RNN如何训练并预测时序信号,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
上期我们一起用RNN做了一个简单的手写字分类器,
今天我们一起学习下RNN是如何训练并预测时序信号的,比如股票价格,温度,脑电波等。
每一个训练样本是从时序信号中随机选择20个连续的值,训练样本相对应的目标是一个往下一个时间的方向平移了一个step之后的20个连续值,也就是除了最后一个值不一样,前面的值和训练样本的后19个都一样的一个序列。如下图: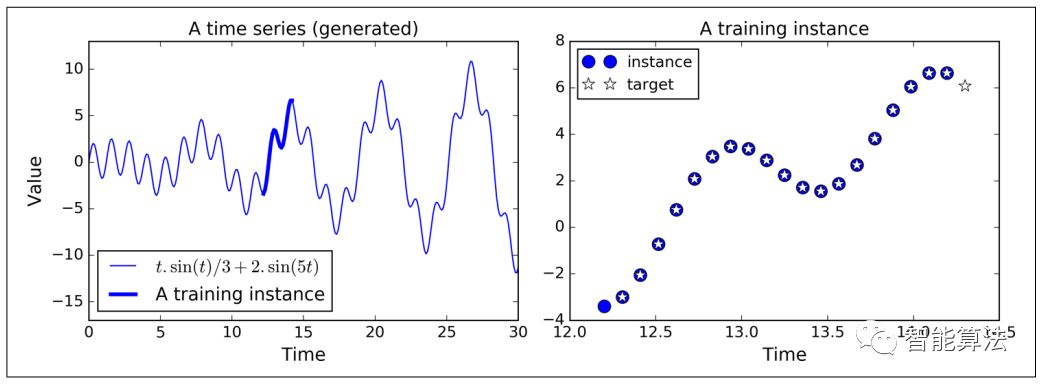 首先,我们创建一个RNN网络,它包括 100个循环神经元,由于训练样本的长度为20,所以我们将其展开为20个时间片段。每一个输入包含一个特征值(那一时刻的值)。同样,目标也包含20个输入,代码如下,和之前的差不多:
首先,我们创建一个RNN网络,它包括 100个循环神经元,由于训练样本的长度为20,所以我们将其展开为20个时间片段。每一个输入包含一个特征值(那一时刻的值)。同样,目标也包含20个输入,代码如下,和之前的差不多:
n_steps = 20n_inputs = 1n_neurons = 100n_outputs = 1X = tf.placeholder(tf.float32, [None, n_steps, n_inputs])y = tf.placeholder(tf.float32, [None, n_steps, n_outputs])cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons, activation=tf.nn.relu)outputs, states = tf.nn.dynamic_rnn(cell, X, dtype=tf.float32)在每一个时刻,我们都有一个size为100的输出向量,但是实际上,我们需要的是一个输出值。最简单的方法就是用一个包装器(Out putProjectionWrapper)把一个循环神经元包装起来。包装器工作起来类似一个循环神经元,但是叠加了其他功能。比如它在循环神经元的输出地方,增加了一个线性神经元的全连接层(这并不影响循环神经元的状态)。所有全连接层神经元共享同样的权重和偏置。如下图: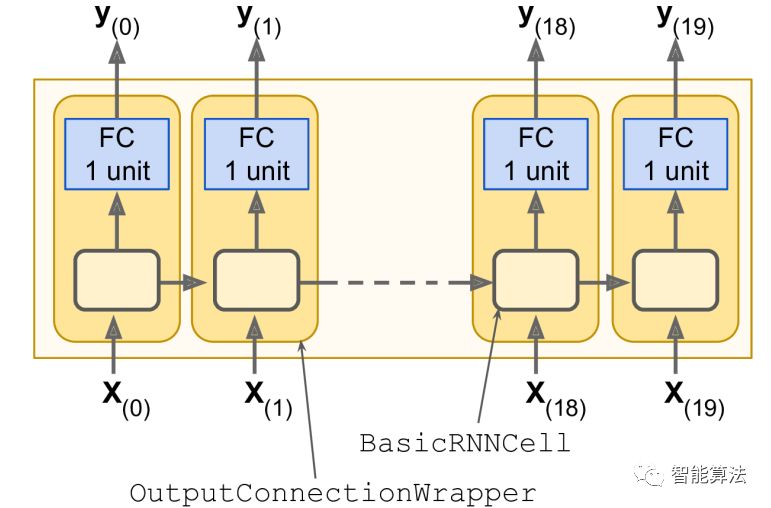
包装一个循环神经元相当简单,只需要微调一下之前的代码就可以将一个BasicRNNCell转换成OutputProjectionWrapper,如下:
cell = tf.contrib.rnn.OutputProjectionWrapper( tf.contrib.rnn.BasicRNNCell(num_units=n_neurons, activation=tf.nn.relu), output_size=n_outputs)到目前为止,我们可以来定义损失函数了,跟之前我们做回归一样,这里用均方差(MSE)。接下来再创建一个优化器,这里选择Adam优化器。如何选择优化器,见之前文章:
深度学习算法(第5期)----深度学习中的优化器选择
learning_rate = 0.001loss = tf.reduce_mean(tf.square(outputs - y))optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)training_op = optimizer.minimize(loss)init = tf.global_variables_initializer()接下来就是执行阶段:
