еҰӮдҪ•йҳІжӯўelasticsearchзҡ„и„‘иЈӮй—®йўҳ
еҰӮдҪ•йҳІжӯўelasticsearchзҡ„и„‘иЈӮй—®йўҳпјҢй’ҲеҜ№иҝҷдёӘй—®йўҳпјҢиҝҷзҜҮж–Үз« иҜҰз»Ҷд»Ӣз»ҚдәҶзӣёеҜ№еә”зҡ„еҲҶжһҗе’Ңи§Јзӯ”пјҢеёҢжңӣеҸҜд»Ҙеё®еҠ©жӣҙеӨҡжғіи§ЈеҶіиҝҷдёӘй—®йўҳзҡ„е°ҸдјҷдјҙжүҫеҲ°жӣҙз®ҖеҚ•жҳ“иЎҢзҡ„ж–№жі•гҖӮ
д»Җд№ҲжҳҜи„‘иЈӮпјҹ
и®©жҲ‘们зңӢдёҖдёӘжңүдёӨдёӘиҠӮзӮ№зҡ„elasticsearchйӣҶзҫӨзҡ„з®ҖеҚ•жғ…еҶөгҖӮйӣҶзҫӨз»ҙжҠӨдёҖдёӘеҚ•дёӘзҙўеј•е№¶жңүдёҖдёӘеҲҶзүҮе’ҢдёҖдёӘеӨҚеҲ¶иҠӮзӮ№гҖӮиҠӮзӮ№1еңЁеҗҜеҠЁж—¶иў«йҖүдёҫдёәдё»иҠӮзӮ№е№¶дҝқеӯҳдё»еҲҶзүҮпјҲеңЁдёӢйқўзҡ„schemaйҮҢж Үи®°дёә0PпјүпјҢиҖҢиҠӮзӮ№2дҝқеӯҳеӨҚеҲ¶еҲҶзүҮпјҲ0Rпјү
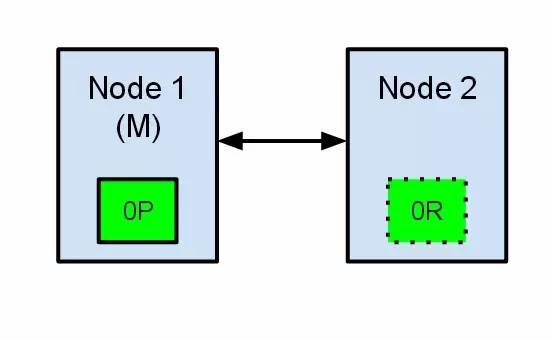
зҺ°еңЁпјҢеҰӮжһңеңЁдёӨдёӘиҠӮзӮ№д№Ӣй—ҙзҡ„йҖҡи®Ҝдёӯж–ӯдәҶпјҢдјҡеҸ‘з”ҹд»Җд№Ҳпјҹз”ұдәҺзҪ‘з»ңй—®йўҳжҲ–еҸӘжҳҜеӣ дёәе…¶дёӯдёҖдёӘиҠӮзӮ№ж— е“Қеә”пјҲдҫӢеҰӮstop-the-worldеһғеңҫеӣһ收пјү,иҝҷжҳҜжңүеҸҜиғҪеҸ‘з”ҹзҡ„гҖӮ
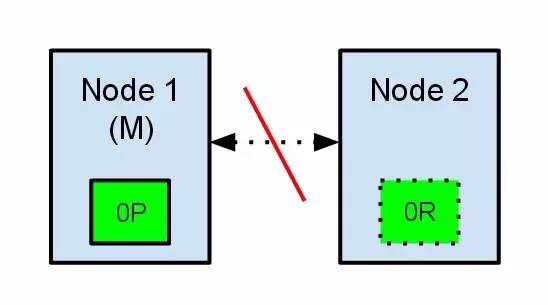
дёӨдёӘиҠӮзӮ№йғҪзӣёдҝЎеҜ№ж–№е·Із»ҸжҢӮдәҶгҖӮиҠӮзӮ№1дёҚйңҖиҰҒеҒҡд»Җд№ҲпјҢеӣ дёәе®ғжң¬жқҘе°ұиў«йҖүдёҫдёәдё»иҠӮзӮ№гҖӮдҪҶжҳҜиҠӮзӮ№2дјҡиҮӘеҠЁйҖүдёҫе®ғиҮӘе·ұдёәдё»иҠӮзӮ№пјҢеӣ дёәе®ғзӣёдҝЎйӣҶзҫӨзҡ„дёҖйғЁеҲҶжІЎжңүдё»иҠӮзӮ№дәҶгҖӮеңЁelasticsearchйӣҶзҫӨпјҢжҳҜжңүдё»иҠӮзӮ№жқҘеҶіе®ҡе°ҶеҲҶзүҮе№іеқҮзҡ„еҲҶеёғеҲ°иҠӮзӮ№дёҠзҡ„гҖӮиҠӮзӮ№2дҝқеӯҳзҡ„жҳҜеӨҚеҲ¶еҲҶзүҮпјҢдҪҶе®ғзӣёдҝЎдё»иҠӮзӮ№дёҚеҸҜз”ЁдәҶгҖӮжүҖд»Ҙе®ғдјҡиҮӘеҠЁжҸҗеҚҮеӨҚеҲ¶иҠӮзӮ№дёәдё»иҠӮзӮ№гҖӮ
