这篇文章给大家分享的是有关爬虫中正则表达式怎么用的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
1、正则表达式:学会正则表达式的常用符号
2、re模块:学会python中re模块的使用方法
3、Requests和re模块的组合应用:案例说明
正则表达式:
一般字符:

预定义字符:
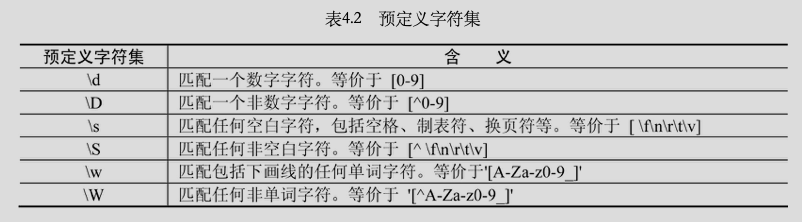
数量词:
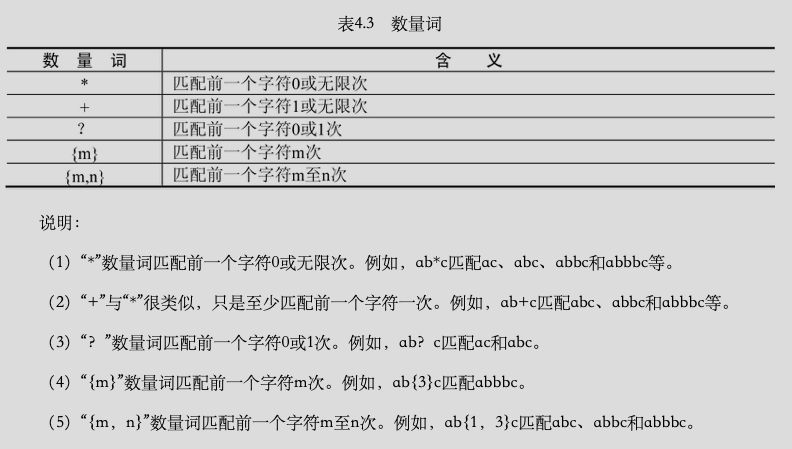
边界匹配:

(.?)括号内容返回结果,.?匹配任意字符
import re
a = 'xxIxxmexxlovexxsffaxxpythonxx'
infos = re.findall('xx(.*?)xx',a)
print(infos)
输出结果:I,love, python
re模块及其方法
search()函数:匹配并提取第一个符合规律的内容,返回一个正则表达式对象
re.match(pattern,string,flags=0)
其中:
(1)pattern为匹配的正则表达式
(2)string为要匹配的字符串
(3)flags为标志位,用于控制正则表达式的匹配方式,如是否区分大小写,多行匹配等
import re
a='one1two2three3'
infos=re.search('\d+',a)
print(infos)
输出:<re.Match object; span=(3, 4), match='1'>
import re
a='one1two2three3'
infos=re.search('\d+',a)
print(infos.group())
输出:1
sub()函数:用于替换字符串中的匹配项
re.sub(pattern,repl,string,count=0,flags=0)
其中:
(1)pattern为匹配的正则表达式
(2)repl为替换的字符串
(3)string为要被查找替换的原始字符串
(4)counts为模式匹配后替换的最大次数,默认0表示替换所有的匹配
(5)flags为标志位,用于控制正则表达式的匹配方式,如是否区分大小写,多行匹配等
import re
phone='123-456-789'
new_phone=re.sub('\D','',phone)
print(new_phone)
输出:123456789
findall()函数:匹配所有符合规律的内容,并以列表的形式返回结果。
import re
a='one1two2three3'
infos2=re.findall('\d+',a)
print(infos2)
输出:['1', '2', '3']

import re
a ='''<div>指数
</div>'''
word = re.findall('<div>(.*?)</div>', a, re.S)
print(word[0].strip())
输出:指数
感谢各位的阅读!关于“爬虫中正则表达式怎么用”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