n_iterations = 10000batch_size = 50with tf.Session() as sess: init.run() for iteration in range(n_iterations): X_batch, y_batch = [...] # fetch the next training batch sess.run(training_op, feed_dict={X: X_batch, y: y_batch}) if iteration % 100 == 0: mse = loss.eval(feed_dict={X: X_batch, y: y_batch}) print(iteration, "\tMSE:", mse)输出结果如下:
0 MSE: 379.586100 MSE: 14.58426200 MSE: 7.14066300 MSE: 3.98528400 MSE: 2.00254[...]一旦模型训练好之后,就可以用它来去预测了:
X_new = [...] # New sequencesy_pred = sess.run(outputs, feed_dict={X: X_new})下图显示了,上面的代码训练1000次迭代之后,模型的预测结果: 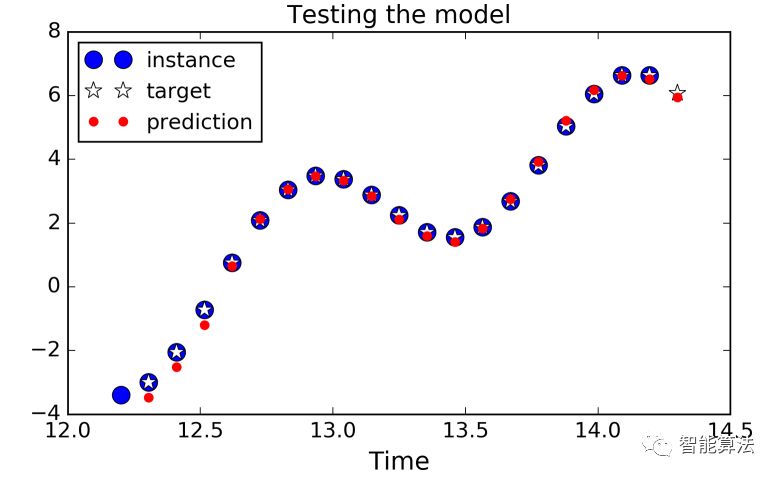 尽管用OutputProjectionWrapper是将RNN的输出序列降维到一个值的最简单的方法,但它并不是效率最高的。这里有一个技巧,可以更加高效:先将RNN输出的shape从[batch_size, n_steps, n_neurons]转换成[batch_size * n_steps, n_neurons],然后用一个有合适size的全连接层,输出一个[batch_size * n_steps, n_outputs]的tensor,最后将该tensor转为[batch_size, n_steps, n_outputs]。如下图:
尽管用OutputProjectionWrapper是将RNN的输出序列降维到一个值的最简单的方法,但它并不是效率最高的。这里有一个技巧,可以更加高效:先将RNN输出的shape从[batch_size, n_steps, n_neurons]转换成[batch_size * n_steps, n_neurons],然后用一个有合适size的全连接层,输出一个[batch_size * n_steps, n_outputs]的tensor,最后将该tensor转为[batch_size, n_steps, n_outputs]。如下图: 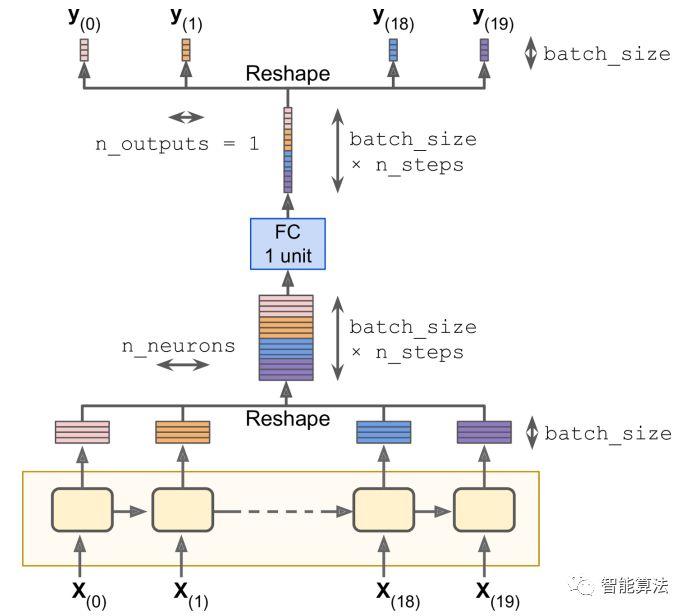 该方案实施起来,并不难,这里不需要OutputProjectionWrapper包装器了,只需要BasicRNNCell,如下:
该方案实施起来,并不难,这里不需要OutputProjectionWrapper包装器了,只需要BasicRNNCell,如下:
cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons, activation=tf.nn.relu)rnn_outputs, states = tf.nn.dynamic_rnn(cell, X, dtype=tf.float32)然后,我们对结果进行reshape,全连接层,再reshape,如下:
stacked_rnn_outputs = tf.reshape(rnn_outputs, [-1, n_neurons])stacked_outputs = fully_connected(stacked_rnn_outputs, n_outputs, activation_fn=None)outputs = tf.reshape(stacked_outputs, [-1, n_steps, n_outputs])接下来的代码和之前的一样了,由于这次只用了一个全连接层,所以跟之前相比,速度方面提升了不少。
关于RNN如何训练并预测时序信号问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4584682/blog/4390570



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



