今天小编给大家分享一下Python非平衡数据问题如何解决的相关知识点,内容详细,逻辑清晰,相信大部分人都还太了解这方面的知识,所以分享这篇文章给大家参考一下,希望大家阅读完这篇文章后有所收获,下面我们一起来了解一下吧。
SMOTE算法的介绍
SMOTE算法的基本思想就是对少数类别样本进行分析和模拟,并将人工模拟的新样本添加到数据集中,进而使原始数据中的类别不再严重失衡。该算法的模拟过程采用了KNN技术,模拟生成新样本的步骤如下:
采样最邻近算法,计算出每个少数类样本的K个近邻;
从K个近邻中随机挑选N个样本进行随机线性插值;
构造新的少数类样本;
将新样本与原数据合成,产生新的训练集;
为了使读者理解SMOTE算法实现新样本的模拟过程,可以参考下图和人工新样本的生成过程:
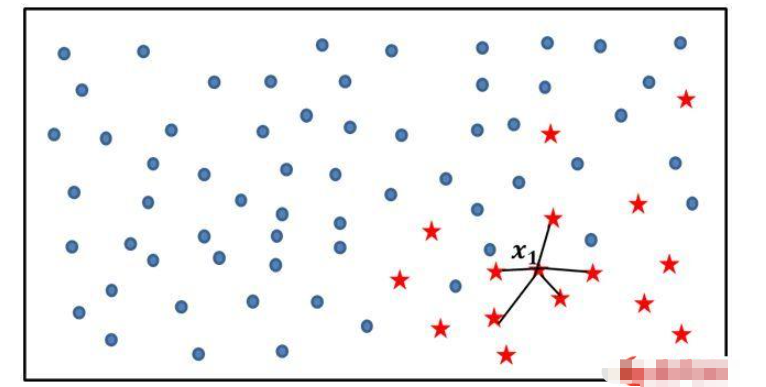
如上图所示,实心圆点代表的样本数量要明显多于五角星代表的样本点,如果使用SMOTE算法模拟增加少类别的样本点,则需要经过如下几个步骤:
利用KNN算法,选择离样本点x1最近的K个同类样本点(不妨最近邻为5);
从最近的K个同类样本点中,随机挑选M个样本点(不妨M为2),M的选择依赖于最终所希望的平衡率;
对于每一个随机选中的样本点,构造新的样本点;新样本点的构造需要使用下方的公式:

其中,xi表示少数类别中的一个样本点(如图中五角星所代表的x1样本);xj表示从K近邻中随机挑选的样本点j;rand(0,1)表示生成0~1之间的随机数。
假设图中样本点x1的观测值为(2,3,10,7),从图中的5个近邻中随机挑选2个样本点,它们的观测值分别为(1,1,5,8)和(2,1,7,6),所以,由此得到的两个新样本点为:

重复步骤1)、2)和3),通过迭代少数类别中的每一个样本xi,最终将原始的少数类别样本量扩大为理想的比例;
通过SMOTE算法实现过采样的技术并不是太难,读者可以根据上面的步骤自定义一个抽样函数。当然,读者也可以借助于imblearn模块,并利用其子模块over_sampling中的SMOTE“类”实现新样本的生成。有关该“类”的语法和参数含义如下:
SMOTE(ratio=’auto’, random_state=None, k_neighbors=5, m_neighbors=10, out_step=0.5, kind=’regular’, svm_estimator=None, n_jobs=1)
ratio:用于指定重抽样的比例,如果指定字符型的值,可以是’minority’,表示对少数类别的样本进行抽样、’majority’,表示对多数类别的样本进行抽样、’not minority’表示采用欠采样方法、’all’表示采用过采样方法,默认为’auto’,等同于’all’和’not minority’;如果指定字典型的值,其中键为各个类别标签,值为类别下的样本量;
random_state:用于指定随机数生成器的种子,默认为None,表示使用默认的随机数生成器;
k_neighbors:指定近邻个数,默认为5个;
m_neighbors:指定从近邻样本中随机挑选的样本个数,默认为10个;
kind:用于指定SMOTE算法在生成新样本时所使用的选项,默认为’regular’,表示对少数类别的样本进行随机采样,也可以是’borderline1’、’borderline2’和’svm’;
svm_estimator:用于指定SVM分类器,默认为sklearn.svm.SVC,该参数的目的是利用支持向量机分类器生成支持向量,然后再生成新的少数类别的样本;
n_jobs:用于指定SMOTE算法在过采样时所需的CPU数量,默认为1表示仅使用1个CPU运行算法,即不使用并行运算功能;
分类算法的应用实战
本次分享的数据集来源于德国某电信行业的客户历史交易数据,该数据集一共包含条4,681记录,19个变量,其中因变量churn为二元变量,yes表示客户流失,no表示客户未流失;剩余的自变量包含客户的是否订购国际长途套餐、语音套餐、短信条数、话费、通话次数等。接下来就利用该数据集,探究非平衡数据转平衡后的效果。
# 导入第三方包 import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn import model_selection from sklearn import tree from sklearn import metrics from imblearn.over_sampling import SMOTE # 读取数据churn = pd.read_excel(r'C:\Users\Administrator\Desktop\Customer_Churn.xlsx') churn.head()

