本文小编为大家详细介绍“怎么快速掌握Python数据采集与网络爬虫技术”,内容详细,步骤清晰,细节处理妥当,希望这篇“怎么快速掌握Python数据采集与网络爬虫技术”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。
一、数据采集与网络爬虫技术简介
网络爬虫是用于数据采集的一门技术,可以帮助我们自动地进行信息的获取与筛选。从技术手段来说,网络爬虫有多种实现方案,如PHP、Java、Python ...。那么用python 也会有很多不同的技术方案(Urllib、requests、scrapy、selenium...),每种技术各有各的特点,只需掌握一种技术,其它便迎刃而解。同理,某一种技术解决不了的难题,用其它技术或方依然无法解决。网络爬虫的难点并不在于网络爬虫本身,而在于网页的分析与爬虫的反爬攻克问题。
二、网络爬虫技术基础
在本文中,将使用Urllib技术手段进行项目的编写。同样,掌握了该技术手段,其他的技术手段也不难掌握,因为爬虫的难点不在于技术手段本身。本知识点包括如下内容:
Urllib基础
浏览器伪装
用户代理池
糗事百科爬虫实战
需要提前具备的基础知识:正则表达式
1)Urllib基础
爬网页
打开python命令行界面,两种方法:ulropen()爬到内存,urlretrieve()爬到硬盘文件。

同理,只需换掉网址可爬取另一个网页内容

上面是将爬到的内容存在内存中,其实也可以存在硬盘文件中,使用urlretrieve()方法
>>> urllib.request.urlretrieve("http://www.jd.com",filename="D:/test.html")
之后可以打开test.html,京东网页就出来了。由于存在隐藏数据,有些数据信息和图片无法显示,可以使用抓包分析进行获取。
2)浏览器伪装
尝试用上面的方法去爬取糗事百科网站url="https://www.qiushibaike.com/",会返回拒绝访问的回复,但使用浏览器却可以正常打开。那么问题肯定是出在爬虫程序上,其原因在于爬虫发送的请求头所导致。
打开糗事百科页面,如下图,通过F12,找到headers,这里主要关注用户代理User-Agent字段。User-Agent代表是用什么工具访问糗事百科网站的。不同浏览器的User-Agent值是不同的。那么就可以在爬虫程序中,将其伪装成浏览器。
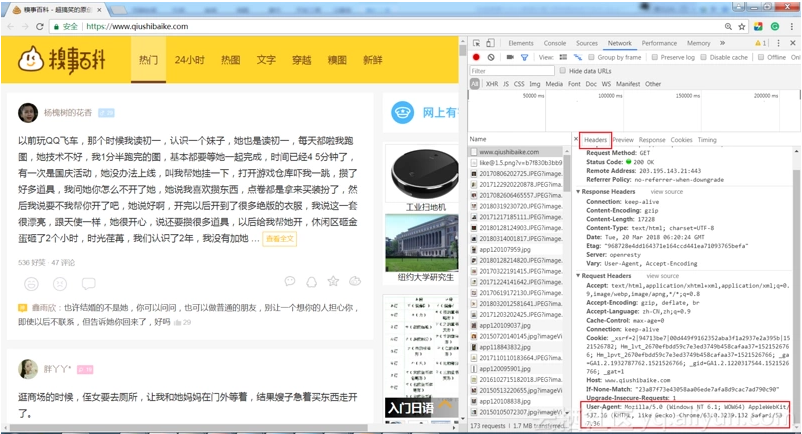
将User-Agent设置为浏览器中的值,虽然urlopen()不支持请求头的添加,但是可以利用opener进行addheaders,opener是支持高级功能的管理对象。代码如下:

3)用户代理池
在爬取过程中,一直用同样一个地址爬取是不可取的。如果每一次访问都是不同的用户,对方就很难进行反爬,那么用户代理池就是一种很好的反爬攻克的手段。
第一步,收集大量的用户代理User-Agent

第二步,建立函数UA(),用于切换用户代理User-Agent
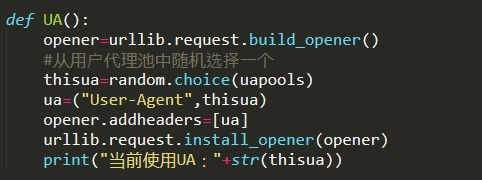
for循环,每访问一次切换一次UA

每爬3次换一次UA
foriinrange(0,10):if(i%3==0): UA() data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
(*每几次做某件事情,利用求余运算)
4)第一项练习-糗事百科爬虫实战
目标网站:https://www.qiushibaike.com/
需要把糗事百科中的热门段子爬取下来,包括翻页之后内容,该如何获取?
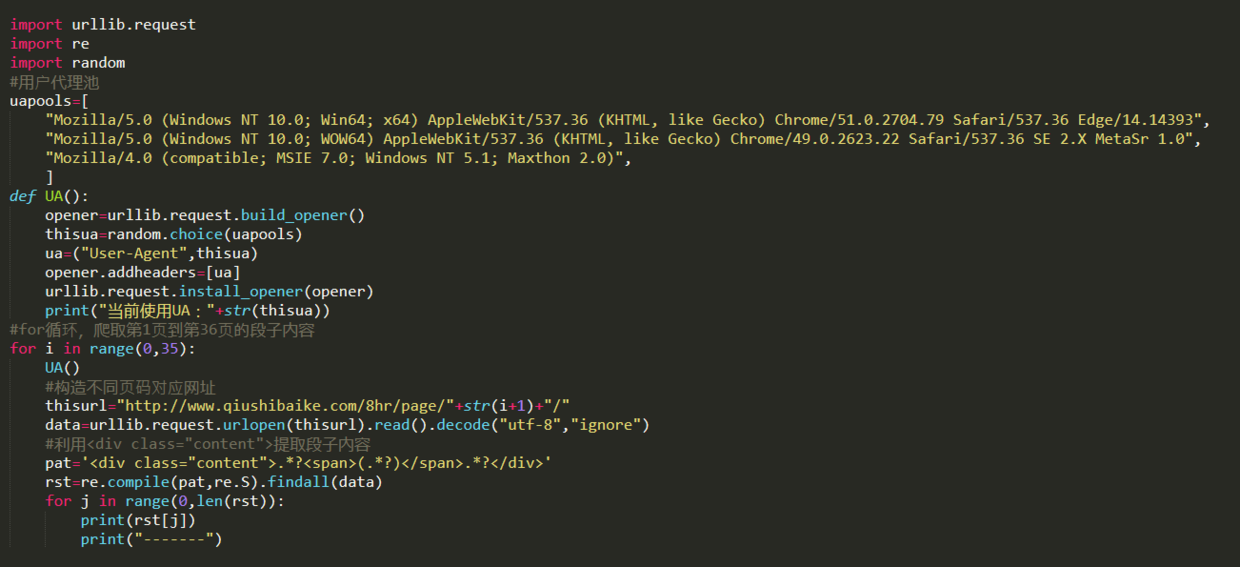
第一步,对网址进行分析,如下图所示,发现翻页之后变化的部分只是page后面的页面数字。
第二步,思考如何提取某个段子?查看网页代码,如下图所示,可以发现<div class="content">的数量和每页段子数量相同,可以用<div class="content">这个标识提取出每条段子信息。

第三步,利用上面所提到的用户代理池进行爬取。首先建立用户代理池,从用户代理池中随机选择一项,设置UA。
读到这里,这篇“怎么快速掌握Python数据采集与网络爬虫技术”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





