今天就跟大家聊聊有关如何进行Pulsar Functions 的深入分析,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
Pulsar Functions 简单介绍
大概运行过程就是在 input topic 中接收消息,进入 functions 中进行运算和消息处理,最后输出到 output topic 中的过程。
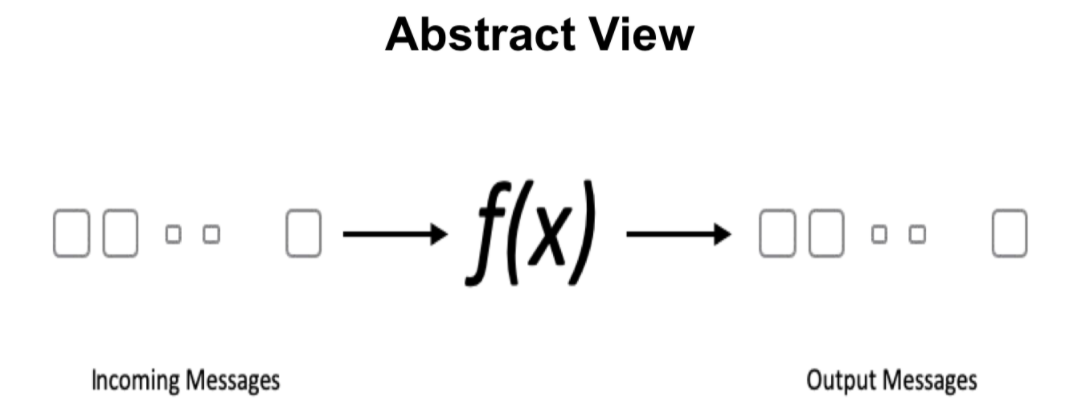
Pulsar Functions 可以覆盖 90% 以上情况的流处理场景。比如:消息过滤、消息路由、消息增强等。更多使用场景可以参考之前发布的技术博客:基于 Pulsar Functions 的事件处理设计模式
Pulsar Functions 主要分为三大模块:Instance、Runtime、Function-worker。
在 Runtime 层面主要支持三种形式:thread、process 和外部支持的 Kubernetes。
更多关于 Pulsar Functions 介绍和基础层源码讲解,可以参考回放视频:01:00-13:20 时间段。
此分享的解析角度,从 functions 内部几个重要节点出发。主要是:如何提交 Pulsar Functions、Functions Worker 如何调度以及如何运行 Pulsar Functions。