# 中文乱码的处理 plt.rcParams['font.sans-serif']=['Microsoft YaHei'] # 为确保绘制的饼图为圆形,需执行如下代码 plt.axes(aspect = 'equal') # 统计交易是否为欺诈的频数 counts = churn.churn.value_counts() # 绘制饼图 plt.pie(x = counts, # 绘图数据 labels=pd.Series(counts.index).map({'yes':'流失','no':'未流失'}), # 添加文字标签 autopct='%.2f%%' # 设置百分比的格式,这里保留一位小数 ) # 显示图形 plt.show()
如上图所示,流失用户仅占到8.3%,相比于未流失用户,还是存在比较大的差异的。可以认为两种类别的客户是失衡的,如果直接对这样的数据建模,可能会导致模型的结果不够准确。不妨先对该数据构建随机森林模型,看看是否存在偏倚的现象。
原始数据表中的state变量和Area_code变量表示用户所属的“州”和地区编码,直观上可能不是影响用户是否流失的重要原因,故将这两个变量从表中删除。除此,用户是否订购国际长途业务international_plan和语音业务voice_mail_plan,属于字符型的二元值,它们是不能直接代入模型的,故需要转换为0-1二元值。
# 数据清洗 # 删除state变量和area_code变量 churn.drop(labels=['state','area_code'], axis = 1, inplace = True) # 将二元变量international_plan和voice_mail_plan转换为0-1哑变量 churn.international_plan = churn.international_plan.map({'no':0,'yes':1}) churn.voice_mail_plan = churn.voice_mail_plan.map({'no':0,'yes':1}) churn.head()
如上表所示,即为清洗后的干净数据,接下来对该数据集进行拆分,分别构建训练数据集和测试数据集,并利用训练数据集构建分类器,测试数据集检验分类器:
# 用于建模的所有自变量 predictors = churn.columns[:-1] # 数据拆分为训练集和测试集 X_train,X_test,y_train,y_test = model_selection.train_test_split(churn[predictors], churn.churn, random_state=12) # 构建决策树 dt = tree.DecisionTreeClassifier(n_estimators = 300) dt.fit(X_train,y_train) # 模型在测试集上的预测 pred = dt.predict(X_test) # 模型的预测准确率 print(metrics.accuracy_score(y_test, pred)) # 模型评估报告 print(metrics.classification_report(y_test, pred))
如上结果所示,决策树的预测准确率超过93%,其中预测为no的覆盖率recall为97%,但是预测为yes的覆盖率recall却为62%,两者相差甚远,说明分类器确实偏向了样本量多的类别(no)。
# 绘制ROC曲线 # 计算流失用户的概率值,用于生成ROC曲线的数据 y_score = dt.predict_proba(X_test)[:,1] fpr,tpr,threshold = metrics.roc_curve(y_test.map({'no':0,'yes':1}), y_score) # 计算AUC的值 roc_auc = metrics.auc(fpr,tpr) # 绘制面积图 plt.stackplot(fpr, tpr, color='steelblue', alpha = 0.5, edgecolor = 'black') # 添加边际线 plt.plot(fpr, tpr, color='black', lw = 1) # 添加对角线 plt.plot([0,1],[0,1], color = 'red', linestyle = '--') # 添加文本信息 plt.text(0.5,0.3,'ROC curve (area = %0.3f)' % roc_auc) # 添加x轴与y轴标签 plt.xlabel('1-Specificity') plt.ylabel('Sensitivity') # 显示图形 plt.show()如上图所示,ROC曲线下的面积为0.79***UC的值小于0.8,故认为模型不太合理。(通常拿AUC与0.8比较,如果大于0.8,则认为模型合理)。接下来,利用SMOTE算法对数据进行处理:
# 对训练数据集作平衡处理 over_samples = SMOTE(random_state=1234) over_samples_X,over_samples_y = over_samples.fit_sample(X_train, y_train) # 重抽样前的类别比例 print(y_train.value_counts()/len(y_train)) # 重抽样后的类别比例 print(pd.Series(over_samples_y).value_counts()/len(over_samples_y))
如上结果所示,对于训练数据集本身,它的类别比例还是存在较大差异的,但经过SMOTE算法处理后,两个类别就可以达到1:1的平衡状态。下面就可以利用这个平衡数据,重新构建决策树分类器了:
# 基于平衡数据重新构建决策树模型 dt2 = ensemble.DecisionTreeClassifier(n_estimators = 300) dt2.fit(over_samples_X,over_samples_y) # 模型在测试集上的预测 pred2 =dt2.predict(np.array(X_test)) # 模型的预测准确率 print(metrics.accuracy_score(y_test, pred2)) # 模型评估报告 print(metrics.classification_report(y_test, pred2))
如上结果所示,利用平衡数据重新建模后,模型的准确率同样很高,为92.6%(相比于原始非平衡数据构建的模型,准确率仅下降1%),但是预测为yes的覆盖率提高了10%,达到72%,这就是平衡带来的好处。
# 计算流失用户的概率值,用于生成ROC曲线的数据 y_score = rf2.predict_proba(np.array(X_test))[:,1] fpr,tpr,threshold = metrics.roc_curve(y_test.map({'no':0,'yes':1}), y_score) # 计算AUC的值 roc_auc = metrics.auc(fpr,tpr) # 绘制面积图 plt.stackplot(fpr, tpr, color='steelblue', alpha = 0.5, edgecolor = 'black') # 添加边际线 plt.plot(fpr, tpr, color='black', lw = 1) # 添加对角线 plt.plot([0,1],[0,1], color = 'red', linestyle = '--') # 添加文本信息 plt.text(0.5,0.3,'ROC curve (area = %0.3f)' % roc_auc) # 添加x轴与y轴标签 plt.xlabel('1-Specificity') plt.ylabel('Sensitivity') # 显示图形 plt.show()以上就是“Python非平衡数据问题如何解决”这篇文章的所有内容,感谢各位的阅读!相信大家阅读完这篇文章都有很大的收获,小编每天都会为大家更新不同的知识,如果还想学习更多的知识,请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





