这篇文章给大家介绍Elasticsearch中增加分片数量聚合会不会变快,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
在一次聚合测过程中,我们希望通过增加分片数量的方式,让聚合计算过程更快完成。因此准备了一个索引,该索引有2.6亿 条 doc,大小为70GB,有2个分片。命名为 index2,然后将其 split 为40个分片,生成一个新索引,命名为 index40:
集群有2个节点,JVM 配置30GB,每个索引都经过了 forcemerge。让集群处于空闲状态,然后执行聚合测试。这次聚合测试是为了验证在高基数的数据样本中,bucket 聚合的速度,并了解一下执行原理,看看可以优化的点。为了模拟产生大量 bucket,测试使用深度嵌套聚合:
{ "aggs": { "sip": { "terms": { "field": "sip", "size": 10000 }, "aggs": { "dip": { "terms": { "field": "dip", "size": 10000 }, "aggs": { "proto": { "terms": { "field": "proto", "size": 10000 } } } } } } }}由于 ES 在单个节点的查询并发限制为5,为了提升并行度,加参数 max_concurrent_shard_requests 进行并发控制,本来预期的是让所有分片同时执行聚合,会大幅加快聚合速度,结果却很意外,增加聚合并行度后查询延迟并没有很大区别,而 CPU 利用率却上升了很多!如下表:
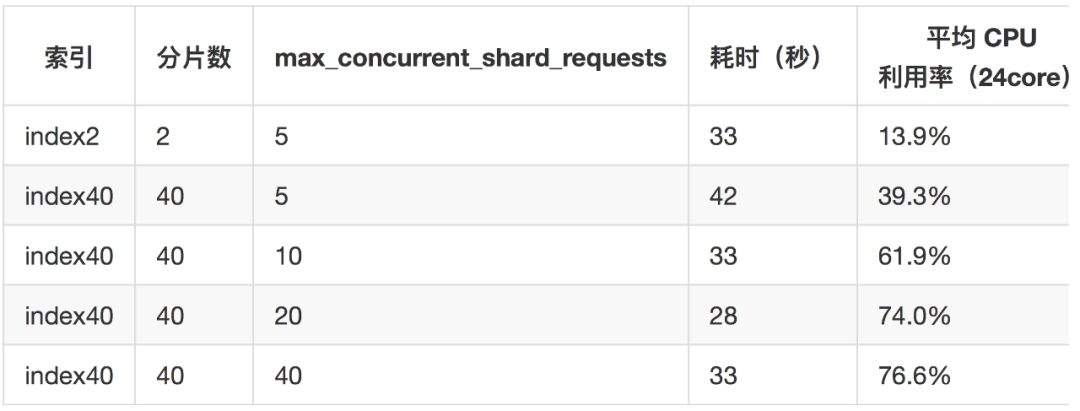
index2的聚合延迟与index40的40并发聚合延迟基本相同,而 CPU 利用率却大幅增加,多出来的 CPU 干什么去了?打 hot_threads,jstack 等只看到在执行聚合,没什么特别的,profile 也没有看到问题。聚合过程中磁盘基本没有 io。
感觉聚合的速度与分片大小没有关系,为了验证这个想法,聚合请求加参数 preference=_shards:0让他只使用0分片的数据聚合,结果3秒就返回结果,参与聚合的分片越多,聚合返回越慢。因此推翻了这个想法。但同时也观察到CPU 利用率奇怪变化,如图,使用4个分片聚合时,起初如左图,4个 core 占满,符合预期,接下来很多其他 core 的利用率就会上升,系统在干什么?