在执行/创建一个 function 时,需要通过 `FunctionConfig` 的形式暴露给用户,用户通过指定 `FunctionConfig` 来进行 functions 内部操作。
Functions 可以提交到任意 worker,通过相应的 Json 文件进行相应 tenant/namespace/name 等输入/输出配置的提供。
在配置构建完成后,会有一个 AuthN/AuthZ checks 过程,去检测在配置 function 过程中是否添加了与「加密」相关的设置。之后便会对 `FunctionConfig` 文件内格式以及其他方面进行再次核实。
最终这些 jar 包会存储在 BookKeeper 端,方便后续再次调用。
此时完成以上操作后,submission workflow 会把所有的 functions 提交到 MetaData Topic,并用 map from <FQFN, FunctionMetaData> 格式进行记录。
FQFN 就是 Fully Qualified Function Name,格式就是 tenant、namespace、functions name 三个字段拼合而成。
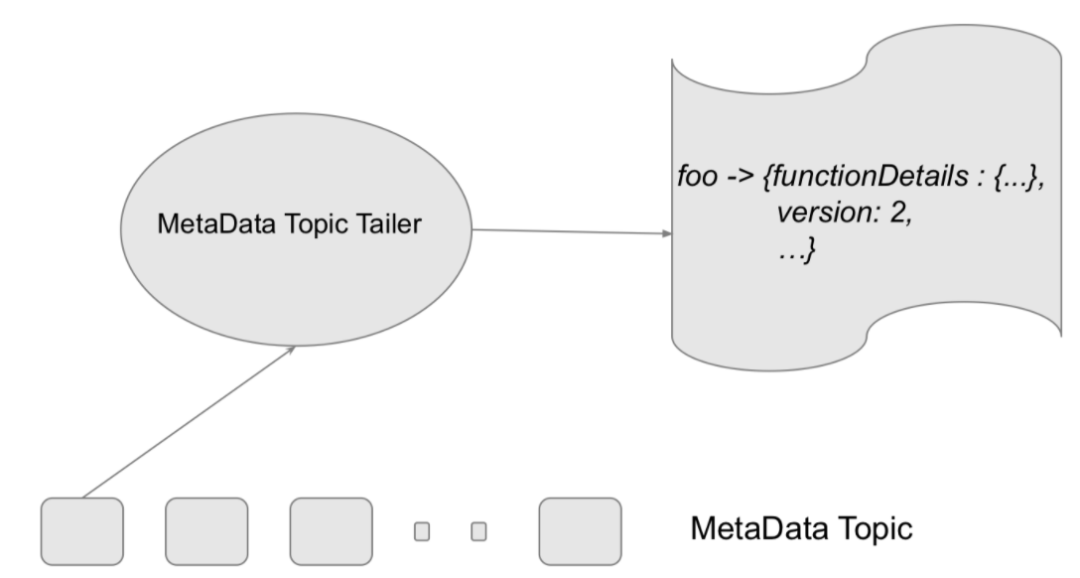
