本篇内容介绍了“怎么用python采集网页内容并整合成pdf文件”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
登陆网站:深规院(http://www.upr.cn/)。接下来跟大家一样,我就挨个点击了它的主页。
主页
很自然我就红色4点进去看到了他们的内刊,有段时间我不太爱看文字,评职称我对自己的论文不是很满意,就点进去看看论文了解下最近的规划学术动态也好。于是就有接下来的看图。
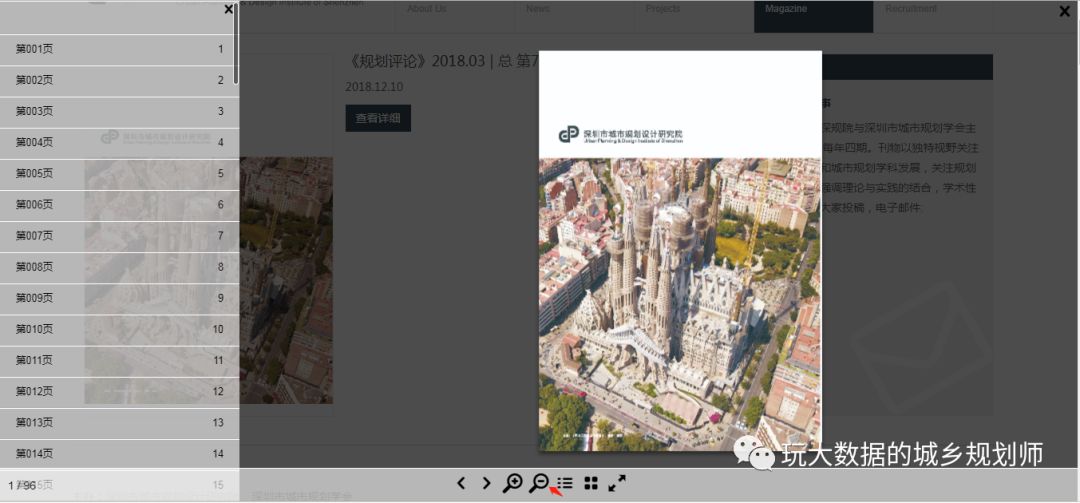
期刊浏览
在看的过程中,发现宝贝了,就是有一篇论文写村庄污水集中跟分散处理的论文,我做过几个村庄整治规划,这方面我一直脑袋空白。

看到它即使再有文字障碍,我也要把他读完。等一等,读完以后还看呢!我去,最近在学爬虫,干确给弄下来。那个什么送长辈,哦错了,送同行看看也好。那就分析下呗。看看是什么格式。
