这篇文章将为大家详细讲解有关HashMap为什么会导致CPU100%,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
先来说 HashMap 的底层数据结构,看过 HashMap 的源码我们就会发现,JDK 1.7 和 JDK 1.8 HashMap 的组成是不同的,JDK 1.7 HashMap 的组成是数组 + 链表的形式,而 JDK 1.8 新增了红黑树的数据结构,当 HashMap 中的链表长度大于 8 时,链表结构就会转换为红黑树,如下图所示:
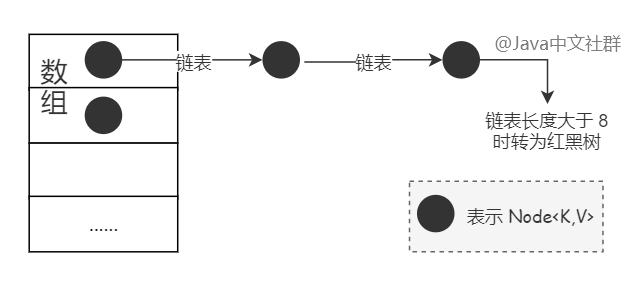
所谓的哈希碰撞指的是不同的值,经过哈希之后得到的值确是相同的,这种情况就叫做哈希碰撞或哈希冲突。解决哈希碰撞的常用方法是:开放定址法和链表地址法,而 HashMap 采用的就是链表地址法。它的实现原理就是将 HashMap 中相同的哈希值以链表的形式存储起来。
扩展因子也叫加载因子或负载因子是 HashMap 中的一个属性,如下图所示: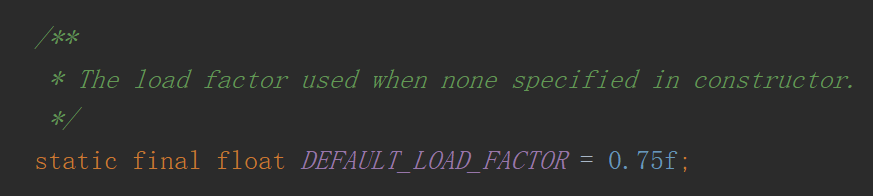 假如数组的默认长度为 10,扩展因子为 0.5,那么当数组超过 10*0.5=5 个时,HashMap 就会扩容为之前容量的两倍,所以说扩展因子就是用来判定 HashMap 是否满足扩容条件的。
假如数组的默认长度为 10,扩展因子为 0.5,那么当数组超过 10*0.5=5 个时,HashMap 就会扩容为之前容量的两倍,所以说扩展因子就是用来判定 HashMap 是否满足扩容条件的。
HashMap 导致 CPU 100% 的原因就是因为 HashMap 死循环导致的,那 HashMap 是如何造成死循环的?接下来我们一起来看。
以 JDK 1.7 为例,假设 HashMap 的默认大小为 2,HashMap 本身中有一个键值 key(5),我们再使用两个线程:t1 添加 key(3),t2 添加 key(7),首先两个线程先把 key(3) 和 key(7) 都添加到 HashMap 中,此时因为 HashMap 的长度不够用了就会进行扩容操作,然后这时线程 t1 在执行到 Entry<K,V> next = e.next; 时,交出了 CPU 的使用权,源代码如下:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next; // 线程一执行此处
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
那么此时线程 t1 中的 e 指向了 key(3),而 next 指向了 key(7) ;之后线程 t2 重新 rehash 之后链表的顺序被反转,链表的位置变成了 key(5) -> key(7) -> key(3),其中 “->” 用来表示下一个元素,当 t1 重新获得执行权之后,先执行 newTalbe[i] = e 把 key(3) 的 next 设置为 key(7),而下次循环时查询到 key(7) 的 e.next 为 key(3),于是就形 成了 key(3) 和 key(7) 的环形引用,就导致了死循环的产生,如下图所示:

HashMap 发生死循环的一个重要原因是 JDK 1.7 时链表的插入是首部倒序插入的,而 JDK 1.8 时已经变成了尾部插入,有人把这个死循环的问题反馈给了 Sun 公司,但它们认为这不是一个问题,因为 HashMap 本身就是非线程安全的,如果要在多线程使用建议使用 ConcurrentHashMap 替代 HashMap,但面试中这个问题被问的频率比较高,所以在这里就特殊说明一下。
HashMap 是非线程安全的,以 JDK 1.7 为例,当多线程并发扩容时就会出现环形引用的问题,从而导致死循环的出现,一直死循环就会导致 CPU 运行 100%。
关于HashMap为什么会导致CPU100%就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





