Data Lake架构是怎么样的,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
为在组织的数据环境中创造最大价值,传统的决策支持系统架构难以满足该需求。需要开发新的架构模式以释放数据的价值。为了充分利用大数据的价值,组织需要拥有灵活的数据架构,并能够从其数据生态系统中获取最大价值。
Data Lake概念已经存在了一段时间。但是,我还是看到很多组织结构很难理解这个概念,因为他们对其的理解仍然禁锢在传统的企业数据仓库范式中。
本文将深入研究Data Lake架构模式的概念并设计一个架构模式。
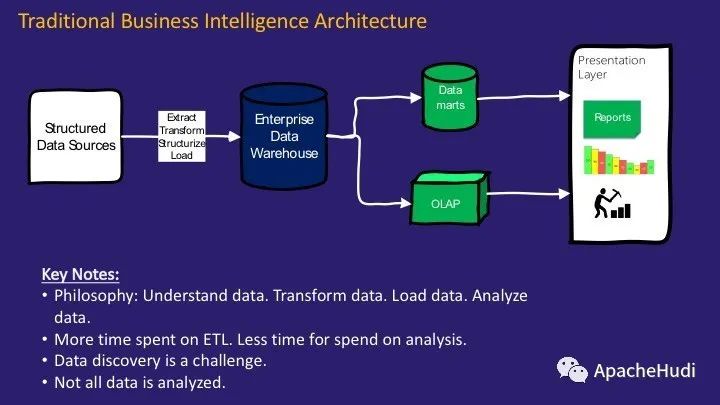
传统的企业DWH架构模式已经使用了很多年。包括数据源、数据提取、转换和加载(ETL),并且在此过程中,会进行某种结构的创建,清理等。在EDW中需要预先定义数据模型(尺寸模型或3NF模型),然后创建数据集市,以用于OLAP多维数据分析以及自助式BI。
这种架构已经服务了很多年。
但是,这种架构存在一些固有的挑战,并且在大数据时代无法解决。其中一些如下:
这种架构需要我们先了解数据。源系统的数据结构是什么,它拥有什么样的数据,基数是什么,应该如何根据业务需求对其进行建模,数据中是否存在异常等等?这是一项繁琐而复杂的工作,进行需求分析或数据分析都需要花费数月时间。并且项目期限往往需要几个月甚至几年。
我们还必须对要存储的数据和要丢弃的数据做出选择和权衡。前期花费大量时间来决定引入什么,如何引入,如何存储,如何转换等。只有较少的时间花费在实际执行数据发现,数据挖掘以及增值业务上。