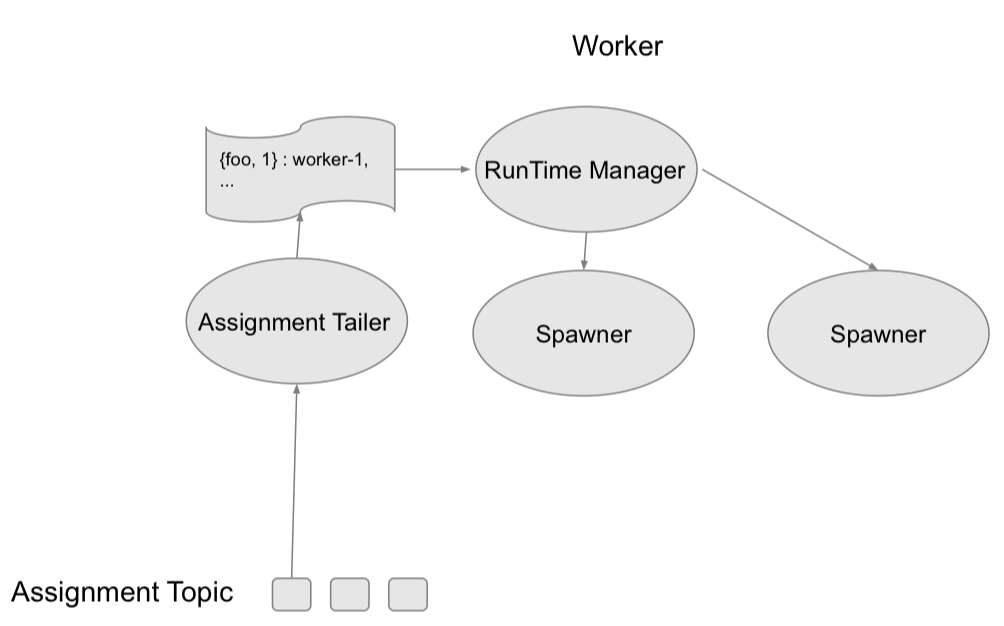
FQFN 作为存储元数据的 key,会把用户提供的 `FunctionConfig` 字段填充到 Function MetaData 中。图中的 MetaData Topic Tailer,主要目的是进行实时监测 MetaData Topic,根据实时更新变化写入等动态,进行后续操作。
在 Functions 内部没有真正开始执行「创建/更新/删除」等操作之前,需要进行状态更新。大体过程为:
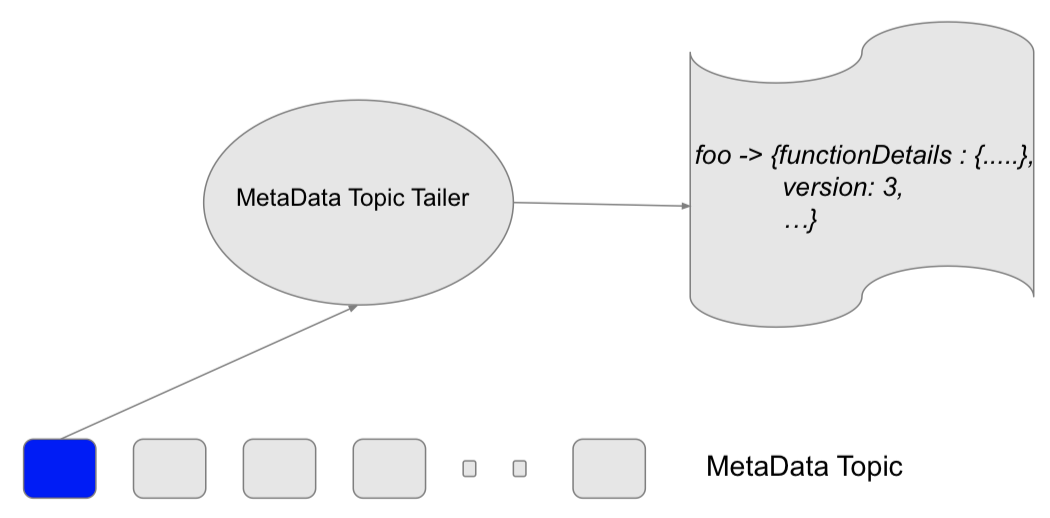
复制当前状态
进行状态合并更新
增加当前版本数
将数据写入 MetaData Topic
Tailer 进行数据读取和验证
如果没有冲突,则整个更新
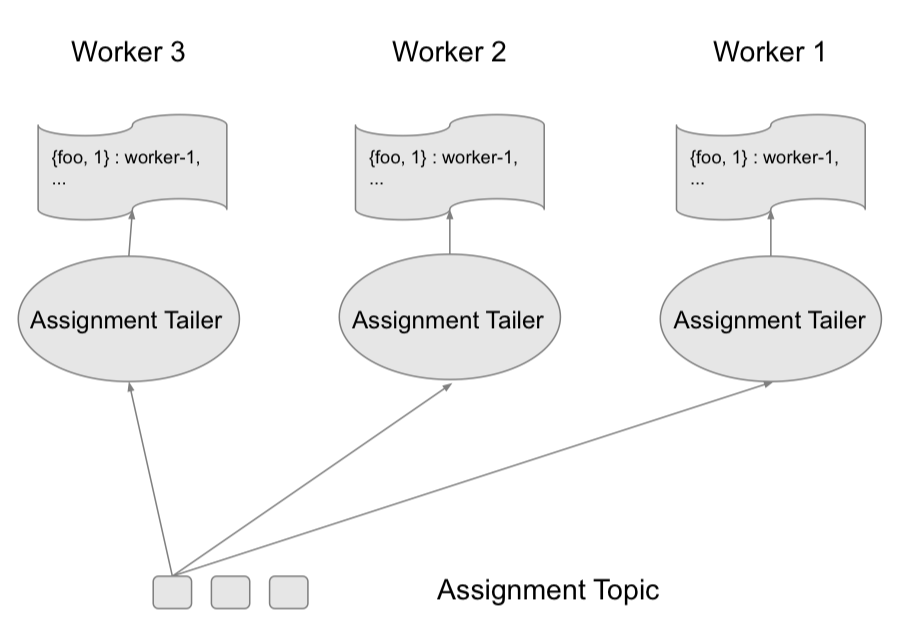
|| Scheduling workflow

CRUD 操作:创建/更新/删除
Worker 变动:如创建新 worker、leadership 发生变化等

|| Execution Workflow
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





