这篇文章主要讲解了“Kubernetes运维的诉求是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Kubernetes运维的诉求是什么”吧!
K8s 的 CRD Operator 机制非常灵活而强大,不光是复杂应用可以通过编写 CRD Operator 实现,我们的运维能力也大量通过 Operator 来扩展,比如灰度发布、流量管理、弹性扩缩容等等。
我们常常赞叹于 K8s 的灵活性,它让我们基础平台团队对外提供能力非常方便,但是对应用运维来说,他们要使用我们提供的这些运维能力,却变得有些困难。
比如我们上线了一个 CronHPA,可以定时设置在每个阶段会根据 CPU 调整实例数的范围。应用运维并不知道跟原生不带定时功能的 HPA 会产生冲突,而我们也没有一个统一的渠道帮助管理这么多种复杂的扩展能力,结果自然是引起了故障。这血的教训提醒我们要做事前检查,熟悉 K8s 的机制很容易让我们想到为每个 Operator 加上 admission webhook。
这个 admission webhook 需要拿到这个应用绑定的所有运维能力以及应用本身的运行模式,然后做统一的校验。如果这些运维能力都是一方提供的还好,如果存在两方,甚至三方提供的扩展能力,我们就没有一个统一的方式去获知了。
事实上如果我们想的更远一些就会发现,我们需要一个统一的模型来协商并管理这些复杂的扩展能力。
当我们把应用的 Operator 以及对应的运维能力都写好以后,我们很容易想到要打包交付这个应用,这样无论是公有云还是专有云都可以通过一个统一的方式去交互。社区的主流方式目前就是使用 Helm 来打包应用,而我们也采用了这样的方式给我们的用户交付,但是却发现我们的用户需求远不止于此。
云原生应用有一个很大的特点,那就是它往往会依赖云上的资源,包括数据库、网络、负载均衡、缓存等一系列资源。
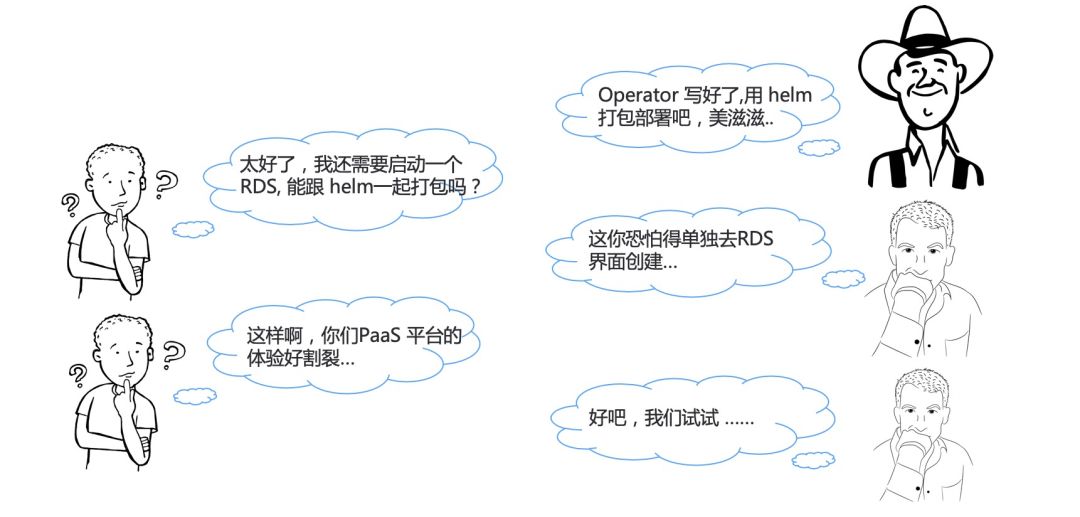
当我们使用 Helm 打包时,我们只能针对 K8s 原生 API,而如果我们还想启动 RDS 数据库,就比较困难了。如果不想去数据库的交互页面,想通过 K8s 的 API 来管理,那就又不得不去写一个 CRD 来定义了,然后通过 Operator 去调用实际云资源的 API。
这一整套交付物实际上就是一个应用的完整描述,即我们所说的“应用定义”。但事实上,我们发现“应用定义”这个东西,在整个云原生社区里其实是缺失的。这也是为什么阿里巴巴内部有很多团队开始尝试设计了自己的“应用定义”。

这种定义方式最终所有的配置还是会全部堆叠到一个文件里,这跟 K8s API all-in-one 的问题其实是一样的,甚至还更严重了。而且,这些应用定义最终也都成为了黑盒,除了对应项目本身可以使用,其他系统基本无法复用,自然就更无法使得多方协作复用了。
事实上几乎每个基于 K8s 管理应用的公司和团队都在自己定义应用。如下所示,我就搜到了两家公司的应用定义:

应用定义实际上是应用交付/分发不可或缺的部分。但是在具体的实践中,我们感受到这些内部的应用定义都面临着如下的问题:
定义是否足够开放,是否可以复用?
如何与开源生态协作?
如何迭代与演进?
这三个问题带来的挑战都是巨大的,我在上文已经提到,一个应用定义需要容易上手,但又不失灵活性,更不能是一个黑盒。应用定义同样需要跟开源生态紧密结合,没有生态的应用定义注定是没有未来的,自然也很难持续的迭代和演进。
 区分使用者的分层模型与模块化的封装
区分使用者的分层模型与模块化的封装
让我们回过头来重新审视我们面临的挑战,归根结底在于 K8s 的 All in One API 是为平台提供者设计的,我们不能像下图左侧显示的一样,让应用的研发、运维跟 K8s 团队一样面对这一团 API。
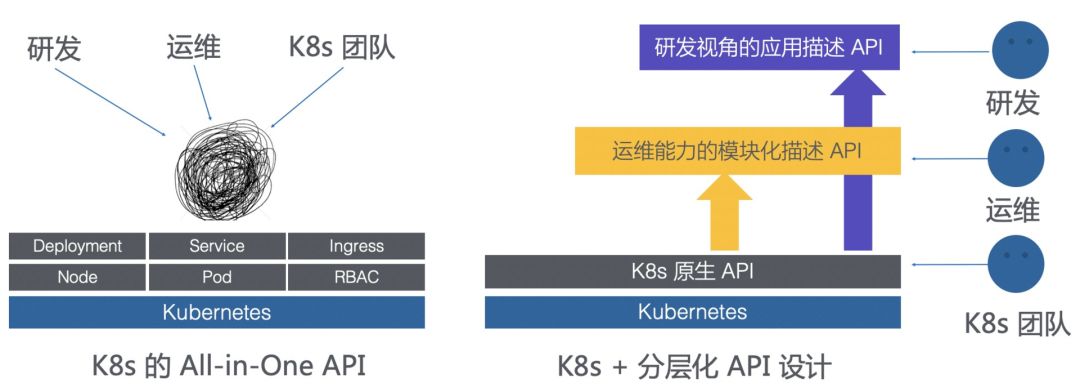
一个合理的应用模型应该具有区分使用者角色的分层结构,同时将运维能力模块化的封装。让不同的角色使用不同的 API,正如上图右侧部分。
感谢各位的阅读,以上就是“Kubernetes运维的诉求是什么”的内容了,经过本文的学习后,相信大家对Kubernetes运维的诉求是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/maxzhang1985/blog/4455847



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



