这篇文章主要介绍“怎么用python爬取猫眼电影的前100部影片”,在日常操作中,相信很多人在怎么用python爬取猫眼电影的前100部影片问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”怎么用python爬取猫眼电影的前100部影片”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
import requestsimport refrom bs4 import BeautifulSoupfrom lxml import etreeimport tracebackimport csv#定义一个函数获取豆瓣电影第一页def get_one_page(url,code = 'utf-8'):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36'}try:r = requests.get(url,headers = headers)if r.status_code == 200:r.encoding = codereturn r.textelse:print("相应失败")return Noneexcept:traceback.print_exc()def process(raw):right = raw.split("@")return right[0]def area(a):if a[-1] == ")":return a[16:]else:return Nonedef parse_one_page(slst,html):#正则表达式# rank = re.findall('<dd>.*?<i class="board-index.*?>(\d+)</i>',html,re.S)# img = re.findall('data-src="(.*?)".*?</a>',html,re.S)# name = re.findall('<p class="name".*?><a.*?>(.*?)</a>',html,re.S)# star = re.findall('<p class="star">(.*?)</p>',html,re.S)# time = re.findall('<p class="releasetime">(.*?)</p>',html,re.S)# print(time)#正则表达式别忘了加上r,防止转义,否则会报错# 把上面的正则表达式合在一起pattern = re.compile(r'<dd>.*?<i class="board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?</a>.*?<p class="name".*?><a.*?>(.*?)</a>.*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p>.*?<p class="score"><.*?>(.*?)</i><i class="fraction">(.*?)</i></p>',re.S)items = re.findall(pattern,html)#print(items)for item in items:#yield就相当于return的功能,但也有所不同,yield语句把程序编程迭代器yield {'rank':item[0],'img':process(item[1]),'MovieName':item[2],"star":item[3].strip()[3:],"time":item[4].strip()[5:15],"area":area(item[4].strip()),"score":str(item[5]) + str(item[6])}# return ""def write_to_file(item):with open("猫眼top100.csv",'a',encoding = "utf_8_sig",newline="") as f:#a追加模式 newline区分换行符fieldnames = ['rank','img','MovieName','star','time','area','score']w = csv.DictWriter(f,fieldnames = fieldnames) #字典写入到csv# w.writeheader()w.writerow(item)return ""def down_img(name,url,num):try:response = requests.get(url)with open('C:/Users/HUAWEI/Desktop/py/爬虫/douban/'+name+'.jpg','wb') as f:f.write(response.content)print("第%s张图片下载完毕"%str(num))print("="*20)except Exception as e:print(e.__class__.__name__) #打印错误类型名称def main(i):num = 0url = 'https://maoyan.com/board/4?offset=' + str(i)html = get_one_page(url)#print(html)lst = [] #这个在这里没啥用,但以后若要单独存储某类信息,可是这样写,后面再对应加上函数参数iterator = parse_one_page(lst,html)for a in iterator:#print(a)num += 1write_to_file(a)down_img(a['MovieName'],a['img'],num)# if __name__ == '__main__':# for i in range(10):# main(i)#多线程抓取from multiprocessing import Poolif __name__ == '__main__':pool = Pool()pool.map(main,[i * 10 for i in range(10)])
最终运行结果如下:
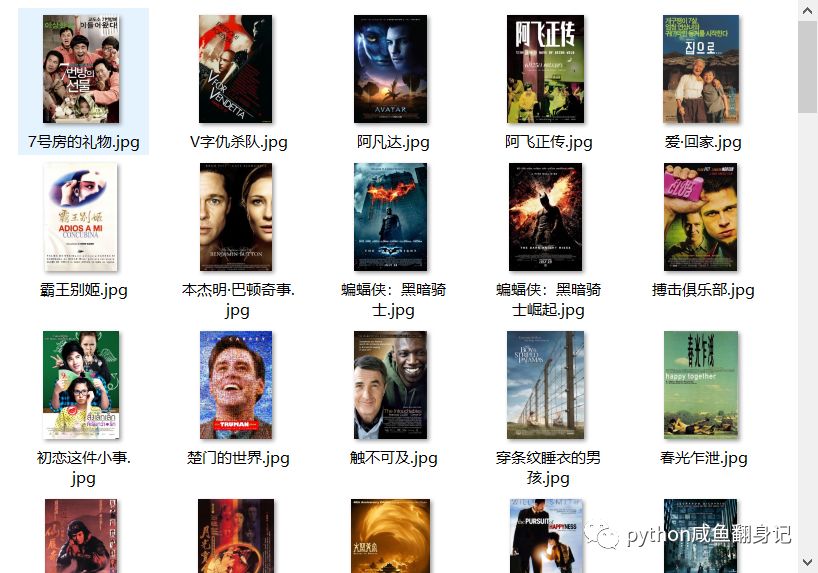
保存封面图片
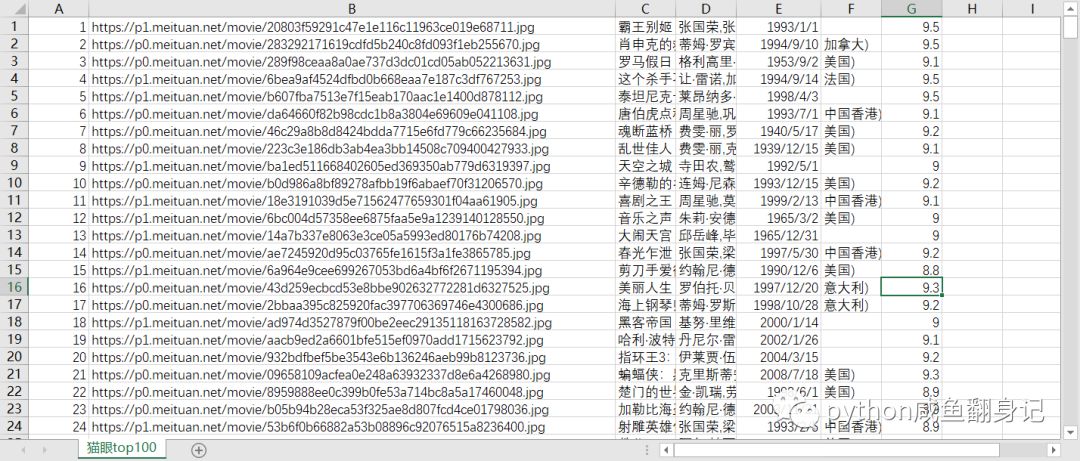
把爬到的信息储存到csv文件中
到此,关于“怎么用python爬取猫眼电影的前100部影片”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





