本篇文章为大家展示了如何进行深层神经网络模型Softmax DNN分析,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
一种可能的DNN模型是softmax,它将问题看作多类预测问题,其中:
输入是用户查询。
输出是一个概率向量,其大小等于语料库中的项目数,表示与每个项目交互的概率; 例如,点击或观看YouTube视频的可能性。
DNN的输入可包括:
密集特征(例如,观看自上次观看以来的时间和时间)
稀疏特征(例如,观看历史记录和国家/地区)
与矩阵分解方法不同,还可以添加年龄或国家区域等侧面特征。这里用x表示输入向量。
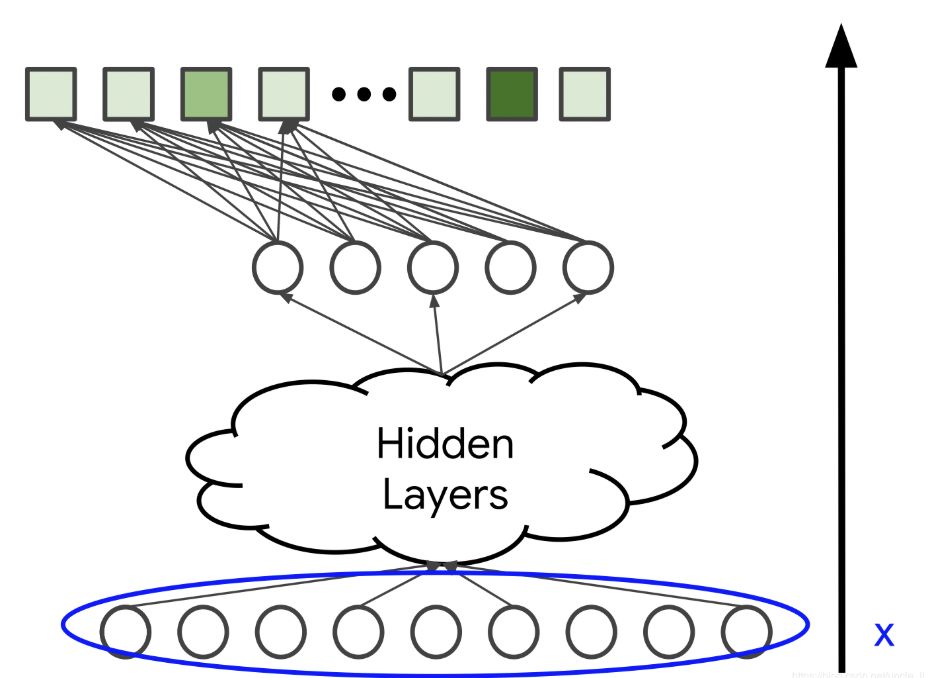
图1.输入层x
模型架构
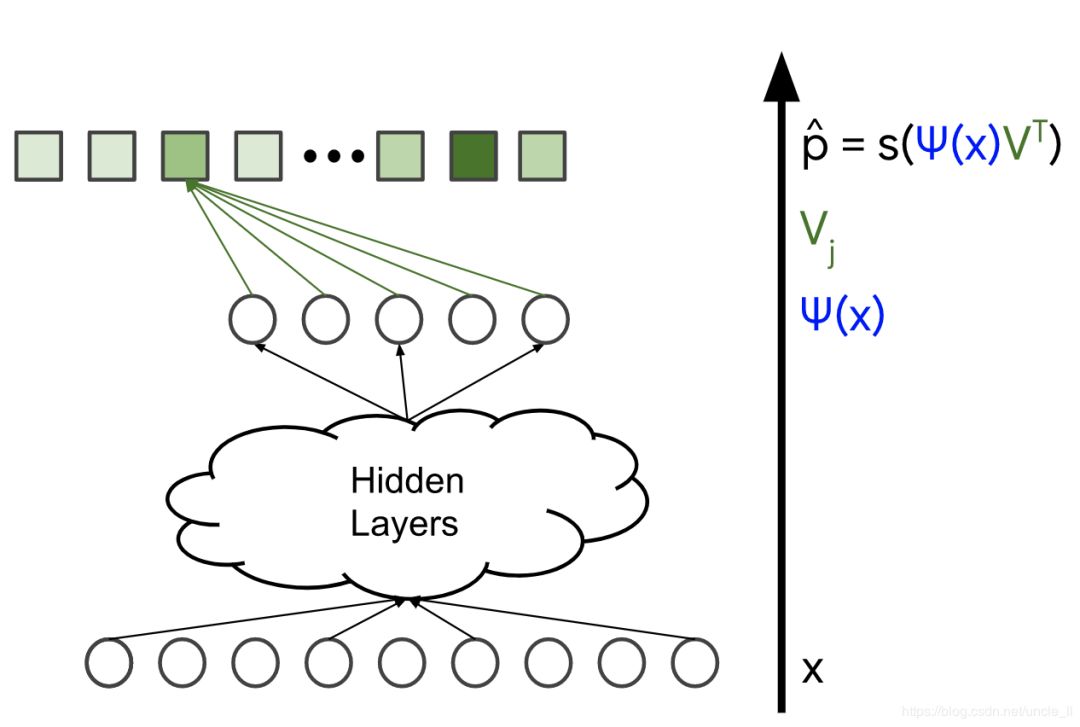