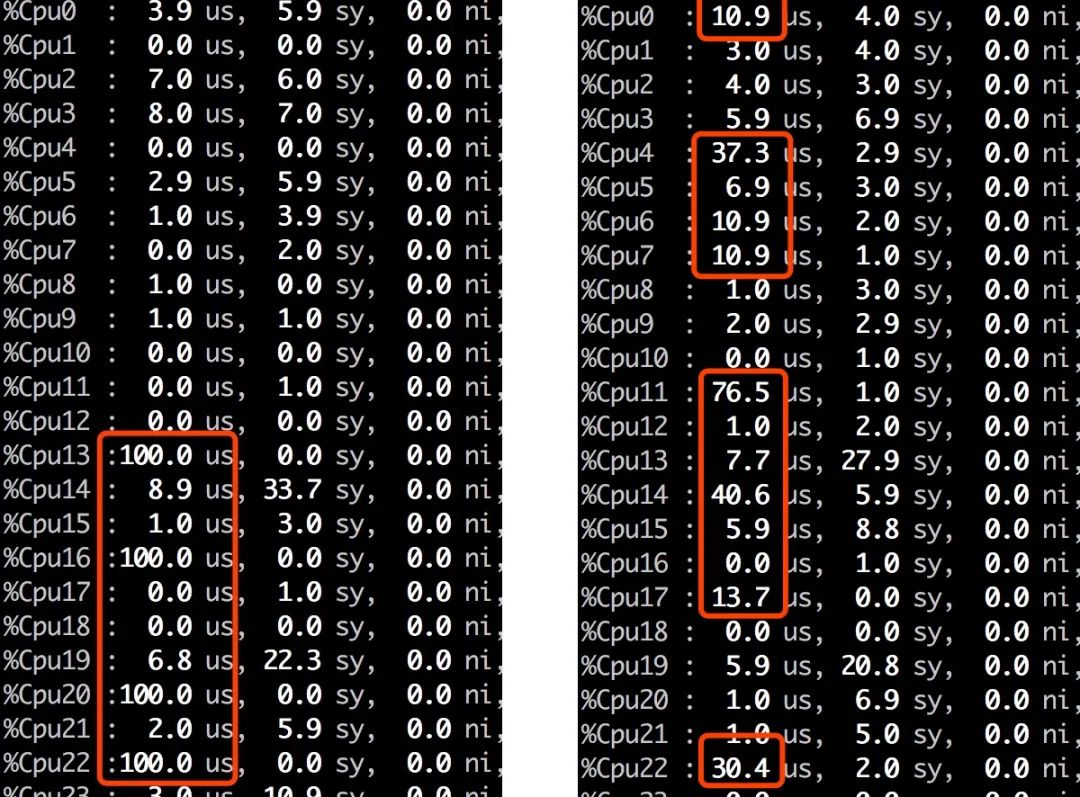
聚合只会在 search 线程池执行,单个分片执行聚合时也不会并发执行,多出来的其他 core 在忙些什么?多次打 jsatck 对比热点线程,定位到了最可疑的调用链:
at org.apache.lucene.store.ByteBufferIndexInput.buildSlice(ByteBufferIndexInput.java:277)....org.elasticsearch.search.aggregations.LeafBucketCollector#collect(int, long)翻一下 buildSlice 的代码,发现每次都要new 一个ByteBuffer出来:
final ByteBuffer slices[] = new ByteBuffer[endIndex - startIndex + 1];collect 每收集只收集一条数据,整个聚合过程中仅在此处就要动态申请大量 ByteBuffer,内存一定有问题,jstat 查看对 index40,max_concurrent_shard_requests=40聚合过程中的 gc 情况,果然非常频繁,部分截图如下:
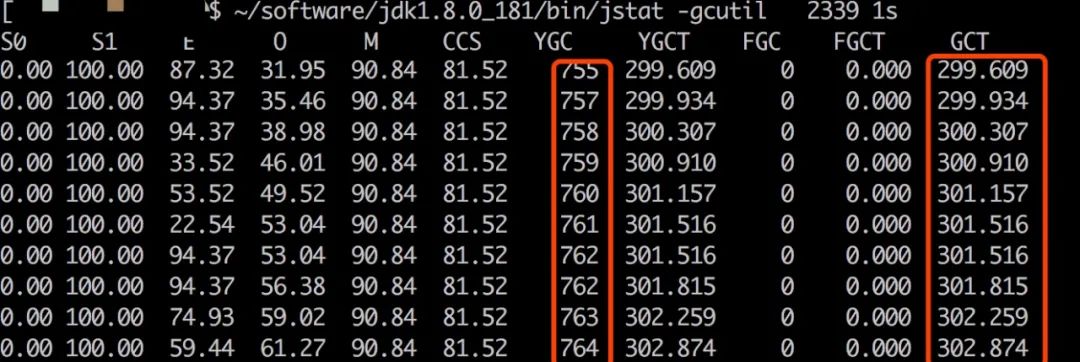
在整个聚合过程中,有大约9秒的时间在执行 GC,而 hot_thread 和 jstack 都无法直接定位到 GC 线程热点,也因此绕了弯路。结合 GC 日志,确认多余的 core 是在忙于并发 GC。
对比 index2d 的聚合过程,YGC 只执行了2次,GCT 消耗时间低于1秒。
问题至此定位完毕。
由此产生一些思考:
聚合计算一条条collect,效率太低,目前很多计算引擎都使用向量化执行,每次处理一批数据。
聚合过程中动态申请内存过于频繁,生成了大量临时对象,给YGC造成较大压力。
增加分片,提升聚合并行度不一定能加快聚合速度,要考虑业务的聚合语句对内存的压力有多大,像今天的例子中,40个分片如果散布在更多的节点中,GC 就不是问题,整体聚合速度就应该快很多。类似的,如果聚合产生的 bucket 少一些的时候,增加聚合并行度可以明显提升整体聚合速度。
聚合要考虑对节点内存的压力,但是这不太好量化出来。建议上线之前提前做好压测。高基数的数据上执行 bucket 聚合有比较大的压力。
关于Elasticsearch中增加分片数量聚合会不会变快就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3536667/blog/4416285



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