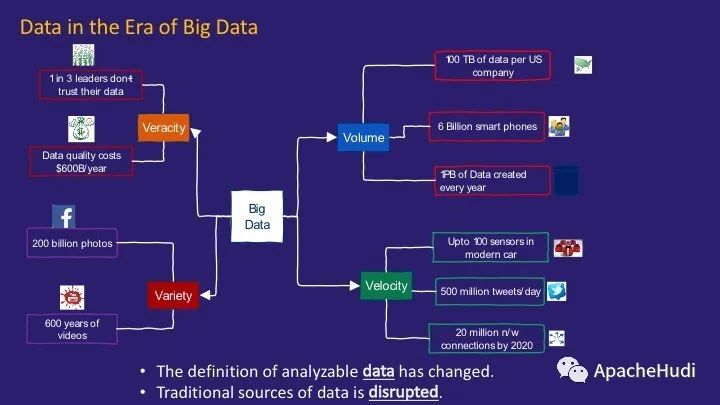
现在让我们简要地讨论一下对数据定义是如何变化的。大数据的4V已经众所周知,即Volume,Velocity,Variety和veracity。其背景如下:
自iPhone革命以来,数据量激增。全球有60亿部智能手机,每天创建近1PB的数据。
数据不仅仅是静止的。有流数据,支持IoT的设备。
还与数据的多样性有关。视频,照片都成为需要分析和利用的数据。
数据的爆炸式增长对数据质量也带来了挑战。在大数据时代,哪一个应该被信任而哪个不应该被信任是一个更大的挑战。
简而言之,可分析的数据定义在变化。现在不仅是结构化的数据,还包括各种非结构化数据。面临的挑战是如何将这些数据融合在一起并使得它们变得更有意义。
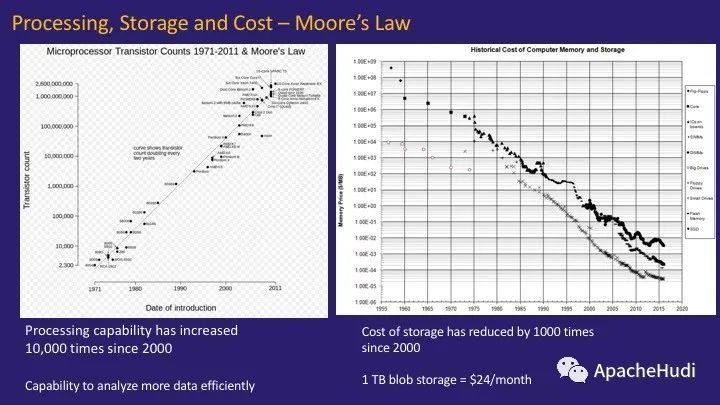
自2000年以来,处理能力,存储和相应的成本结构发生了巨大变化,它受到了摩尔定律的约束。关键点如下:
自2000年以来,处理能力提高了约10,000倍。这意味着有效分析更多数据的能力得到了提高。
存储成本下降了很多。自2000年以来,存储成本下降了1000倍以上。

用一个类比来解释Data Lake的概念。
游览大湖总是一种非常愉快的感觉。湖中的水以其最纯净的形式存在,不同的人在湖上进行不同的活动。有些人在钓鱼,有些人喜欢乘船游览,这个湖还为生活在安大略省的人们提供饮用水。简而言之,同一个湖有多种用途。
