pythonжҖҺд№Ҳе®һзҺ°еЈҒзәёжү№йҮҸдёӢиҪҪ
иҝҷзҜҮвҖңpythonжҖҺд№Ҳе®һзҺ°еЈҒзәёжү№йҮҸдёӢиҪҪвҖқж–Үз« зҡ„зҹҘиҜҶзӮ№еӨ§йғЁеҲҶдәәйғҪдёҚеӨӘзҗҶи§ЈпјҢжүҖд»Ҙе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеҶ…е®№иҜҰз»ҶпјҢжӯҘйӘӨжё…жҷ°пјҢе…·жңүдёҖе®ҡзҡ„еҖҹйүҙд»·еҖјпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« иғҪжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘзңӢзңӢиҝҷзҜҮвҖңpythonжҖҺд№Ҳе®һзҺ°еЈҒзәёжү№йҮҸдёӢиҪҪвҖқж–Үз« еҗ§гҖӮ
еҲқе§ӢеҢ–йЎ№зӣ®
иҜҘйЎ№зӣ®дҪҝз”ЁvirtualenvеҲӣе»әдёҖдёӘиҷҡжӢҹзҺҜеўғпјҢд»ҘйҒҝе…ҚжұЎжҹ“ж•ҙдёӘжғ…еҶөгҖӮдҪҝз”Ёpip3зӣҙжҺҘдёӢиҪҪпјҡ
Pip3installvirtualenv然еҗҺеңЁеҗҲйҖӮзҡ„ең°ж–№еҲӣе»әдёҖдёӘж–°зҡ„еЈҒзәё-дёӢиҪҪеҷЁзӣ®еҪ•пјҢдҪҝз”ЁvirtualenvеҲӣе»әдёҖдёӘеҗҚдёәvenvзҡ„иҷҡжӢҹзҺҜеўғпјҡ
virtualenvvenvгҖӮvenv/bin/жҝҖжҙ»дёӢдёҖжӯҘпјҢеҲӣе»әдёҖдёӘдҫқиө–зӣ®еҪ•пјҡ
жңҖеҗҺпјҢyunдёӢиҪҪ并е®үиЈ…дҫқиө–йЎ№пјҡ
pip 3 install-requirements . txtеҲҶжһҗзҲ¬иҷ«е·ҘдҪңжӯҘйӘӨ
дёәдәҶз®ҖеҚ•иө·и§ҒпјҢжҲ‘们зӣҙжҺҘиҝӣе…ҘеҲҶзұ»дёәвҖңиҲӘз©әвҖқзҡ„еЈҒзәёеҲ—иЎЁйЎөйқў
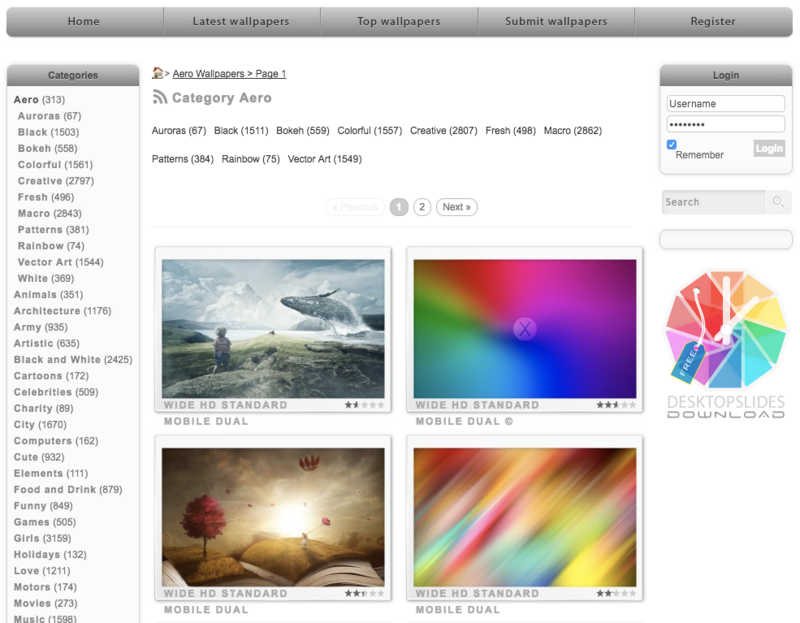
еҰӮжӮЁжүҖи§ҒпјҢжң¬йЎөжңү10еј еЈҒзәёеҸҜдҫӣдёӢиҪҪгҖӮдҪҶжҳҜеӣ дёәиҝҷйҮҢжҳҫзӨәзҡ„йғҪжҳҜзј©з•ҘеӣҫпјҢдҪңдёәеЈҒзәёзҡ„е®ҡд№үиҝңиҝңдёҚеӨҹпјҢжүҖд»ҘйңҖиҰҒиҝӣе…ҘеЈҒзәёиҜҰжғ…йЎөжүҚиғҪжүҫеҲ°HDзҡ„дёӢиҪҪй“ҫжҺҘгҖӮзӮ№еҮ»з¬¬дёҖеј еЈҒзәёпјҢдҪ еҸҜд»ҘзңӢеҲ°дёҖдёӘж–°зҡ„йЎөйқўпјҡ