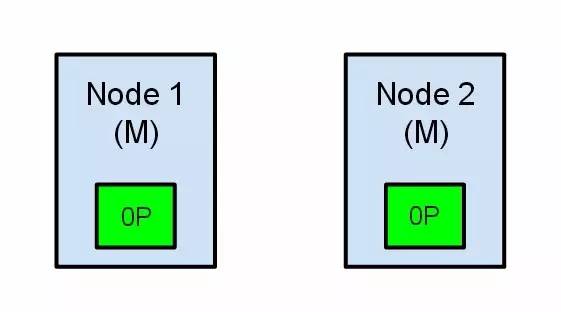
зҺ°еңЁжҲ‘们зҡ„йӣҶзҫӨеңЁдёҖдёӘдёҚдёҖиҮҙзҡ„зҠ¶жҖҒдәҶгҖӮжү“еңЁиҠӮзӮ№1дёҠзҡ„зҙўеј•иҜ·жұӮдјҡе°Ҷзҙўеј•ж•°жҚ®еҲҶй…ҚеңЁдё»иҠӮзӮ№пјҢеҗҢж—¶жү“еңЁиҠӮзӮ№2зҡ„иҜ·жұӮдјҡе°Ҷзҙўеј•ж•°жҚ®ж”ҫеңЁеҲҶзүҮдёҠгҖӮеңЁиҝҷз§Қжғ…еҶөдёӢпјҢеҲҶзүҮзҡ„дёӨд»Ҫж•°жҚ®еҲҶејҖдәҶпјҢеҰӮжһңдёҚеҒҡдёҖдёӘе…ЁйҮҸзҡ„йҮҚзҙўеј•еҫҲйҡҫеҜ№е®ғ们иҝӣиЎҢйҮҚжҺ’еәҸгҖӮеңЁжӣҙеқҸзҡ„жғ…еҶөдёӢпјҢдёҖдёӘеҜ№йӣҶзҫӨж— ж„ҹзҹҘзҡ„зҙўеј•е®ўжҲ·з«ҜпјҲдҫӢеҰӮпјҢдҪҝз”ЁRESTжҺҘеҸЈзҡ„пјү,иҝҷдёӘй—®йўҳйқһеёёйҖҸжҳҺйҡҫд»ҘеҸ‘зҺ°пјҢж— и®әе“ӘдёӘиҠӮзӮ№иў«е‘Ҫдёӯзҙўеј•иҜ·жұӮд»Қ然еңЁжҜҸж¬ЎйғҪдјҡжҲҗеҠҹе®ҢжҲҗгҖӮй—®йўҳеҸӘжңүеңЁжҗңзҙўж•°жҚ®ж—¶жүҚдјҡиў«йҡҗзәҰеҸ‘зҺ°пјҡеҸ–еҶідәҺжҗңзҙўиҜ·жұӮе‘ҪдёӯдәҶе“ӘдёӘиҠӮзӮ№пјҢз»“жһңйғҪдјҡдёҚеҗҢгҖӮ
еҰӮдҪ•йҒҝе…Қи„‘иЈӮй—®йўҳ
elasticsearchзҡ„й»ҳи®Өй…ҚзҪ®еҫҲеҘҪгҖӮдҪҶжҳҜelasticsearchйЎ№зӣ®з»„дёҚеҸҜиғҪзҹҘйҒ“дҪ зҡ„зү№е®ҡеңәжҷҜйҮҢзҡ„жүҖжңүз»ҶиҠӮгҖӮиҝҷе°ұжҳҜдёәд»Җд№Ҳжҹҗдәӣй…ҚзҪ®еҸӮж•°йңҖиҰҒж”№жҲҗйҖӮеҗҲдҪ зҡ„йңҖжұӮзҡ„еҺҹеӣ гҖӮиҝҷзҜҮеҚҡж–ҮйҮҢжүҖжңүжҸҗеҲ°зҡ„еҸӮж•°йғҪеҸҜд»ҘеңЁдҪ elasticsearchе®үиЈ…ең°еқҖзҡ„configзӣ®еҪ•дёӯзҡ„elasticsearch.ymlдёӯжӣҙж”№гҖӮ