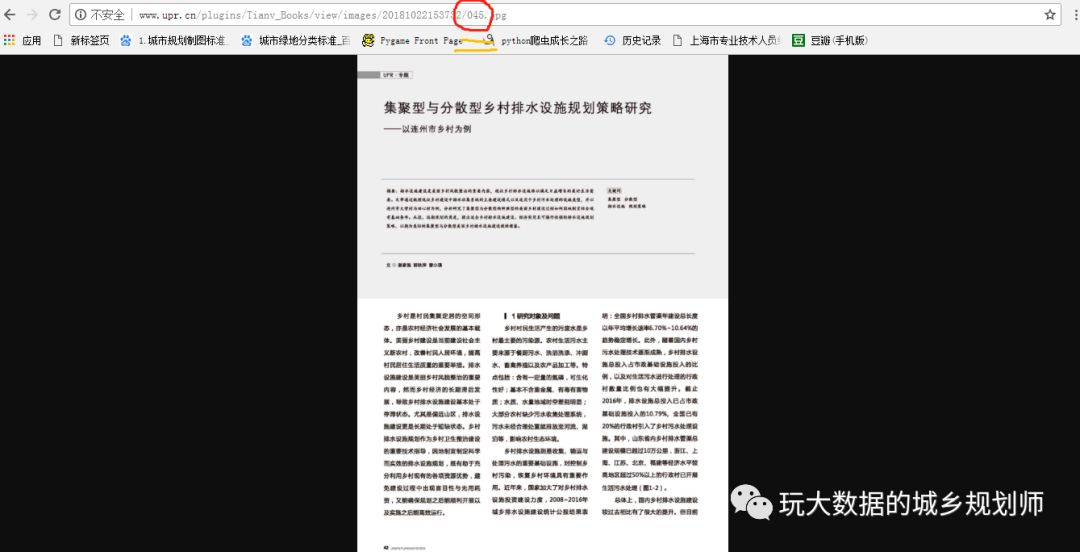
右键复制图片地址得到
看到没有,那个像书一样翻来翻去的,页面变化其实只有网址045在变化。奶思,循环采集图片对于现在的我来说简直是小儿科。用pycharm写几行代码搞定一下。
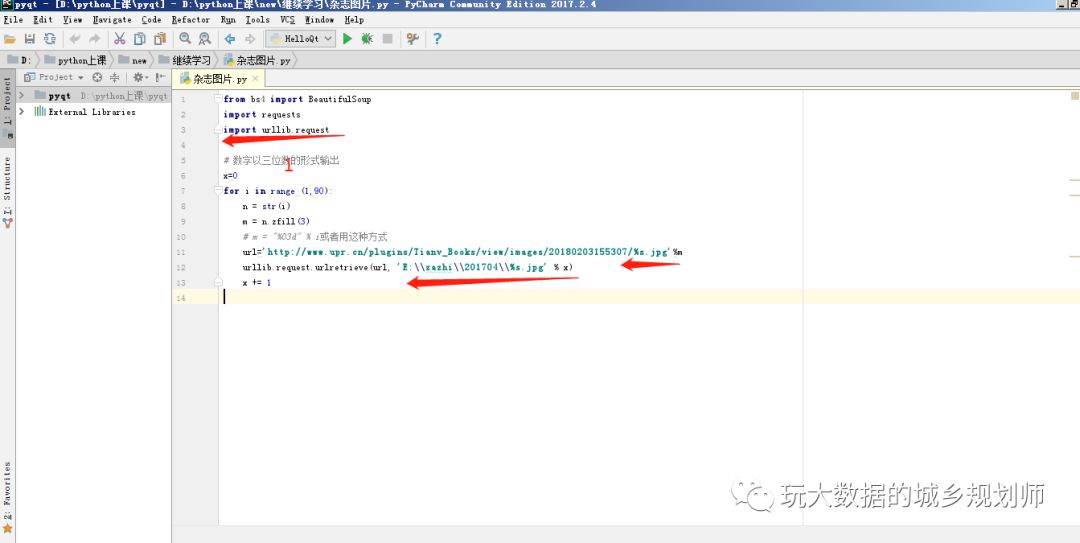
三点注意一下就好:1,导入urllib模块;2,循环变化url;3,设置好保存路径跟保存图片的文件名。接下来就运行py文件呗,要不是我住的地用的移动送的烂网络。总之,如下:
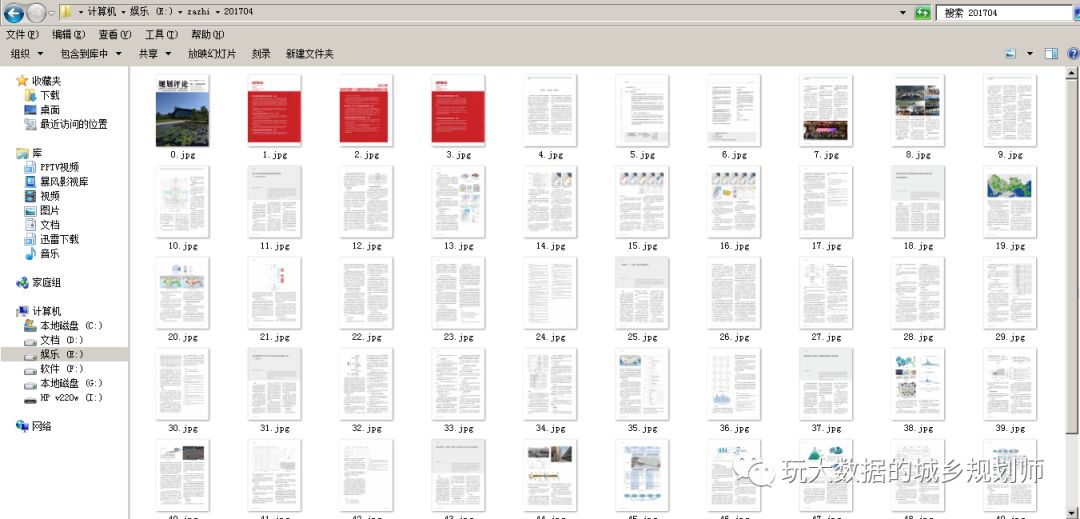
“怎么用python采集网页内容并整合成pdf文件”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





