本篇内容介绍了“怎么用Python爬取微博热搜榜数据”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
微博的热搜榜对于研究大众的流量有非常大的价值。今天的教程就来说说如何爬取微博的热搜榜。热搜榜的链接是:
https://s.weibo.com/top/summary/
用浏览器浏览,发现在不登录的情况下也可以正常查看,那就简单多了。使用开发者工具(F12)查看页面逻辑,并拿到每条热搜的CSS位置,方法如下:
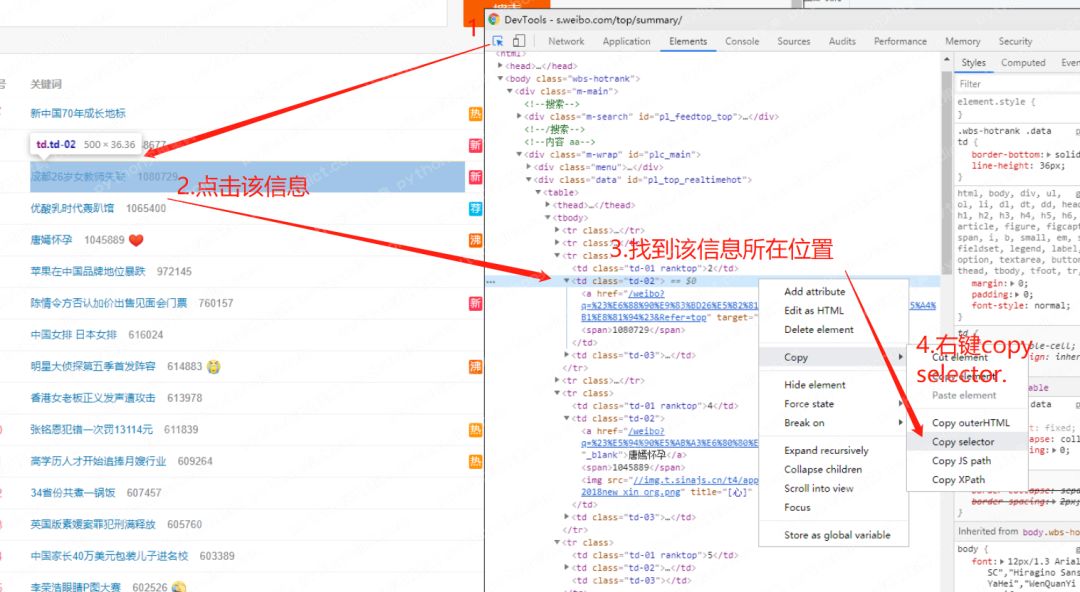
按照这个方法,拿到这个td标签的selector是:
pl_top_realtimehot > table > tbody > tr:nth-child(3) > td.td-02
其中nth-child(3)指的是第三个tr标签,因为这条热搜是在第三名的位置上,但是我们要爬的是所有热搜,因此:nth-child(3)可以去掉。还要注意的是 pl_top_realtimehot 是该标签的id,id前需要加#号,最后变成:
#pl_top_realtimehot > table > tbody > tr > td.td-02
你可以自定义你想要爬的信息,这里我需要的信息是:热搜的链接及标题、热搜的热度。它们分别对应的CSS选择器是:
链接及标题:#pl_top_realtimehot > table > tbody > tr > td.td-02 > a
热度:#pl_top_realtimehot > table > tbody > tr > td.td-02 > span
值得注意的是链接及标题是在同一个地方,链接在a标签的href属性里,标题在a的文本中,用beautifulsoup有办法可以都拿到,请看后文代码。
现在这些信息的位置我们都知道了,接下来可以开始编写程序。默认你已经安装好了python,并能使用cmd的pip,如果没有的话请见这篇教程:python安装。需要用到的python的包有:
BeautifulSoup4:
cmd/Terminal 安装指令: pip install beautifulsoup4.
lxml解析器:
cmd/Terminal 安装指令: pip install lxml
编写代码:

代码说明请看注释

代码说明请看注释,不过这样做,仅仅是将结果保存到数组中,结果非常不易观看,我们下面将其保存为csv文件。

效果如下,怎么样,是不是好看很多:
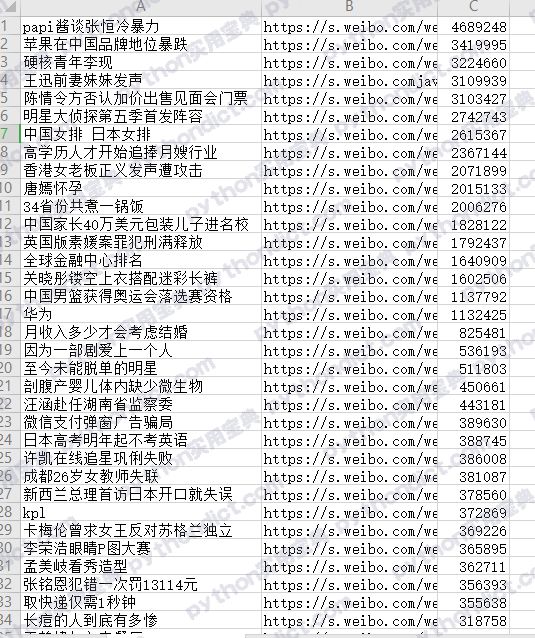
完整代码如下,文字版请阅读原文进入网站阅读:

“怎么用Python爬取微博热搜榜数据”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





