在充分利用遍历一次的特点进行优化后,可能我们还会觉得计算性能有点慢,希望有进一步优化的空间。由于每次只需要取出总数据量的很小一部分 (100 个指标涉及的所有科目号大概几百个,即在几百万记录中取几百条),这时我们通常能想到的是:如果能利用数据有序直接进行有序查找(若源数据有序,可以快速定位到这几百条记录,不需要遍历几百万记录甚至更多的数据),将能够获得更好的查询效率。
我们可以利用集算器提供的 iselect() 函数对每个计算的指标进行有序查找,从而减少遍历次数。这里需要注意两个关键点:
1、 iselect()函数用单个主键的查找速度会比用多个主键查找更快,并且写法上也会简单很多。
2、 在数据预处理时,遇到多个主键时应该想办法合并成一个,并且数字化后进行排序,以便使用 iselect() 函数。
关于 iselect() 函数的具体用法和有序计算的解释这里不再赘述,可参考集算器教程的相关章节。
2.4.1 合并主键、排序
为了满足上面提出的两个关键点,我们需要对源数据重新预处理一遍,关于分组计算汇总值、利用跨行组计算累计值等原理上面已经讲过了,这里主要说合并主键和排序。
第一步,在原始数据中,用“年”和“月”两列字段动态计算一个变量值,称为“月号”,以便与“科目”字段合并成唯一主键。代码中相应的改动如下:
A | B | |
1 | =file("总账凭证 -pre.btx") | |
2 | =file("总账凭证 -mid.btx") | |
3 | =A1.cursor@b() | >A3.run(((年 -inityear)*12+ 月): 月 ) |
4 | =A3.groupx(科目, 月:月号;sum(金额): 金额 ) | |
5 | for A4;科目 | =A5.run(金额 = 金额 [-1]+ 金额 ) |
6 | >A2.export@ab(B5,#1:科目,#2: 月号,#3: 累计金额 ) |
其他格子的代码,前面已经解释过了,这里不再赘述。
B3:首先在集算器中定义参数名称:inityear,设置值为 2014,如下图:

假设原始数据是从 2014 年开始的,所以把初始年份的默认值设置为 2014。所谓“月号”就是每条记录的时间是从初始年份 1 月开始的第几个月。比如:当前一条数据记录中年是 2017,月是 3 的话,那么根据这个公式的结果:月号 =(2017-2014)*12+3,也就是 2014 年 1 月开始的第 39 个月。将计算结果利用 run() 函数重新赋值给月字段,以便后面与科目构造唯一主键。
A4:按科目、月号进行分组,金额进行求和(前面已经解释过)
B5:对金额字段进行累计(前面已经解释过)
B6:计算后的结果集以追加的方式保存到集文件中(前面已经解释过),即总账凭证 -mid.btx,执行结果如下图:

第二步,对科目前 N 位分别汇总金额;如何计算多层科目汇总值前面已经讲过了,这里主要关注月号和科目合并成主键 key,然后进行排序。月号计算出来是 2 位(假设数据记录跨度不超过 99 个月),科目为固定的 10 位,这样为了保证合并成主键后的唯一性,需要定义新主键的总长度为 12 位。
这样,新主键的构造规则就是:key(12 位)= 月号 (月号为 2 位)10000000000+ 总账科目 (最长为 10 位)。有一个技巧需要说明一下:这里设定 key 的长度为 12 位,可以存放在一个 long 类型中,如果更长 (与需求有关),就要用字符串了,虽然会相对慢一点,但也影响不大。
集算器的 SPL 脚本如下:
A | |
1 | =file("总账凭证 -mid.btx") |
2 | =file("总账凭证 -later.btx") |
3 | =A1.cursor@b() |
4 | =channel(A3).groupx((科目 \100): 科目, 月号;sum( 累计金额): 累计金额汇总 ) |
5 | =channel(A3).groupx((科目 \10000): 科目, 月号;sum( 累计金额): 累计金额汇总 ) |
6 | =A3.groupx((科目 \1000000): 科目, 月号;sum( 累计金额): 累计金额汇总 ) |
7 | =[A6,A5.result(),A4.result()].conjx() |
8 | =A7.new(#210000000000+#1:key,#3:累计金额汇总 ).sortx(key) |
9 | >A2.export@z(A8) |
A1-A3:前面已经解释过了,这里不再赘述。
A4:创建管道,将游标 A3 中的数据推送到管道,其中 ch.groupx() 函数针对管道中的有序记录分组并返回管道;按科目截取前 8 位、月号进行分组,累计金额进行汇总。返回的数据结构如下图:
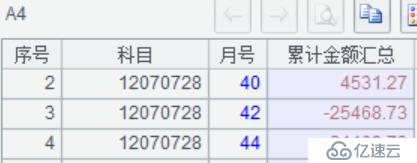
A5:同理于 A4 返回管道,按科目截取前 6 位、月号进行分组,累计金额进行汇总。返回的数据结构如下图:
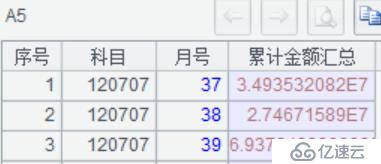
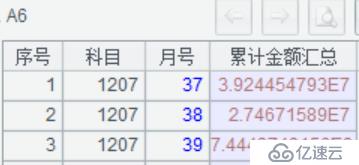
A6:返回游标,按科目截取前 4 位、月号进行分组,累计金额进行汇总。返回的数据结构如下图:
A7:多个游标运算结果合并成一个结果集;其中 ch.result() 代表管道的运算结果
A8:对 A7 的每条记录生成新序表,序表包含两个字段:由月号 (月号为 2 位)10000000000,然后再加上截取后生成的新的科目 (最长为 10 位),重新定义为 key 和累计金额汇总两列字段,接着再对 key 进行排序。
特别说明一下,cs.groupx() 函数按照字段分组后,会对该字段进行排序,也就是说运算后的结果本身就是有序的,所以我们可以利用这个特性,先按月号分组 (写前面),再用 cs.mergex() 函数按照月号、科目做有序归并运算,归并后的结果就不再需要排序了。相应地代码改动如下:
A | |
… | … |
4 | =channel(A3).groupx(月号,(科目 \100): 科目;sum( 累计金额): 累计金额汇总 ) |
5 | =channel(A3).groupx(月号,(科目 \10000): 科目;sum( 累计金额): 累计金额汇总 ) |
6 | =A3.groupx(月号,(科目 \1000000): 科目;sum( 累计金额): 累计金额汇总 ) |
7 | =[A6,A5.result(),A4.result()].mergex(月号, 科目 ) |
8 | =A7.new(#110000000000+#2:key,#3:累计金额汇总 ) |
… | … |
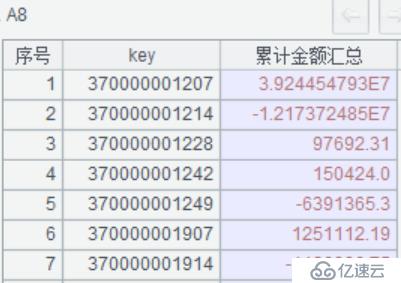
A9:计算后的结果集导出并保存到集文件中,即总账凭证 -later.btx。数据结构如下图:
2.4.2 有序查询
这样,我们就按照要求完成了数据预处理工作,接下来分两步验证报表查询:
1、定义子程序: 任意给定一个计算指标,能够快速返回指标汇总值;然后多次调用子程序来完成 100 个指标的计算,返回结果集。
2、任意给定 100 个计算指标,快速返回与之对应的指标汇总值。
2.4.2.1 多次 ISELECT 查询
首先,定义一个子程序,任意给定一个计算指标(可能只有科目号前面 N 位,比如前 4 位 /6 位 /8 位 /10 位等,自由组合出现),返回这个指标汇总值。
然后,通过调用子程序来完成 100 个指标的计算,先定义查询参数, yyyy 代表查询年,mm 代表查询月,比如:查询 2017 年 1 月的数据,如下图:
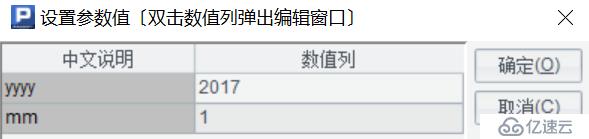
调用子程序的样例:
A | B | C | |
1 | =inityear=2014 | =((yyyy-inityear)*12+mm)10000000000 | =file("总账凭证 -later.btx") |
2 | func | ||
3 | =A2.(B1+) | =B3.sort() | |
4 | =C1.iselect@b(C3,key) | ||
5 | =B4.fetch() | ||
6 | return B5.sum(累计金额汇总 ) | /指标参数列 | |
7 | =func(A2,C7) | [1001,1002] | |
8 | =func(A2,C8) | [2702,153102,12310105,1122,12310101,12310401,12319001,12310201,12310301,12310501,12310601,12310701,12310801,12319101] | |
… | … | … | |
107 | return [A7:A106] |
A1:定义变量 inityear,假定原始数据是从 2014 年开始的,所以设置默认值为 2014;
B1:按照前面相同的规则生成“月号”。如果参数是 2017 年 1 月,执行结果如下:
C1:预处理后的数据文件对象
A2-C6:子程序代码。子程序是以语句 func 为主格的代码块,结果用 return 语句返回。这个子程序主要功能是任意给定一个计算指标,返回汇总值。
B3:接收参数中每一个科目号,利用月号 (月号为 12 位) 加上当前科目号,形成指标的参数集合。比如传入参数为:[1214,1207], 则执行结果如下图:

C3:接着对对指标参数集合 B3 排序。执行结果如下图:

B4:根据指标 C3 中的参数集合与结果集文件中有序的 key 字段进行比对查找,返回游标;其中 @b 代表从集文件中读取。
B5:从游标中获取记录,执行结果如下图:
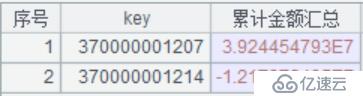
B6:对累计金额汇总求和,返回指标的计算结果。
C7:指标 A 的参数条件 (按科目号前 4 位截取的多个值形成的集合)
C8:指标 B 的参数条件 (按科目号前 4 位 / 前 6 位 / 前 8 位截取的多个值,形成的参数集合) ,剩余的 98 个指标,计算的写法类似 A8,参数的写法类似 C8,依次类推到 100。
A7:调用 func 子程序,把 C7 的指标参数值传入到子程序中,子程序计算后返回结果。
A8:同理,计算指标 B 的结果集
A107:合并 A7-A106 每个格子的值 (从上往下,100 个指标的计算结果),返回一个单列数据集,可以供报表工具使用。
这样做已经可以利用有序查询了,但计算 100 个指标还需要执行 100 次子程序的 iselect() 函数,依然遍历太多,编码过程也比较繁琐。
2.4.2.2 一次 ISELECT 查询
那么,有没有办法只做一次 iselect 查询呢?
答案是有!我们可以把 100 个需要计算的指标的科目号都整理好,然后执行一次 iselect() 函数,把所有指标汇总结果都查找出来,这样,就大功告成了。
这里,需要注意两个关键点:
1、需要将多个计算指标中的不同科目号进行合并、构造主键、排序。
2、利用 pos()的函数技巧,根据每个计算指标中多个科目号与月号构造的主键在结果集中的找到坐标位置 ( 与 key 列字段比对),返回位置序号, 接着根据位置序号在结果集中找到的累计金额汇总字段进行求和,求和结果再按位置序号倒回到每个指标中,即每个指标的汇总值计算完成。
为了便于理解,举个例子,详细解释一下利用 pos() 函数是如何做到定位计算的?示意图如下:

解释:指标 A 和指标 B 的所有科目号合并,然后统一排序生成序号,通过序号在有序结果集中找到对应的金额,再利用位置序号把金额倒回到每个指标中,每个指标下对多个科目号的金额汇总,即指标汇总值。
最终,计算 100 个指标的集算器的 SPL 脚本样例如下:
A | B | C | D | E | |
1 | /参数变量 | =now() | =((yyyy-inityear)*12+mm)*10000000000 | ||
2 | [1001,1002,1012] | [2001] | [1101] | [1121,12310106,12310206,12310306,12310406,12310506,12310606,12310706,12310806,12319006,12319106] | [2101] |
… | … | … | … | … | … |
21 | [221102] | [1221,12310102,12310202,12310302,12310402,12310502,12310602,12310702,12310802,12319002,12319102] | [2221] | [1321,1401,1402,1403,1404,1405,1406,1407,1408,1409,1411,1412,1461,1471] | [1403,147101,1471050100] |
22 | =[A2:E21] | =A22.(.(C1+)) | =A22.union().sort() | ||
23 | =file("总账凭证 -later.btx") | ||||
24 | =A23.iselect@b(C22,key) | =A24.fetch() | =B24.(key) | =B24.(累计金额汇总 ) | |
25 | =A22.(.(C24.pos@b())) | ||||
26 | =A25.(.sum(D24(~))) | ||||
27 | return A26 | =interval@ms(B1,now()) |
A22:把 A2 到 E21 范围内 100 个计算指标的科目号合并起来,其中 A2 格子代表指标 1,B2 代表指标 2,依次类推;合并完后,执行结果如下图:
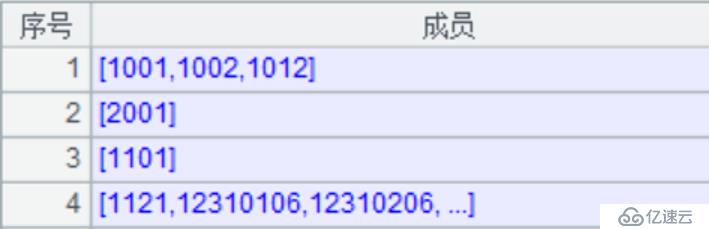
B22:对 A22 指标中每一个科目号,分别利用月号 (月号为 2 位)*10000000000,加上当前科目号,形成指标的参数组集合。执行结果如下图:
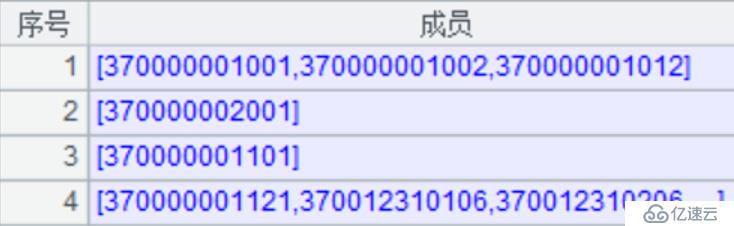
C22:对指标参数组集合进行合并,然后排序

A23:打开预处理后的集文件对象
A24:根据指标 C22 中构造的参数组集合与文件中有序的 key 字段进行比对,记录返回成游标
B24:从游标中获取记录,返回所有科目号的查询到的结果集,执行结果如下图:
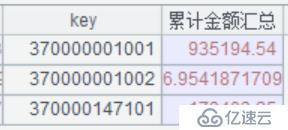
C24-D24:分别获取结果集中的:key、累计金额汇总。
A25:按照 A22 中每个科目号的顺序,在 B24 结果集中利用 key 列与当前科目号 + 月号构造的主键进行比对,然后返回位置序号,其中 pos() 函数中 @b 代表使用二分法查找,效率更高,但要求被寻找序列是有序的。运算结果如下图:

A26:利用 A25 每个成员坐标位置的序号,在结果集 B24 中对比找到的累计金额汇总字段进行求和,求和结果再按位置序号倒回到每个指标中,比如序号 1 返回的结果代表 A2 的参数查询出来的指标 1 汇总结果,序号 2 返回的结果代表 B2 的参数查询出来的指标 2 汇总结果。依次类推。即每个指标的汇总值计算完成。执行结果如下图:
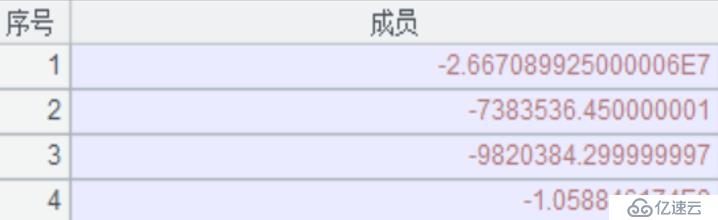
A27:返回结果集,供报表工具使用。
至此,利用一次遍历,搞定所有事情,难题迎刃而解!
实测结果:报表从取数到展现整个环节大概需要1-2秒,其中指标计算部分用时不到1秒。
对于报表的制作过程来说,并不需要做什么改变,只需要把数据源切换到集算器即可。假定报表工具是润乾报表 V5:
首先,导入 excel 表样,创建数据集类型为集算器,选取已经做好的 dfx 脚本;同时设置相应的查询参数等。
然后,在报表的每个单元格里分别按顺序取值,即可得到每个指标汇总结果;比如单元格 C5 的表达式写法:=ds1.select(#1)(1),单元格 C6 的写法:=ds1.select(#1)(2),……,报表单元格表达式从上往下,依次类推。样例如下图:

在实际的报表开发过程中,当我们遇到问题,往往并不能一开始就想到最优的解决办法。我们可以试着先用最简单、最容易的办法实现,然后再一步步进行优化;对比每种方案的存在的缺陷及改进后所带来的性能提升,从而最终满足业务需求。
本文中我们就采用了这种方式,逐步优化的步骤如下:
1、多次遍历方案
2、一次遍历方案
3、预先汇总方案,查询部分在 2 的基础上进行优化
4、有序计算方案
整个过程中,我们用到的集算器相关技术包括:游标、管道、遍历复用、数据外置、分组子集、跨行组计算、有序计算 / 查询、二分法查找、位置序号等。
了解了这些概念并熟练掌握集算器相关的函数后,我们就可以写出高效的代码,快速实现报表数据集的准备工作!
实际业务中,我们针对客户提供的生产环境数据 (原数据表大概 6000 万明细记录),利用这种方案进行了 POC 实测。结果表明,原来需要 30-40 秒才能呈现的资产负债表,现在提高到 1-2 秒内。而且,集算器脚本可以与报表模板一起管理,从而有效降低应用管理的复杂度。
使用集算器进行预处理计算后,形成的数据缓存文件,能够很好的优化现有报表实现模式,有效解决大数据集报表运算慢的难题。
原有模式和引入集算器后的报表系统结构对比如下图所示:

根据报表的业务特点,通常具体的实现步骤如下:
1、集算器抽取来自数据源的数据,根据报表的业务规则,取出需要的维度、过滤字段、计算指标等明细记录。
2、集算器对明细记录进行预处理计算,生成报表需要的各类指标。
3、计算后的指标以数据缓存文件的方式存放,可以按照业务种类、模块关系、时间顺序进行多级目录管理,也可以和报表模板一起管理。
4、报表工具通过 JDBC 方式调用集算器,计算结果返回给报表工具呈现。
5、可以设置计划任务定时执行,完成上述各项数据预处理动作。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