随着数据范例的变化,出现了一种新的架构模式。它被称为数据湖架构。就像湖中的水一样,数据湖中的数据也采用最原始的形式存放。就像湖泊一样,它满足了不同人的需要,那些想要钓鱼的人或者想要乘船游览的人,或者想要从湖中喝水的人,一个数据湖架构都可以满足。它为数据科学家提供了探索数据和创建假设的途径。它为业务用户提供了探索数据的途径。它为数据分析人员提供了分析数据和寻找模式的途径。它为报告分析师提供了创建报告并呈现给利益相关者的途径。
数据湖与数据仓库或数据集市进行如下比较:
Data Lake以最原始的形式存储数据,可以满足多个利益相关者的需求,也可以用于打包数据,以供最终用户使用。另一方面,数据仓库是已经经过蒸馏和包装(矿泉水)以用于特定目的数据存储。
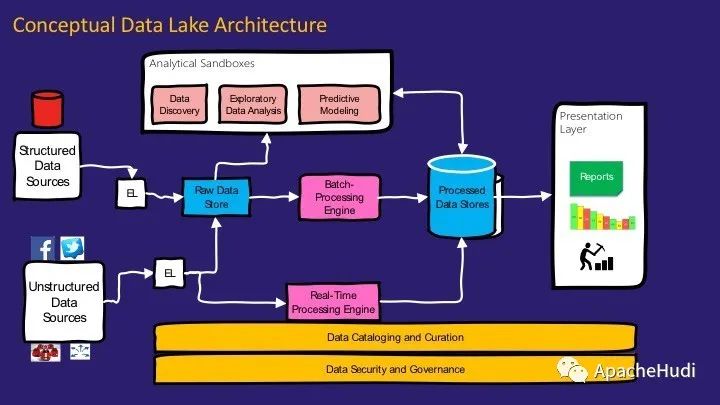
通过前面的背景介绍,现在让我们了解数据湖的概念体系结构。数据湖体系结构中的关键组件有可以结构化和非结构化的数据源,它们都集成到原始数据存储中,以最原始的方式存放数据,即不进行任何转换。它是一种廉价的持久性存储,可以大规模存储数据。然后,我们使用分析沙箱来理解数据、创建原型、进行数据科学并探索数据以建立新的假设和用例。
然后我们有了批处理引擎,该引擎将原始数据处理成可被用户直接使用的数据,即可以用于向最终用户出报告的数据结构。我们称其为已处理数据存储。有一个实时处理引擎,可以获取流数据并对其进行处理。此体系结构中的所有数据均已分类并整理。
下面让我们了解此体系结构中的每个组件组。
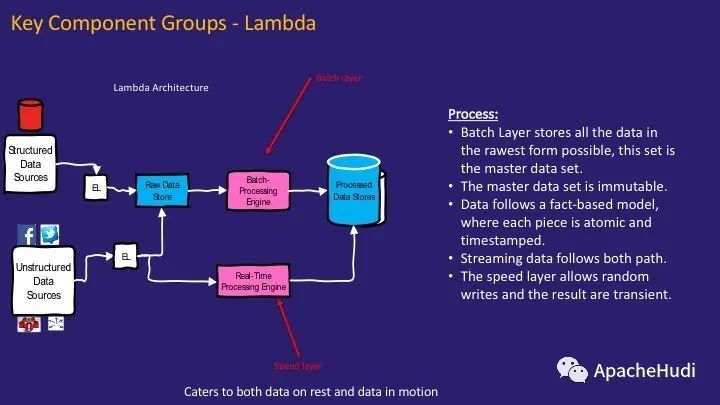
第一个组件组用于处理数据。它遵循Lambda架构,一般Lambda架构会采用两条处理路径:批处理层和实时处理层。批处理层以可能的最原始形式存储数据,即原始数据存储和实时处理层几乎实时地处理数据。实时处理层将数据存储到原始数据存储中,并且可以在加载到已处理的数据存储之前存储瞬态数据。
