本文小编为大家详细介绍“ElasticSearch索引数据优化的方法”,内容详细,步骤清晰,细节处理妥当,希望这篇“ElasticSearch索引数据优化的方法”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。
1. 索引数据优化
搜索引擎(以ES为例),是将一个查询拆分为最细粒度的单位条件之后,按照单位条件检索倒排索引得到单位结果集,然后对所有单位结果取交集得到最终的查询结果,也就是说虽然一个查询看起来只返回了10条记录,但是有可能其中间结果是(100w)∩(100w)∩(100w)=10,所以看起来满足条件的结果很少,但是查询性能却上不去。
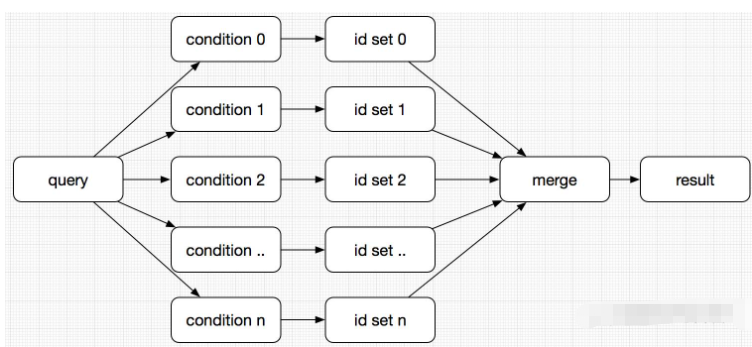
这时要优化性能,我们需要做的就是尽量减少中间结果集大小,让取交集的时间尽可能短:
冷热隔离
查询倒排表是搜索引擎在执行查询时必需要做的,单个条件得到的结果集(id set)越小,当然loop执行获取交集的时间越短,所以大致上查询性能与索引数据量的大小成正比。
当索引数据量变大之后,按照二八定律,80%的查询落在最热的20%数据上,那么将这20%数据单独放到一个热索引,可以有效减少单条件结果集大小,从而提高查询性能;
ElasticSearch也会利用缓存来提高排序性能,比如fielddata,如果一个查询命中了未缓存的冷字段,系统会自动加载该字段内容(fielddata)到内存,所以就冷查询来说,通常带排序的查询要远远慢于普通查询,如果做到冷热隔离,命中热索引的冷查询加载fielddata的时间会大大减少,就算是冷查询也能基本满足低rt的查询需求。
水平拆分
冷热隔离有时候并不一定能完美解决业务需求,比如店内搜索,商品编辑很多,冷热交替频繁,而且80%的店铺商品量都不大。
对于此类数据,有个明显的特点是所有的查询都带有店铺属性,也就是只查询单店铺内的数据,这时候就可以考虑索引水平拆分了,按照店铺维度将所有的商品数据拆分为n个子索引。
这样原本一次查询需要加载全部字段数据(fielddata),就可以变为只加载店铺所在的某个子索引的字段数据(1/n),所耗费的资源能下降几个数量级,另外单条件匹配倒排索引得到的结果集也可以缩小到原本的1/n,能够滤掉很多其它店铺的数据(对于本次查询来说就是废数据)。
当然拆分策略可以视具体的业务而定,比如也可以按照时间范围来拆分。
另外补充一点,之所以没有垂直拆分是因为搜索引擎没有办法做在线join操作,要实现join需要自己动手取不同索引的数据做交集,如果跨度范围大或者带了排序条件,那么跨索引的查询基本是无解。
引擎配置
配置调优一般是搜索引擎性能优化的第一步,这里又可以分为server配置和索引配置两方面:
server配置
Lucene系的搜索引擎都是跑在jvm上的,所以合适的jvm启动参数对搜索引擎的表现有着重要的影响,如果分配的heap内存很大则更是如此,这里我就抛砖引玉把我们目前用到的一些jvm参数列一下,理念也就是尽量控制garbage内存在ygc时就回收掉,控制临时的大对象不进入old区(当然优化查询让这些临时大对象少生成也是一方面,下文会讲到):
-XX:MaxGCPauseMillis=2000
-XX:+PrintGCDateStamps
-XX:+G1PrintHeapRegions
-XX:+UnlockDiagnosticVMOptions
-XX:+UnlockExperimentalVMOptions
-XX:+PrintAdaptiveSizePolicy
-XX:G1HeapRegionSize=32m
-XX:G1ReservePercent=15
-XX:InitiatingHeapOccupancyPercent=60
在集群规模扩大之后,将各个node按角色拆分为master/data/client也是需要做
的,将全集群的状态同步/选举过程等任务剥离到master,将结果聚合(内存开销很大)/客户端连接交互(http协议如果有大量短连接创建/销毁,开销也很大)等任务剥离到client,尽量减轻data node的负载(查询/索引执行过程都是data node负责的),以提高服务性能。
针对ElasticSearch,其缓存配置和breaker配置也需要根据业务应用场景调整,比如写多读少并且索引量比较大的场景可以适当降低filter cache大小,调高field data大小(尽量让加载到内存的字段内容保留,冷加载一次field data是有比较大开销的,而且失效的field data eviction也会加重gc的负担);
而读多写少并且索引量也比较小的场景就可以降低field data的大小,调高filter的比例(提高缓存复用率);
breaker配置最好写定比例,尽量让缓存不要在堆内存互相挤兑,避免加重gc负担。
索引配置
索引配置比较灵活,粒度也比较细,当我们查询索引时其实都是查询某个时间的一个快照数据,只有index searcher重载一次索引文件,这期间(两次reopen index searcher之间)对索引进行的操作才会可见,这段时间也叫做刷新时间(refresh_interval);
需要注意的是重载索引文件(reopen index searcher)的开销很大,所以一般搜索引擎都是提供近实时的查询服务,以减少重载索引文件的次数,降低系统负载,有个案例:曾经将一个索引的刷新时间从1s调整到5s,整个搜索响应时间从200ms降低到20ms以内,效果可见一斑。
字段配置是索引配置的一方面,简而言之就是能不索引的就不索引,能不存到引擎的就不存,也要避免出现大面积的稀疏数据分布,目的就是减少资源消耗/减小索引文件大小,以提高内存使用率,降低merge时间(索引文件需要定期merge,清理碎片文件);
有条件也可以指定查询routing,让某个查询能够直接命中特定的shard,而不必去所有shard收集数据,减少等待时间;
到5.x版本,ES还是可以配置一个索引包含多个type的,实际上同一个索引的多个type物理上是存储在同一个索引文件目录内,也就是共享同一批索引文件,仅仅是通过隐藏的_uid/_type字段来区分。
那么问题来了,如果某个type的数据量远远大于其他type,数据量最大的type就会成为其他type性能表现的瓶颈(merge受影响,如果字段不相同还会导致稀疏数据问题,浪费宝贵的mem资源)。
因此生产中我们是禁止一个索引包含多个type的,而在ES6.x版本预告中也表示7.0版本中将使用默认type,不再允许同一个索引配置多type了。
顺便提一句:多type在字段映射(mapping)上也有所限制,同名字段必须使用相同的类型 。
读到这里,这篇“ElasticSearch索引数据优化的方法”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





