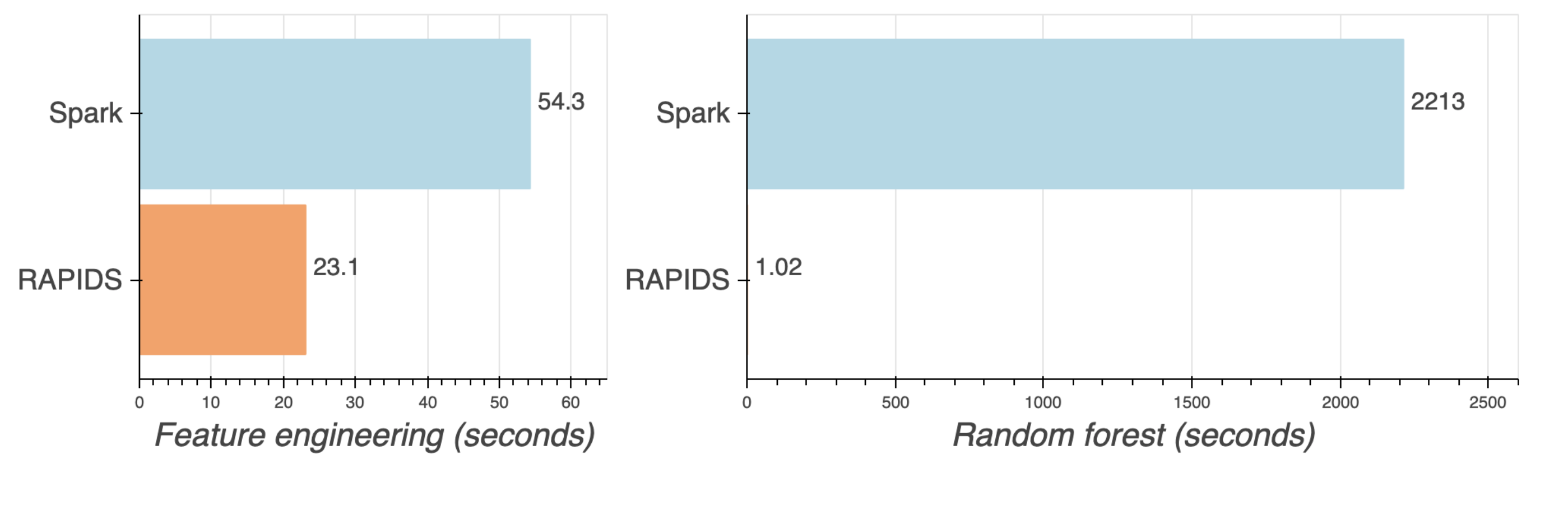
37分钟的Spark 与1秒的RAPIDS!
GPU胜利!想一想,一次拟合你不需要等待37分钟了,这将加快之后迭代和改进模型的速度。而在CPU上,一旦添加了超参数调优或测试不同的模型,迭代都很容易累积到数小时或数天。
到此,相信大家对“怎么使用Apache Spark实现分布式随机森林”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4253699/blog/4539378



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