иҰҒйў„йҳІи„‘иЈӮй—®йўҳпјҢжҲ‘们йңҖиҰҒзңӢзҡ„дёҖдёӘеҸӮж•°е°ұжҳҜ discovery.zen.minimum_master_nodesгҖӮиҝҷдёӘеҸӮж•°еҶіе®ҡдәҶеңЁйҖүдё»иҝҮзЁӢдёӯйңҖиҰҒ жңүеӨҡе°‘дёӘиҠӮзӮ№йҖҡдҝЎгҖӮзјәзңҒй…ҚзҪ®жҳҜ1.дёҖдёӘеҹәжң¬зҡ„еҺҹеҲҷжҳҜиҝҷйҮҢйңҖиҰҒи®ҫзҪ®жҲҗ N/2+1, NжҳҜйӣҶзҫӨдёӯиҠӮзӮ№зҡ„ж•°йҮҸгҖӮдҫӢеҰӮеңЁдёҖдёӘдёүиҠӮзӮ№зҡ„йӣҶзҫӨдёӯпјҢ minimum_master_nodesеә”иҜҘиў«и®ҫдёә 3/2 + 1 = 2(еӣӣиҲҚдә”е…Ҙ)гҖӮ
и®©жҲ‘们жғіиұЎдёӢд№ӢеүҚзҡ„жғ…еҶөдёӢеҰӮжһңжҲ‘们жҠҠ discovery.zen.minimum_master_nodes и®ҫзҪ®жҲҗ 2пјҲ2/2 + 1пјүгҖӮеҪ“дёӨдёӘиҠӮзӮ№зҡ„йҖҡдҝЎеӨұиҙҘдәҶпјҢиҠӮзӮ№1дјҡеӨұеҺ»е®ғзҡ„дё»зҠ¶жҖҒпјҢеҗҢж—¶иҠӮзӮ№2д№ҹдёҚдјҡиў«йҖүдёҫдёәдё»гҖӮжІЎжңүдёҖдёӘиҠӮзӮ№дјҡжҺҘеҸ—зҙўеј•жҲ–жҗңзҙўзҡ„иҜ·жұӮпјҢи®©жүҖжңүзҡ„е®ўжҲ·з«Ҝ马дёҠеҸ‘зҺ°иҝҷдёӘй—®йўҳгҖӮиҖҢдё”жІЎжңүдёҖдёӘеҲҶзүҮдјҡеӨ„дәҺдёҚдёҖиҮҙзҡ„зҠ¶жҖҒгҖӮ
жҲ‘们еҸҜд»Ҙи°ғзҡ„еҸҰдёҖдёӘеҸӮж•°жҳҜ discovery.zen.ping.timeoutгҖӮе®ғзҡ„й»ҳи®ӨеҖјжҳҜ3秒并且е®ғз”ЁжқҘеҶіе®ҡдёҖдёӘиҠӮзӮ№еңЁеҒҮи®ҫйӣҶзҫӨдёӯзҡ„еҸҰдёҖдёӘиҠӮзӮ№е“Қеә”еӨұиҙҘзҡ„жғ…еҶөж—¶зӯүеҫ…еӨҡд№…гҖӮеңЁдёҖдёӘж…ўйҖҹзҪ‘з»ңдёӯе°ҶиҝҷдёӘеҖји°ғзҡ„еӨ§дёҖзӮ№жҳҜдёӘдёҚй”ҷзҡ„дё»ж„ҸгҖӮиҝҷдёӘеҸӮж•°дёҚжӯўйҖӮз”ЁдәҺй«ҳзҪ‘з»ң延иҝҹпјҢиҝҳиғҪеңЁдёҖдёӘиҠӮзӮ№и¶…иҪҪе“Қеә”еҫҲж…ўж—¶иө·дҪңз”ЁгҖӮ
дёӨиҠӮзӮ№йӣҶзҫӨпјҹ