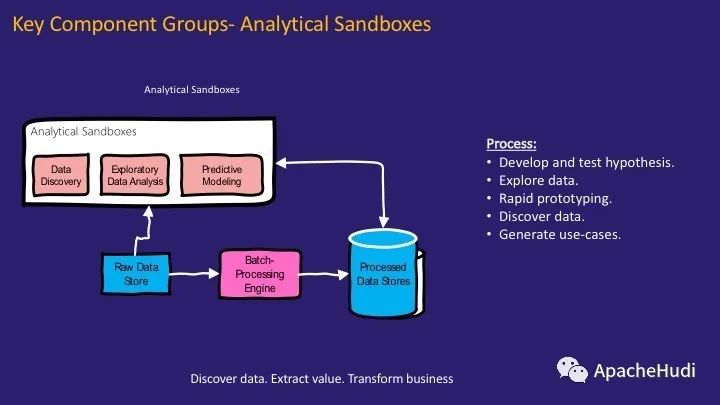
分析沙箱是数据湖架构中的关键组件之一。这些是数据科学家的探索性领域,他们可以在其中开发和测试新的假设、合并和探索数据以形成新的用例,创建快速的原型以验证这些用例并意识到可以采取哪些措施从中提取价值。
简单来说,它是数据科学家可以发现数据,提取价值并帮助转变业务的地方。
数据编录在传统商业架构中经常被忽略。在大数据领域,编录是非常重要的方面。让我们举个例子来说明它的重要性。
当我要求我的客户在不提供编录信息的情况下猜测这幅画的潜在成本时,答案从100美元到100,000美元不等。当我提供目录信息时,答案更接近于实际情况。顺便说一句,这幅画被巴勃罗·毕加索(Pablo Picasso)称为“旧吉他手”,创作于1903年。估计造价超过1亿美元。
数据编录非常相似。不同的数据块具有不同的值,并且该值根据数据的沿袭(lineage)、数据的质量、·创建的来源等而变化。需要对数据进行分类,以便数据分析师或数据科学家可以自己决定指向哪个数据用于特定分析。
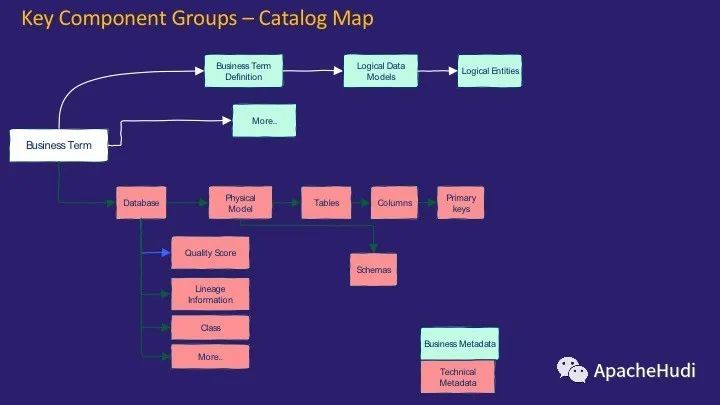
编录图提供了可以分类的元数据。编录是捕获有价值的元数据的过程,因此可以将其用于确定数据的特征并决定是否使用它。基本上有两种类型的元数据:业务元数据和技术元数据。业务元数据更多地与定义、逻辑数据模型、逻辑实体等有关;而技术元数据则是捕获与数据结构的物理实现有关的元数据。它包括数据库、质量得分、列、架构等。