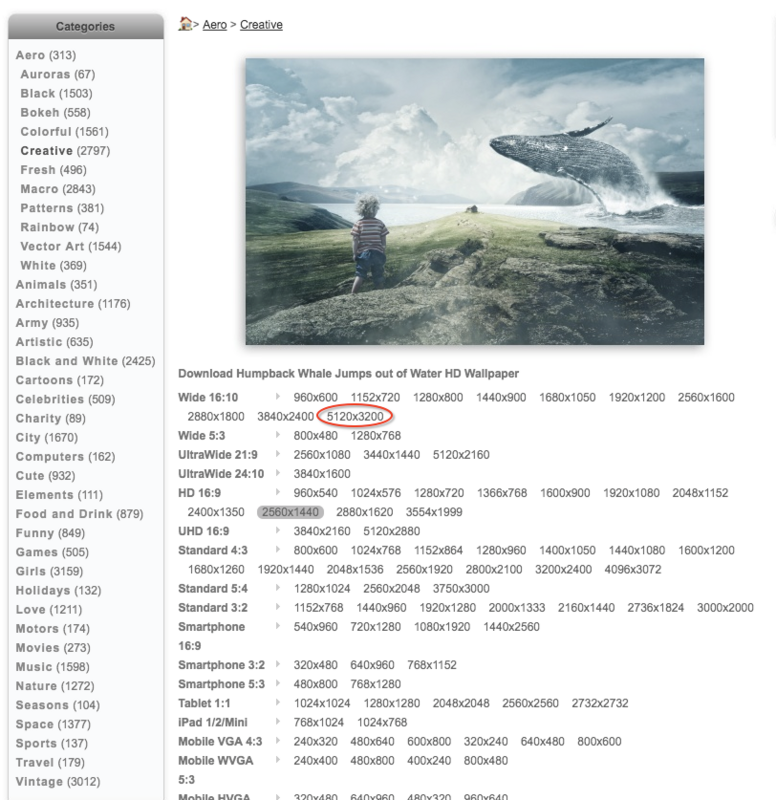
еӣ дёәжҲ‘зҡ„жңәеҷЁжҳҜRetinaеұҸ幕пјҢжүҖд»Ҙжү“з®—зӣҙжҺҘдёӢиҪҪжңҖеӨ§зҡ„пјҢдҝқиҜҒй«ҳжё…(зәўеңҲжҳҫзӨәзҡ„йҹійҮҸ)гҖӮ
дәҶи§Је…·дҪ“жӯҘйӘӨеҗҺпјҢе°ұжҳҜйҖҡиҝҮејҖеҸ‘иҖ…е·Ҙе…·жүҫеҲ°еҜ№еә”зҡ„domиҠӮзӮ№пјҢжҸҗеҸ–еҜ№еә”зҡ„urlгҖӮиҝҷдёӘиҝҮзЁӢдёҚеҶҚиҝӣиЎҢпјҢиҜ»иҖ…еҸҜд»ҘиҮӘиЎҢе°қиҜ•гҖӮжҺҘдёӢжқҘпјҢиҫ“е…Ҙзј–з ҒйғЁеҲҶгҖӮ
и®ҝй—®йЎөйқў
еҲӣе»әдёҖдёӘж–°зҡ„download.pyж–Ү件пјҢ然еҗҺеј•е…ҘдёӨдёӘеә“пјҡ
from bs4 importзҫҺеҢ–з»„
еҜје…ҘиҜ·жұӮжҺҘдёӢжқҘпјҢзј–еҶҷдёҖдёӘи®ҝй—®url然еҗҺиҝ”еӣһйЎөйқўhtmlзҡ„зү№ж®ҠеҮҪж•°пјҡ
defvisit_page(url):
ж Үйўҳ={
з”ЁжҲ·д»ЈзҗҶ' : ' Mozilla/5.0(Macintoshпјӣintelmacosx 10 _ 13 _ 1)apple WebKit/537.36(KHTMLпјҢlike gecko)Chrome/63 . 0 . 3239 . 108 safari/537.36вҖҷ
}
r=requests.get(urlпјҢheaders=headers)
r.encoding='utf-8 '
soup=зҫҺеҢ–з»„(r.textпјҢ' lxml ')
дёәдәҶйҳІжӯўreturnsoupиў«зҪ‘з«ҷзҡ„еҸҚжҠ“еҸ–жңәеҲ¶еҮ»дёӯпјҢжҲ‘们йңҖиҰҒйҖҡиҝҮеңЁеӨҙйғЁж·»еҠ UAжқҘе°ҶзҲ¬иҷ«дјӘиЈ…жҲҗжҷ®йҖҡжөҸи§ҲеҷЁпјҢ然еҗҺжҢҮе®ҡutf-8зј–з ҒпјҢжңҖеҗҺд»Ҙеӯ—з¬ҰдёІж јејҸиҝ”еӣһhtmlгҖӮ
жҸҗеҸ–й“ҫжҺҘ
иҺ·еҸ–йЎөйқўhtmlеҗҺпјҢйңҖиҰҒжҸҗеҸ–иҜҘйЎөйқўеЈҒзәёеҲ—иЎЁеҜ№еә”зҡ„url:
defget_paper_link(第пјҡйЎө)
links=page . select(# contentidivullidiva)
collect=[]
forlinkinlinks:
collect.append(link.get('href '))
еҮҪж•°returncollectе°ҶжҸҗеҸ–еҲ—иЎЁйЎөйқўдёӯжүҖжңүеЈҒзәёиҜҰз»ҶдҝЎжҒҜзҡ„urlгҖӮ