еҰӮжһңдҪ и§үеҫ—пјҲжҲ–зӣҙи§үдёҠпјүеңЁдёҖдёӘдёӨиҠӮзӮ№зҡ„йӣҶзҫӨдёӯжҠҠminimum_master_nodesеҸӮж•°и®ҫжҲҗ2жҳҜй”ҷзҡ„пјҢйӮЈе°ұеҜ№дәҶгҖӮеңЁиҝҷз§Қжғ…еҶөдёӢеҰӮжһңдёҖдёӘиҠӮзӮ№жҢӮдәҶпјҢйӮЈж•ҙдёӘйӣҶзҫӨе°ұйғҪжҢӮдәҶгҖӮе°Ҫз®Ўиҝҷжқңз»қдәҶи„‘иЈӮзҡ„еҸҜиғҪжҖ§пјҢдҪҶиҝҷдҪҝelasticsearchеҸҰдёҖдёӘеҘҪзү№жҖ§ - з”ЁеӨҚеҲ¶еҲҶзүҮжқҘжһ„е»әй«ҳеҸҜз”ЁжҖ§ еӨұж•ҲдәҶгҖӮ
еҰӮжһңдҪ еҲҡејҖе§ӢдҪҝз”ЁelasticsearchпјҢе»әи®®й…ҚзҪ®дёҖдёӘ3иҠӮзӮ№йӣҶзҫӨгҖӮиҝҷж ·дҪ еҸҜд»Ҙи®ҫзҪ®minimum_master_nodesдёә2пјҢеҮҸе°‘дәҶи„‘иЈӮзҡ„еҸҜиғҪжҖ§пјҢдҪҶд»Қ然дҝқжҢҒдәҶй«ҳеҸҜз”Ёзҡ„дјҳзӮ№пјҡдҪ еҸҜд»ҘжүҝеҸ—дёҖдёӘиҠӮзӮ№еӨұж•ҲдҪҶйӣҶзҫӨиҝҳжҳҜжӯЈеёёиҝҗиЎҢзҡ„гҖӮ
дҪҶеҰӮжһңе·Із»ҸиҝҗиЎҢдәҶдёҖдёӘдёӨиҠӮзӮ№elasticsearchйӣҶзҫӨжҖҺд№ҲеҠһпјҹеҸҜд»ҘйҖүжӢ©дёәдәҶдҝқжҢҒй«ҳеҸҜз”ЁиҖҢеҝҚеҸ—и„‘иЈӮзҡ„еҸҜиғҪжҖ§пјҢжҲ–иҖ…йҖүжӢ©дёәдәҶйҳІжӯўи„‘иЈӮиҖҢйҖүжӢ©й«ҳеҸҜз”ЁжҖ§гҖӮдёәдәҶйҒҝе…Қиҝҷз§ҚеҰҘеҚҸпјҢжңҖеҘҪзҡ„йҖүжӢ©жҳҜз»ҷйӣҶзҫӨж·»еҠ дёҖдёӘиҠӮзӮ№гҖӮиҝҷеҗ¬иө·жқҘеҫҲжһҒз«ҜпјҢдҪҶ并дёҚжҳҜгҖӮеҜ№дәҺжҜҸдёҖдёӘelasticsearchиҠӮзӮ№дҪ еҸҜд»Ҙи®ҫзҪ® node.data еҸӮж•°жқҘйҖүжӢ©иҝҷдёӘиҠӮзӮ№жҳҜеҗҰйңҖиҰҒдҝқеӯҳж•°жҚ®гҖӮзјәзңҒеҖјжҳҜвҖңtrueвҖқпјҢж„ҸжҖқжҳҜй»ҳи®ӨжҜҸдёӘelasticsearchиҠӮзӮ№еҗҢж—¶д№ҹдјҡдҪңдёәдёҖдёӘж•°жҚ®иҠӮзӮ№гҖӮ
еңЁдёҖдёӘдёӨиҠӮзӮ№йӣҶзҫӨпјҢдҪ еҸҜд»Ҙж·»еҠ дёҖдёӘж–°иҠӮзӮ№е№¶жҠҠ node.data еҸӮж•°и®ҫзҪ®дёәвҖңfalseвҖқгҖӮиҝҷж ·иҝҷдёӘиҠӮзӮ№дёҚдјҡдҝқеӯҳд»»дҪ•еҲҶзүҮпјҢдҪҶе®ғд»Қ然еҸҜд»Ҙиў«йҖүдёәдё»пјҲй»ҳи®ӨиЎҢдёәпјүгҖӮеӣ дёәиҝҷдёӘиҠӮзӮ№жҳҜдёҖдёӘж— ж•°жҚ®иҠӮзӮ№пјҢжүҖд»Ҙе®ғеҸҜд»Ҙж”ҫеңЁдёҖеҸ°дҫҝе®ңжңҚеҠЎеҷЁдёҠгҖӮзҺ°еңЁдҪ е°ұжңүдәҶдёҖдёӘдёүиҠӮзӮ№зҡ„йӣҶзҫӨпјҢеҸҜд»Ҙе®үе…Ёзҡ„жҠҠminimum_master_nodesи®ҫзҪ®дёә2пјҢйҒҝе…Қи„‘иЈӮиҖҢдё”д»Қ然еҸҜд»ҘдёўеӨұдёҖдёӘиҠӮзӮ№е№¶дё”дёҚдјҡдёўеӨұж•°жҚ®гҖӮ
и„‘иЈӮй—®йўҳеҫҲйҡҫиў«еҪ»еә•и§ЈеҶігҖӮеңЁelasticsearchзҡ„й—®йўҳеҲ—иЎЁйҮҢд»Қ然жңүе…ідәҺиҝҷдёӘзҡ„й—®йўҳ, жҸҸиҝ°дәҶеңЁдёҖдёӘжһҒз«Ҝжғ…еҶөдёӢжӯЈзЎ®и®ҫзҪ®дәҶminimum_master_nodesзҡ„еҸӮж•°ж—¶д»Қ然дә§з”ҹдәҶи„‘иЈӮй—®йўҳгҖӮelasticsearchйЎ№зӣ®з»„жӯЈеңЁиҮҙеҠӣдәҺејҖеҸ‘дёҖдёӘйҖүдё»з®—жі•зҡ„жӣҙеҘҪзҡ„е®һзҺ°пјҢдҪҶеҰӮжһңдҪ е·Із»ҸеңЁиҝҗиЎҢelasticsearchйӣҶзҫӨдәҶйӮЈд№ҲдҪ йңҖиҰҒзҹҘйҒ“иҝҷдёӘжҪңеңЁзҡ„й—®йўҳгҖӮ
еҰӮдҪ•е°Ҫеҝ«еҸ‘зҺ°иҝҷдёӘеҫҲйҮҚиҰҒгҖӮдёҖдёӘжҜ”иҫғз®ҖеҚ•зҡ„жЈҖжөӢй—®йўҳзҡ„ж–№ејҸжҳҜпјҢеҒҡдёҖдёӘеҜ№/_nodesдёӢжҜҸдёӘиҠӮзӮ№з»Ҳз«Ҝе“Қеә”зҡ„е®ҡжңҹжЈҖжҹҘгҖӮиҝҷдёӘз»Ҳз«Ҝиҝ”еӣһдёҖдёӘжүҖжңүйӣҶзҫӨиҠӮзӮ№зҠ¶жҖҒзҡ„зҹӯжҠҘе‘ҠгҖӮеҰӮжһңжңүдёӨдёӘиҠӮзӮ№жҠҘе‘ҠдәҶдёҚеҗҢзҡ„йӣҶзҫӨеҲ—иЎЁпјҢйӮЈд№ҲиҝҷжҳҜдёҖдёӘдә§з”ҹи„‘иЈӮзҠ¶еҶөзҡ„жҳҺжҳҫж Үеҝ—гҖӮ
е…ідәҺеҰӮдҪ•йҳІжӯўelasticsearchзҡ„и„‘иЈӮй—®йўҳй—®йўҳзҡ„и§Јзӯ”е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҰӮжһңдҪ иҝҳжңүеҫҲеӨҡз–‘жғ‘жІЎжңүи§ЈејҖпјҢеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“дәҶи§ЈжӣҙеӨҡзӣёе…ізҹҘиҜҶгҖӮ





