hadoop中Yarn如何使用,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
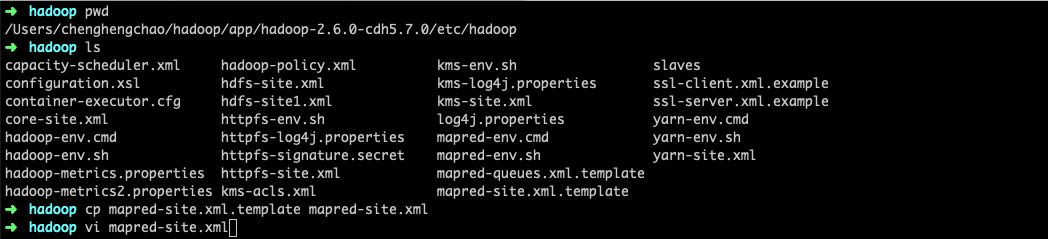
1.mapred-site.xml配置
进入相应的文件夹下编辑mapred-site.xml文件,添加mapreduce.framework属性即可。
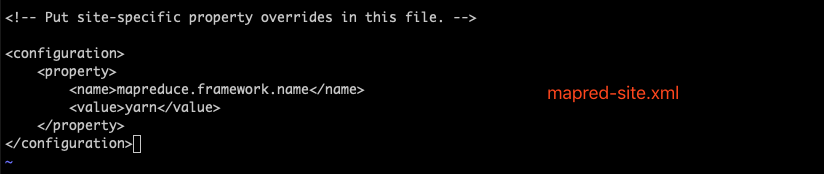

同样的,在yarn-site.xml中添加nodemanager的服务即可。
3.启动yarn相关进程并验证是否启动成功
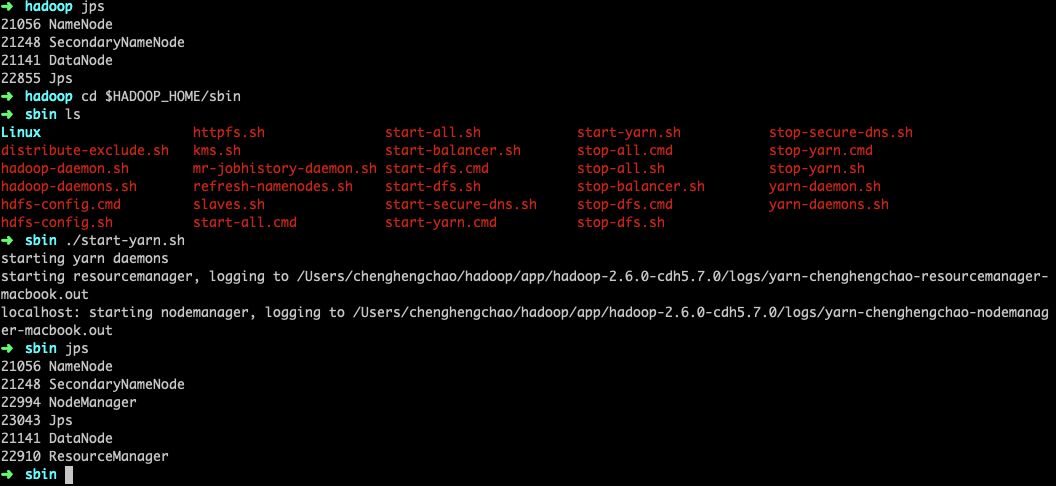
./start-yarn.sh #在sbin目录下执行该命令可以启动yarn# 注意在这之前要先启动HDFS,从控制台的输出中可以看出,# 启动了resourcemanager和nodemanager进程,jps验证也输出了相应的进程号。# 启动之后可以通过访问http://localhost:8088来访问yarn的管理界面。
./stop-yarn.sh #停止yarn相关进程
4.在yarn上运行hadoop示例程序


与前文一样,我们依然运行hadoop自带jar包例子中计算PI的程序。此处有几点需要说明。
1)web页面可以随时跟踪任务的执行状态,刚提交时是running,执行结束后会变成finished。如上图所示。
2)配置了yarn之后,会在计算时链接yarn的服务。从控制台输出中我们可以看到连接了ResourceManger。ResourceManager就是yarn的资源管理器。
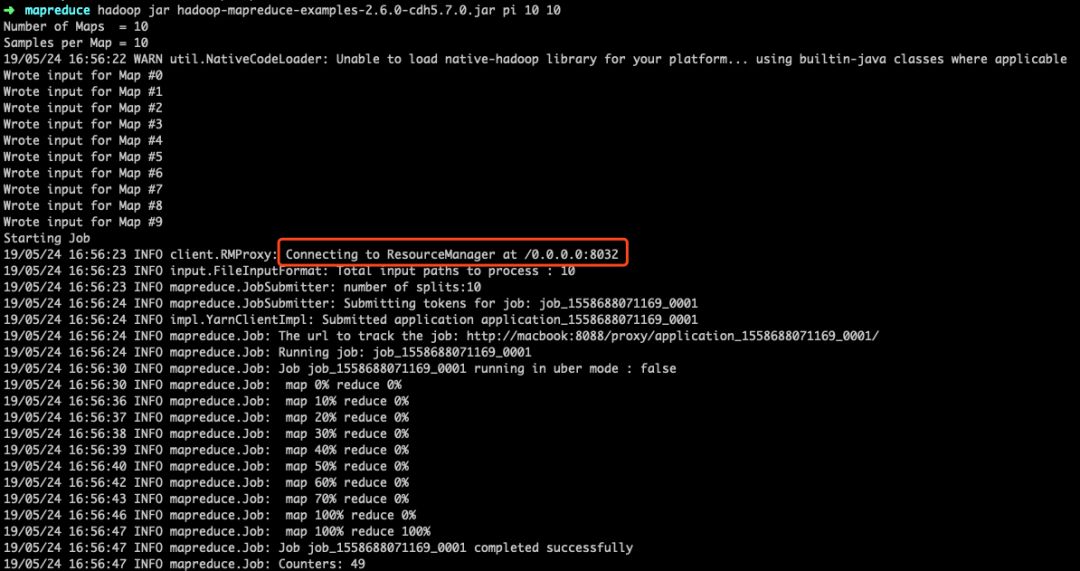
3)对比没有配置yarn之前的控制台上输出。可以看出配置yarn之后的日志更简洁。配置之前的(部分)日志见下图,配置之后的(部分)日志见上图。配置之前日志信息告诉我们,执行的是一个MapReduce过程,有map task,reduce task等。而配置之后,只有mapreduce job。可以理解为是运行在yarn之上的一个map reduce作业。配置之后运行时间虽然不一定快,但yarn的统一管理对整个集群来讲是更优化的。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