дёӢиҪҪеЈҒзәё
жңүдәҶиҜҰз»ҶйЎөйқўзҡ„ең°еқҖпјҢжҲ‘们е°ұеҸҜд»ҘиҝӣеҺ»йҖүжӢ©еҗҲйҖӮзҡ„е°әеҜёгҖӮеҲҶжһҗйЎөйқўзҡ„domз»“жһ„еҗҺпјҢжҲ‘们еҸҜд»ҘзҹҘйҒ“жҜҸдёӘеӨ§е°ҸеҜ№еә”дёҖдёӘй“ҫжҺҘпјҡ
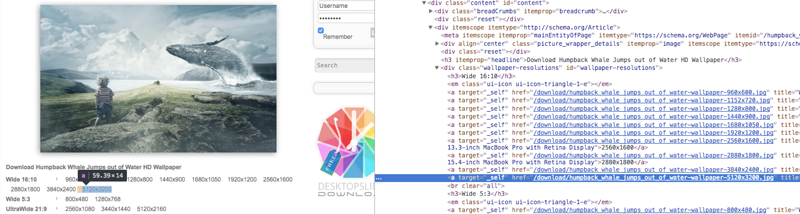
жүҖд»Ҙ第дёҖжӯҘжҳҜжҸҗеҸ–еҜ№еә”дәҺиҝҷдәӣеӨ§е°Ҹзҡ„й“ҫжҺҘпјҡ
еўҷ
paper_source=visit_page(link) wallpaper_size_links=wallpaper_source.select('#wallpaper-resolutions>a') size_list=[] forlinkinwallpaper_size_links: href=link.get('href') size_list.append({ 'size':eval(link.get_text().replace('x','*')), 'name':href.replace('/download/',''), 'url':href })
size_listе°ұжҳҜиҝҷдәӣй“ҫжҺҘзҡ„дёҖдёӘйӣҶеҗҲгҖӮдёәдәҶж–№дҫҝжҺҘдёӢжқҘйҖүеҮәжңҖй«ҳжё…пјҲдҪ“з§ҜжңҖеӨ§пјүзҡ„еЈҒзәёпјҢеңЁsizeдёӯжҲ‘дҪҝз”ЁдәҶevalж–№жі•пјҢзӣҙжҺҘжҠҠиҝҷйҮҢзҡ„5120x3200з»ҷи®Ўз®—еҮәжқҘпјҢдҪңдёәsizeзҡ„еҖјгҖӮ
иҺ·еҸ–дәҶжүҖжңүзҡ„йӣҶеҗҲд№ӢеҗҺпјҢе°ұеҸҜд»ҘдҪҝз”Ёmax()ж–№жі•йҖүеҮәжңҖй«ҳжё…зҡ„дёҖйЎ№еҮәжқҘдәҶпјҡ
biggest_one=max(size_list,key=lambdaitem:item['size'])
иҝҷдёӘbiggest_oneеҪ“дёӯзҡ„urlе°ұжҳҜеҜ№еә”sizeзҡ„дёӢиҪҪй“ҫжҺҘпјҢжҺҘдёӢжқҘеҸӘйңҖиҰҒйҖҡиҝҮrequestsеә“жҠҠй“ҫжҺҘзҡ„иө„жәҗдёӢиҪҪдёӢжқҘеҚіеҸҜпјҡ
result=requests.get(PAGE_DOMAIN+biggest_one['url'])
ifresult.status_code==200:
open('wallpapers/'+biggest_one['name'],'wb').write(result.content)жіЁж„ҸпјҢйҰ–е…ҲдҪ йңҖиҰҒеңЁж №зӣ®еҪ•дёӢеҲӣе»әдёҖдёӘwallpapersзӣ®еҪ•пјҢеҗҰеҲҷиҝҗиЎҢж—¶дјҡжҠҘй”ҷгҖӮ
ж•ҙзҗҶдёҖдёӢпјҢе®Ңж•ҙзҡ„download_wallpaperеҮҪж•°й•ҝиҝҷж ·пјҡ
defdownload_wallpaper(link):
wallpaper_source=visit_page(PAGE_DOMAIN+link)
wallpaper_size_links=wallpaper_source.select('#wallpaper-resolutions>a')
size_list=[]
forlinkinwallpaper_size_links:
href=link.get('href')
size_list.append({
'size':eval(link.get_text().replace('x','*')),
'name':href.replace('/download/',''),
'url':href
})
biggest_one=max(size_list,key=lambdaitem:item['size'])
print('Downloadingthe'+str(index+1)+'/'+str(total)+'wallpaper:'+biggest_one['name'])
result=requests.get(PAGE_DOMAIN+biggest_one['url'])
ifresult.status_code==200:
open('wallpapers/'+biggest_one['name'],'wb').write(result.content)жү№йҮҸиҝҗиЎҢ
дёҠиҝ°зҡ„жӯҘйӘӨд»…д»…иғҪеӨҹдёӢиҪҪ第дёҖдёӘеЈҒзәёеҲ—иЎЁйЎөзҡ„第дёҖеј еЈҒзәёгҖӮеҰӮжһңжҲ‘们жғідёӢиҪҪеӨҡдёӘеҲ—иЎЁйЎөзҡ„е…ЁйғЁеЈҒзәёпјҢжҲ‘们е°ұйңҖиҰҒеҫӘзҺҜи°ғз”Ёиҝҷдәӣж–№жі•гҖӮйҰ–е…ҲжҲ‘们е®ҡд№үеҮ дёӘеёёйҮҸпјҡ
importsys
iflen(sys.argv)!=4:
print('3argumentswererequiredbutonlyfind'+str(len(sys.argv)-1)+'!')
exit()
category=sys.argv[1]
try:
page_start=[int(sys.argv[2])]
page_end=int(sys.argv[3])
except:
print('Thesecondandthirdargumentsmustbeanumberbutnotastring!')
