本篇内容主要讲解“Python处理大数据的加速器有哪些”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Python处理大数据的加速器有哪些”吧!
Mars 是numpy 、 pandas 、scikit-learn的并行和分布式加速器,由阿里云高级软件工程师秦续业等人开发的一个基于张量的大规模数据计算的统一框架,目前它已在 GitHub 上开源。该工具能用于多个工作站,而且即使在单块 CPU 的情况下,它的矩阵运算速度也比 NumPy(MKL)快。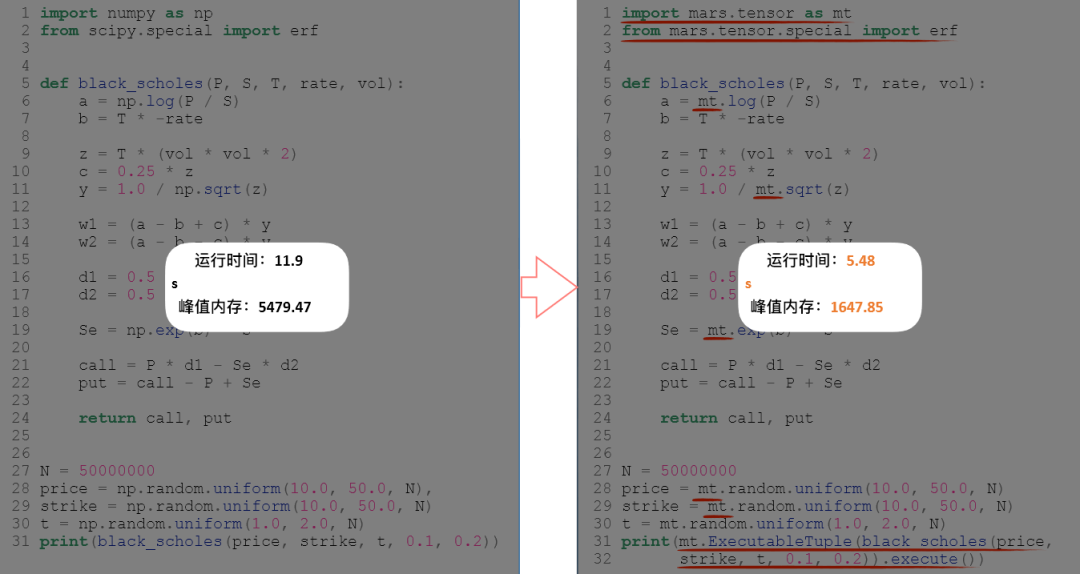
官方文档:https://docs.mars-project.io
Dask是一个并行计算库,能在集群中进行分布式计算,能以一种更方便简洁的方式处理大数据量,与Spark这些大数据处理框架相比较,Dask更轻。Dask更侧重与其他框架,如:Numpy,Pandas,Scikit-learning相结合,从而使其能更加方便进行分布式并行计算。

官方文档:https://docs.dask.org/en/latest/
CuPy 是一个借助 CUDA GPU 库在英伟达 GPU 上实现 Numpy 数组的库。基于 Numpy 数组的实现,GPU 自身具有的多个 CUDA 核心可以促成更好的并行加速。CuPy 接口是 Numpy 的一个镜像,并且在大多情况下,它可以直接替换 Numpy 使用。只要用兼容的 CuPy 代码替换 Numpy 代码,用户就可以实现 GPU 加速。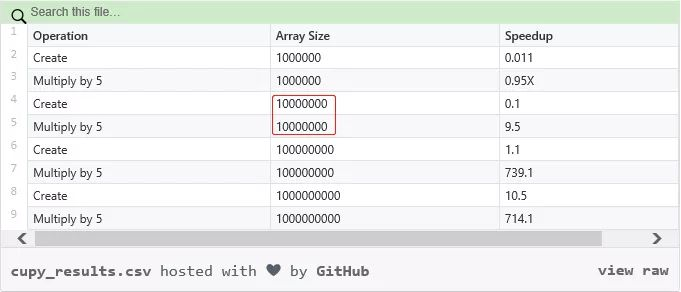
官方文档:https://docs-cupy.chainer.org/en/stable/
Vaex是一个开源的 DataFrame 库,对于和你硬盘空间一样大小的表格数据集,它可以有效进行可视化、探索、分析乃至实践机器学习。Vaex采用了内存映射、高效的外核算法和延迟计算等概念来获得最佳性能(不浪费内存),一旦数据存为内存映射格式,即便它的磁盘大小超过 100GB,用 Vaex 也可以在瞬间打开它(0.052 秒)。
官方文档:https://vaex.readthedocs.io/en/latest/
到此,相信大家对“Python处理大数据的加速器有哪些”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