模型架构决定了模型的复杂性和表现力。通过添加隐藏层和非线性激活函数(例如,ReLU),模型可以捕获数据中更复杂的关系。然而,增加参数的数量通常也使得模型更难以训练并且计算起来更复杂。最后一个隐藏层的输出用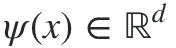 表示:
表示:
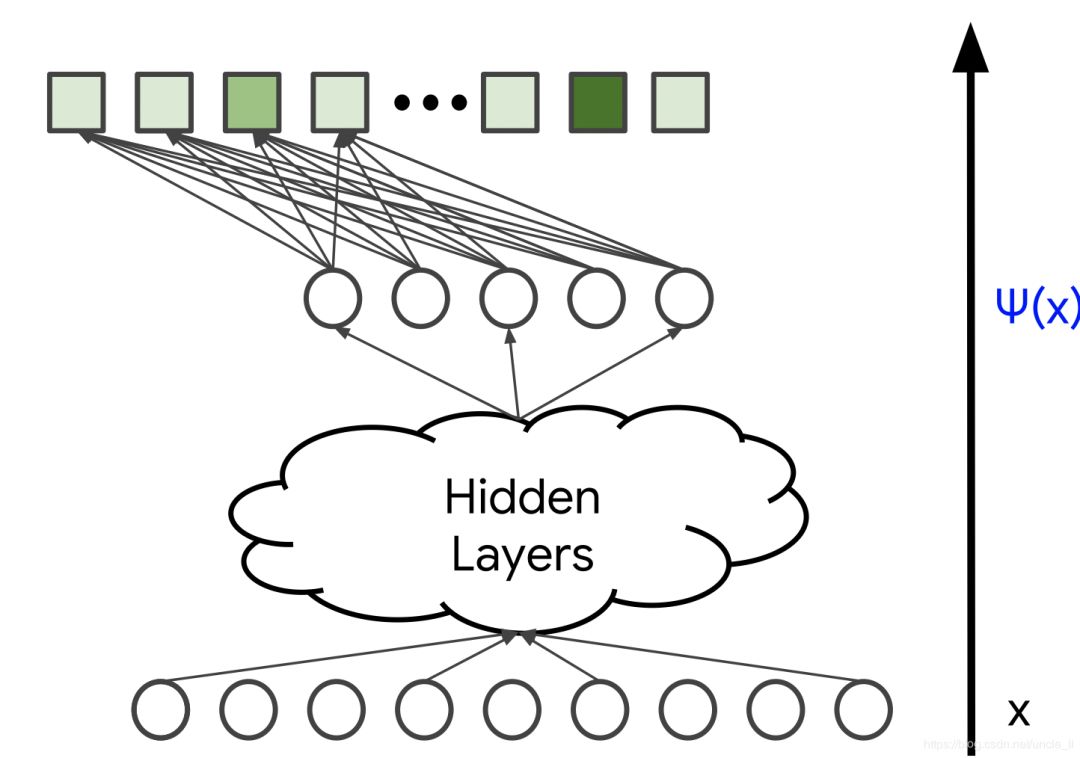
图2.隐藏层的输出, ψ(X)

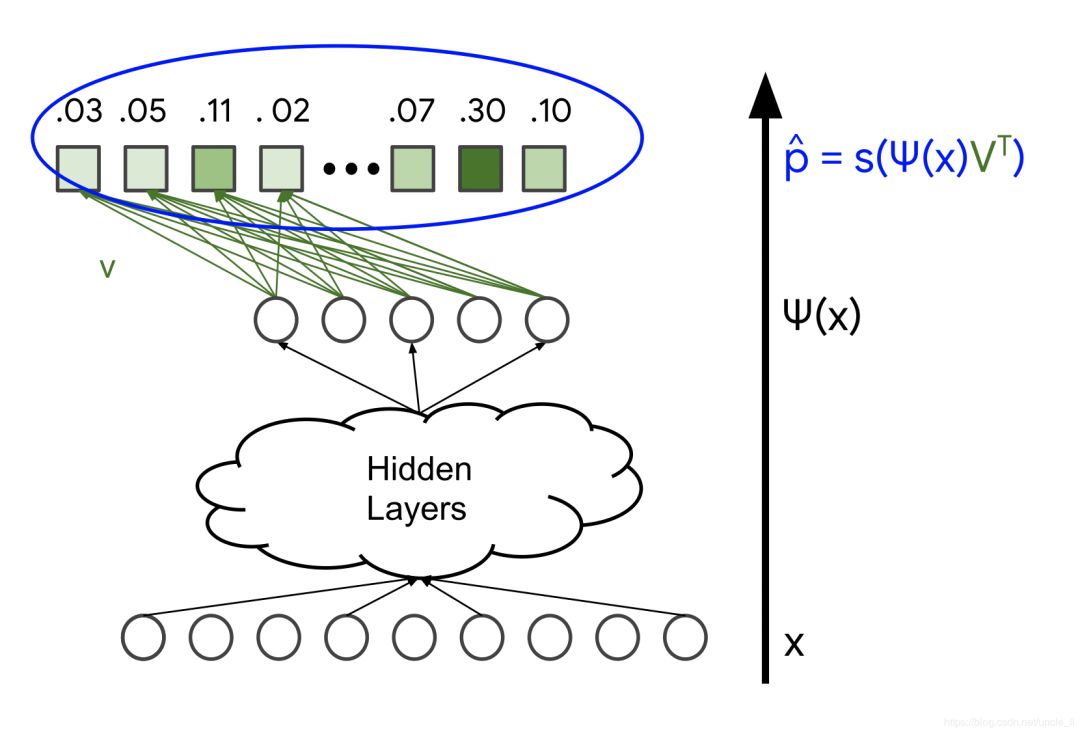


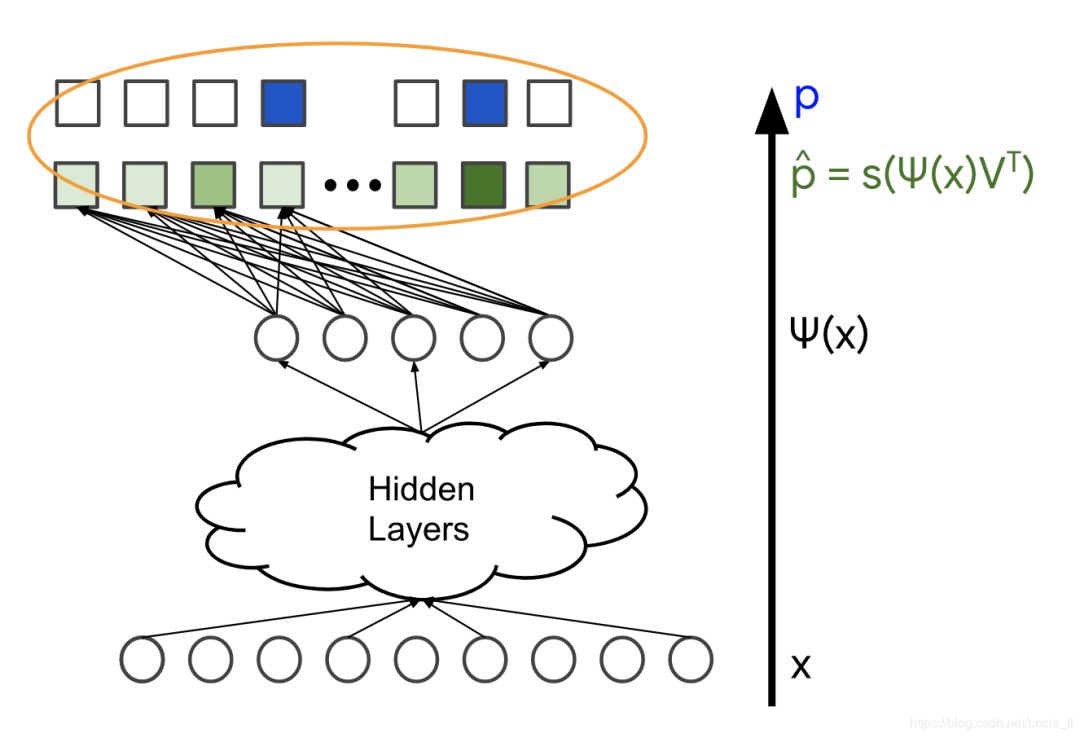
图4.损失函数



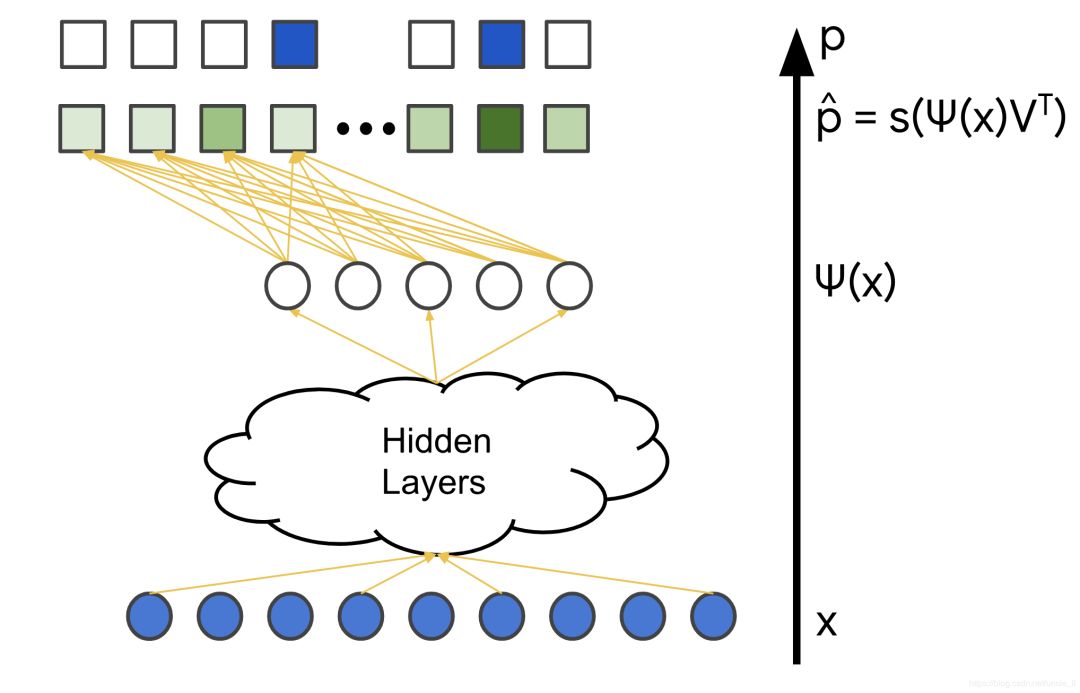