exit()иҝҷйҮҢйҖҡиҝҮиҺ·еҸ–е‘Ҫд»ӨиЎҢеҸӮж•°пјҢжҢҮе®ҡдәҶдёүдёӘеёёйҮҸcategory, page_startе’Ңpage_endпјҢеҲҶеҲ«еҜ№еә”зқҖеЈҒзәёеҲҶзұ»пјҢиө·е§ӢйЎөйЎөз ҒпјҢз»ҲжӯўйЎөйЎөз ҒгҖӮ
дёәдәҶж–№дҫҝиө·и§ҒпјҢеҶҚе®ҡд№үдёӨдёӘurlзӣёе…ізҡ„еёёйҮҸпјҡ
PAGE_DOMAIN='http://wallpaperswide.com'
PAGE_URL='http://wallpaperswide.com/'+category+'-desktop-wallpapers/page/'
жҺҘдёӢжқҘе°ұеҸҜд»Ҙж„үеҝ«ең°иҝӣиЎҢжү№йҮҸж“ҚдҪңдәҶпјҢеңЁжӯӨд№ӢеүҚжҲ‘们жқҘе®ҡд№үдёҖдёӘstart()еҗҜеҠЁеҮҪж•°пјҡ
defstart():
ifpage_start[0]<=page_end:
print('Preparingtodownloadthe'+str(page_start[0])+'pageofallthe"'+category+'"wallpapers...')
PAGE_SOURCE=visit_page(PAGE_URL+str(page_start[0]))
WALLPAPER_LINKS=get_paper_link(PAGE_SOURCE)
page_start[0]=page_start[0]+1
forindex,linkinenumerate(WALLPAPER_LINKS):
download_wallpaper(link,index,len(WALLPAPER_LINKS),start)然еҗҺжҠҠд№ӢеүҚзҡ„download_wallpaperеҮҪж•°еҶҚж”№еҶҷдёҖдёӢпјҡ
defdownload_wallpaper(link,index,total,callback):
wallpaper_source=visit_page(PAGE_DOMAIN+link)
wallpaper_size_links=wallpaper_source.select('#wallpaper-resolutions>a')
size_list=[]
forlinkinwallpaper_size_links:
href=link.get('href')
size_list.append({
'size':eval(link.get_text().replace('x','*')),
'name':href.replace('/download/',''),
'url':href
})
biggest_one=max(size_list,key=lambdaitem:item['size'])
print('Downloadingthe'+str(index+1)+'/'+str(total)+'wallpaper:'+biggest_one['name'])
result=requests.get(PAGE_DOMAIN+biggest_one['url'])
ifresult.status_code==200:
open('wallpapers/'+biggest_one['name'],'wb').write(result.content)
ifindex+1==total:
print('Downloadcompleted!\n\n')
callback()жңҖеҗҺжҢҮе®ҡдёҖдёӢеҗҜеҠЁи§„еҲҷпјҡ
if__name__=='__main__':
start()
иҝҗиЎҢйЎ№зӣ®
еңЁе‘Ҫд»ӨиЎҢиҫ“е…ҘеҰӮдёӢд»Јз ҒејҖе§ӢжөӢиҜ•пјҡ
python3download.pyaero12
然еҗҺеҸҜд»ҘзңӢеҲ°дёӢеҲ—иҫ“еҮәпјҡ
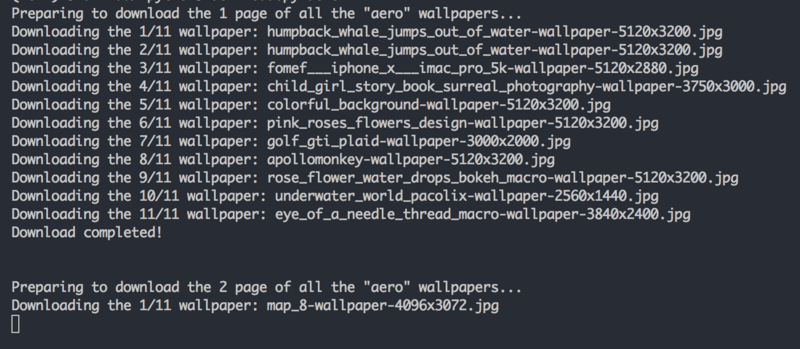
жӢҝcharlesжҠ“дёҖдёӢеҢ…пјҢеҸҜд»ҘзңӢеҲ°жӯЈеңЁи„ҡжң¬жӯЈеңЁе№ізЁіең°иҝҗиЎҢдёӯпјҡ
д»ҘдёҠе°ұжҳҜе…ідәҺвҖңpythonжҖҺд№Ҳе®һзҺ°еЈҒзәёжү№йҮҸдёӢиҪҪвҖқиҝҷзҜҮж–Үз« зҡ„еҶ…е®№пјҢзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢиӢҘжғідәҶи§ЈжӣҙеӨҡзӣёе…ізҡ„зҹҘиҜҶеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