根据编录信息,分析人员可以选择在正确的上下文中使用特定的数据点。举个例子,想象一下,数据科学家想要对库存周转率及其在ERP和库存系统中的定义方式进行探索性分析。如果对术语进行了分类,则数据科学家可以根据上下文决定使用来自ERP还是清单系统中的列。
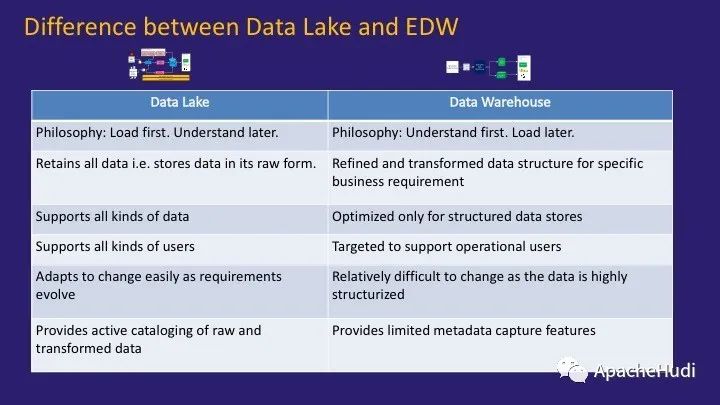
上图表格试图解释差异
首先,哲学不同。在数据湖体系结构中,我们首先要原始加载数据,然后决定应如何处理。在传统的DWH体系结构中,我们必须首先了解数据,对其进行建模,然后再将其加载。
数据湖中的数据以原始格式存储,而DWH中的数据以结构化格式存储,类比湖水和蒸馏水。
Data Lake支持各种用户。
分析项目确实是敏捷项目。这些项目的本质是,一旦你看到输出,便会思考更多并想要更多。Data Lake本质上是敏捷的。由于他们将所有数据存储在编录中,因此可以确保在出现新需求时可以轻松地进行调整。
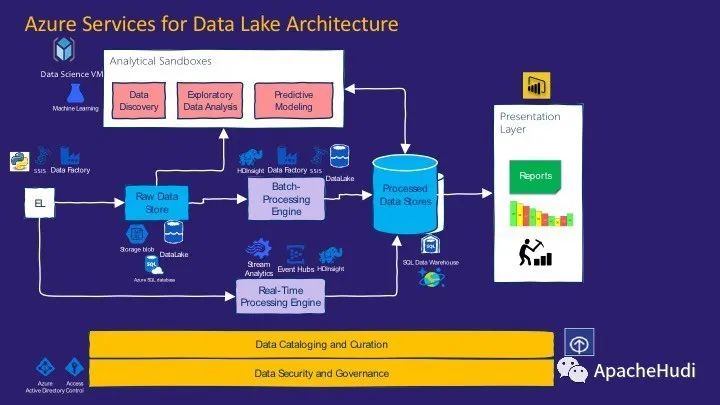
云平台最适合实施数据湖架构.它们具有大量可组合的服务,可以将它们组合在一起以实现所需的可伸缩性。微软的Cortana Intelligence Suite提供了一个或多个组件,可以将其映射为实现数据湖架构的组件。
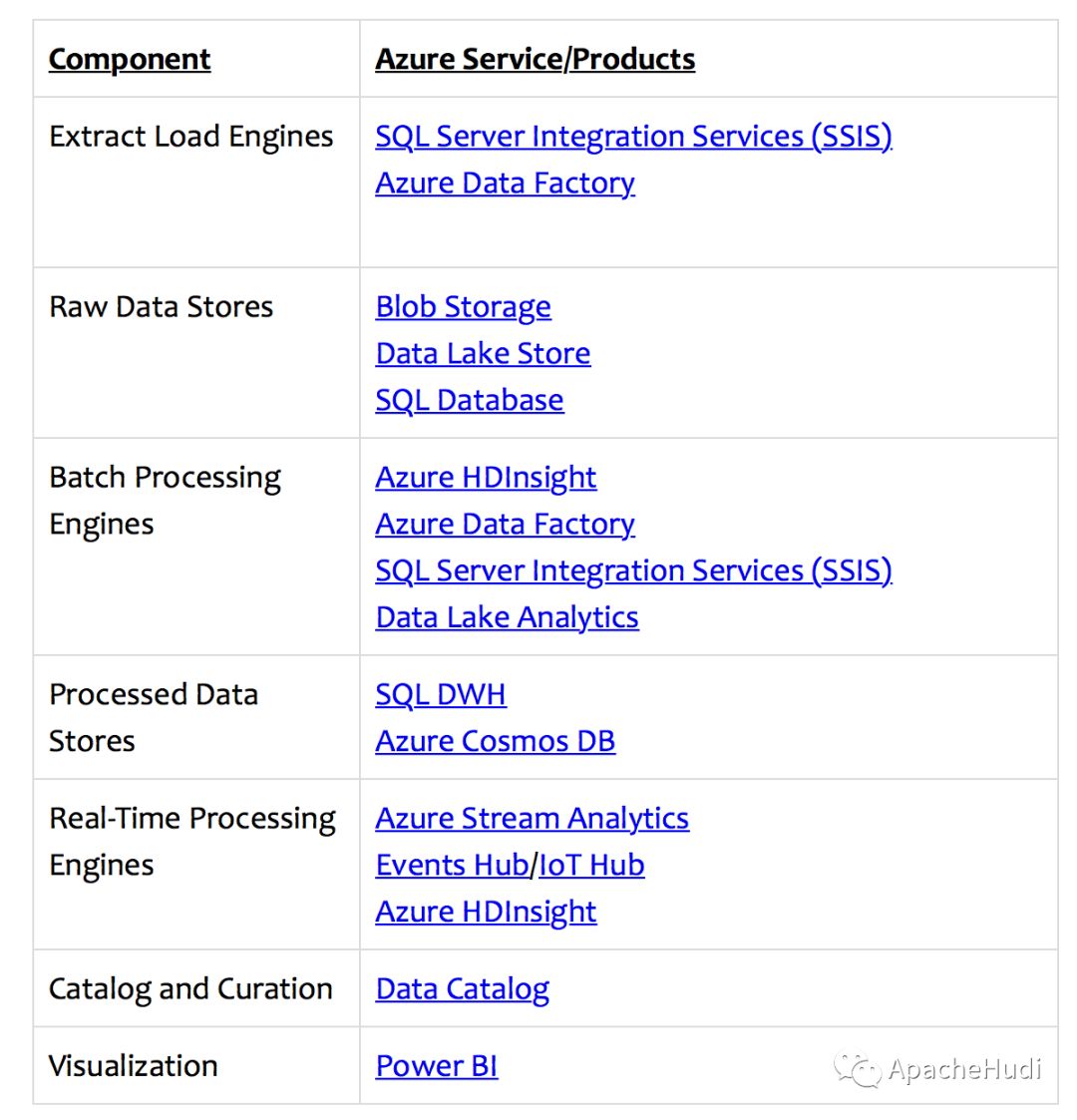
数据湖是大数据架构的新范式。
数据湖可以满足各种数据的需求。以原始格式存储数据,可以满足用户的广泛需求,并能提供更快的洞察力。
细致的数据编录和管理是成功实施数据湖的关键。
云平台为实施经济、可扩展的数据湖架构提供了端到端的端解决方案。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