上一节解释了如何将softmax层合并到推荐系统的深度神经网络中。本节将详细介绍此系统的训练数据。
softmax训练数据由查询特征X以及用户与之交互的项目向量(表示为概率分布 p)组成,在下图中用蓝色标记。模型的变量是不同层中的权重,在下图中用橙色标记。通常使用随机梯度下降或其变体方法来训练模型。


DNN模型解决了矩阵分解的许多限制,但通常训练和预测的代价更高。下表总结了两种模型之间的一些重要差异。
| 矩阵分解 | Softmax DNN | |
|---|---|---|
| 查询特征 | 不容易包括在内 | 可以包括在内 |
| 冷启动 | 不容易处理词典查询或项目。可以使用一些启发式方法(例如,对于新查询,类似查询的平均嵌入) | 容易处理新查询 |
| 折页 | 通过调整WALS中未观察到的重量可以轻松减少折叠 | 容易折叠,需要使用负采样或重力等技术 |
| 训练可扩展性 | 可轻松扩展到非常大的语料库(可能是数亿项或更多),但仅限于输入矩阵稀疏 | 难以扩展到非常大的语料库,可以使用一些技术,例如散列,负采样等。 |
| 提供可扩展性 | 嵌入U,V是静态的,并且可以预先计算和存储一组候选 | 项目嵌入V是静态的并且可以存储,查询嵌入通常需要在查询时计算,使得模型的服务成本更高 |
矩阵分解通常是大型语料库的更好选择。它更容易扩展,查询计算量更便宜,并且不易折叠。
DNN模型可以更好地捕获个性化偏好,但是难以训练并且查询成本更高。DNN模型比评分的矩阵分解更可取,因为DNN模型可以使用更多特征来更好地捕获相关性。
上述内容就是如何进行深层神经网络模型Softmax DNN分析,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





