这篇“怎么用Python爬取电视剧所有剧情”文章的知识点大部分人都不太理解,所以小编给大家总结了以下内容,内容详细,步骤清晰,具有一定的借鉴价值,希望大家阅读完这篇文章能有所收获,下面我们一起来看看这篇“怎么用Python爬取电视剧所有剧情”文章吧。
【示例代码】
# coding=utf-8# @Auther : 鹏哥贼优秀# @Date : 2019/8/7from bs4 import BeautifulSoupimport requestsimport getheader# 获取每一集对应的标题及对应的界面URL关键地址def get_title():url = "https://www.tvsou.com/storys/0d884ba0dd/"headers = getheader.getheaders()r = requests.get(url, headers=headers)r.encoding = "utf-8"soup = BeautifulSoup(r.text, "lxml")temps = soup.find("ul", class_="m-l14 clearfix episodes-list teleplay-lists").find_all("li")tempurllist = []titlelist = []for temp in temps:tempurl = temp.a.get("href")title = temp.a.get("title")tempurllist.append(tempurl)titlelist.append(title)return tempurllist, titlelist# 下载长安十二时辰的第x集之后所有剧情,默认从第一集开始下载。def Changan(episode=1):tempurllist_b, titlelist_b = get_title()tempurllist = tempurllist_b[(episode - 1):]titlelist = titlelist_b[(episode - 1):]baseurl = "https://www.tvsou.com"for i, tempurl in enumerate(tempurllist):print("正在下载第{0}篇".format(str(i + episode)))url = baseurl + tempurlr = requests.get(url, headers=getheader.getheaders())r.encoding = "utf-8"soup = BeautifulSoup(r.text, "lxml")result = soup.find("pre", class_="font-16 color-3 mt-20 pre-content").find_all("p")content = []for temp in result:if temp.string:content.append(temp.string)with open("test.txt", "a") as f:f.write(titlelist[i] + "\n")f.writelines(content)f.write("\n")if __name__ == "__main__":Changan(43)
【效果如下】

【知识点】
1、怎么自动获取每一集对应的URL地址?
先查看第一集的爬取内容,发现在响应中有一段各剧集的信息,如下图:
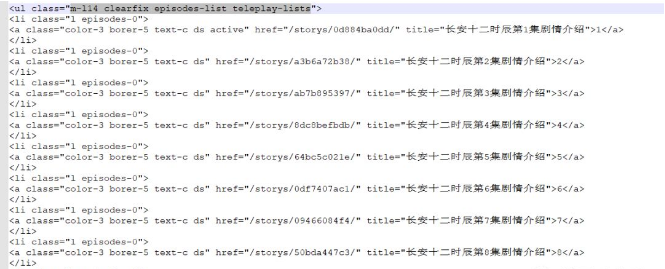
从这段响应消息中可以看到,每一集对应了一个href,然后第一集的URL地址中“https://www.tvsou.com/storys/0d884ba0dd/”刚好有部分URL地址与href一致。然后再验证了下第二集URL,发现的确就是对应的href。因此就得到了如何自动获取各集URL地址的方式。
2、如何爬取每一集的剧情内容呢?
以第一集为例,在响应中可以看到这样一段内容。

在class_="font-16 color-3 mt-20 pre-content"标签内,就有剧情内容。但是由于这段响应中有多个p标签,每个p标签对应一段内容。因此需要对每个p标签进行text提取。并且由于第一个p标签是<p></p>,因此需要进行非空判断。
以上就是关于“怎么用Python爬取电视剧所有剧情”这篇文章的内容,相信大家都有了一定的了解,希望小编分享的内容对大家有帮助,若想了解更多相关的知识内容,请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





