本文小编为大家详细介绍“R语言数据可视化案例分析”,内容详细,步骤清晰,细节处理妥当,希望这篇“R语言数据可视化案例分析”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。
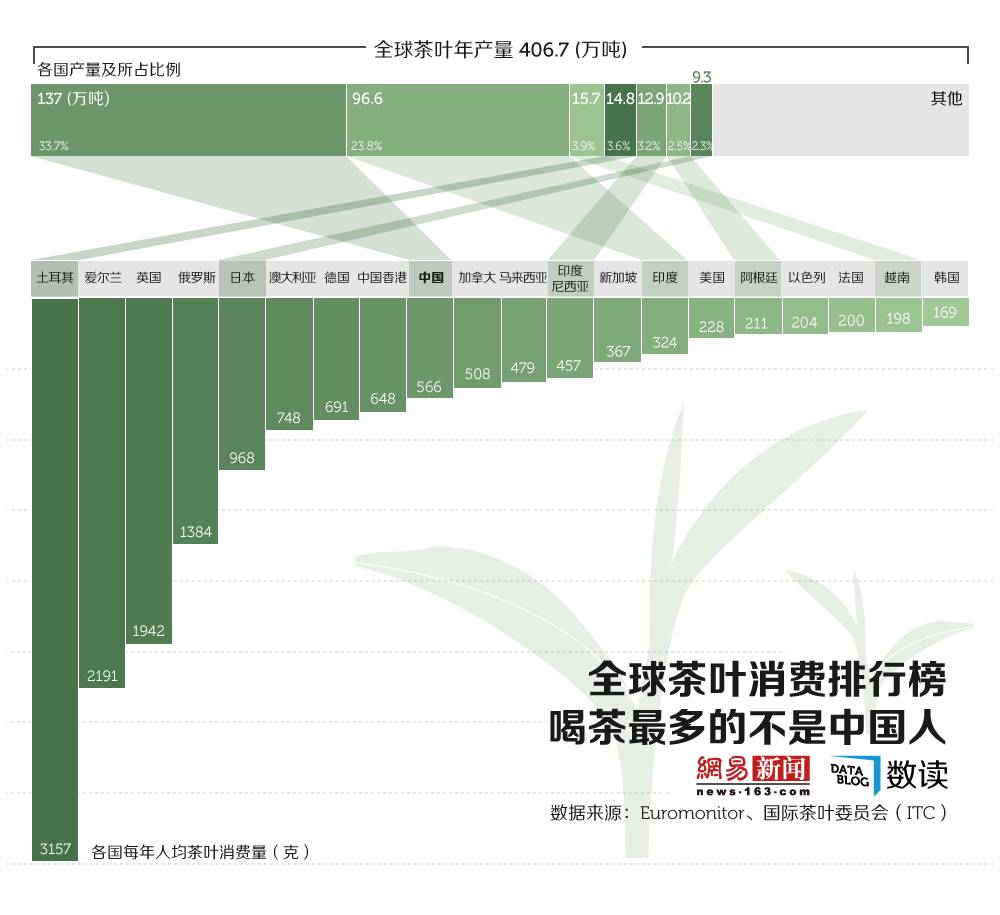
以下是该案例涉及到的扩展包:
library("plyr")
library("tidyr")
library("ggthemes")
library("sca")
library("dplyr")
library("showtext")
library("Cairo")
library("grid")
font.add("myfont","msyh.ttc")
font.add("myfzhzh","方正正粗黑简体.TTF")
我把该案例切割成了两部分来做:
(实际上如果放在一个图里做也是可以实现的,无非是多写一些代码罢了,但是涉及到颜色标度重复的问题,一时半会儿找不到解决方案,为了更加逼真的还原案例效果,我决定分开来做)。
原图中的下半部分(条形图)(以下简称模块1)
上半部分(堆积柱形图+连接带)(以下简称模块2)
导入数据源:
tea_data<-read.csv("D:/R/File/tea_data.csv",stringsAsFactors=FALSE,check.names=FALSE)
tea_data$State[12]<-"印度尼\n西亚"
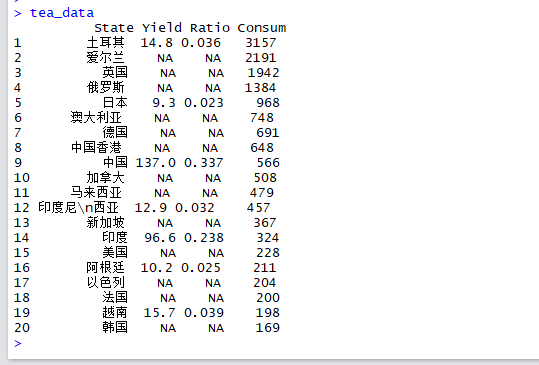
tea_bump是上半部分(模块2)中堆积柱形图的数据源,我没有使用传统的堆积柱形图去做,而是使用了矩形几何对象,所以数据源中需要指定X轴起始点,Y轴起始点。
tea_bump<-na.omit(tea_data[,c("State","Yield","Ratio")])
tea_bump<-arrange(tea_bump,-Yield)
other_Ratio<-1-sum(tea_bump$Ratio)
other_Yield<-sum(tea_bump$Yield)/sum(tea_bump$Ratio)-sum(tea_bump$Yield)
data1<-data.frame(State="其他",Yield=other_Yield,Ratio=other_Ratio)
tea_bump<-rbind(tea_bump,data1)
tea_bump$end<-cumsum(tea_bump$Yield)
tea_bump$start<-c(0,tea_bump$end[1:nrow(tea_bump)-1])
tea_bump$id<-1:nrow(tea_bump)
tea_bump<-merge(tea_bump,tea_data[,c("State","Consum")],by="State",all.x=TRUE)
tea_bump<-arrange(tea_bump,-Yield)
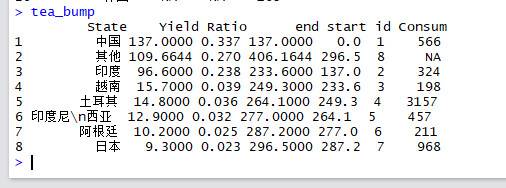
以下是下半部分柱形图的数据源,同样我也没有使用普通的柱形图几何对象去做,而是使用了范围线图(geom_linerange),这样可以节省调整步骤,但须额外设置线的起始点。
tea_bar<-tea_data[,c("State","Consum")]
tea_bar$id<-1:nrow(tea_bar)
colorpal<-ifelse(tea_data$State %in% tea_bump$State,"#B4BFB4","#E5E5E5")
library("ggplot2")
library("showtext")
library("Cairo")
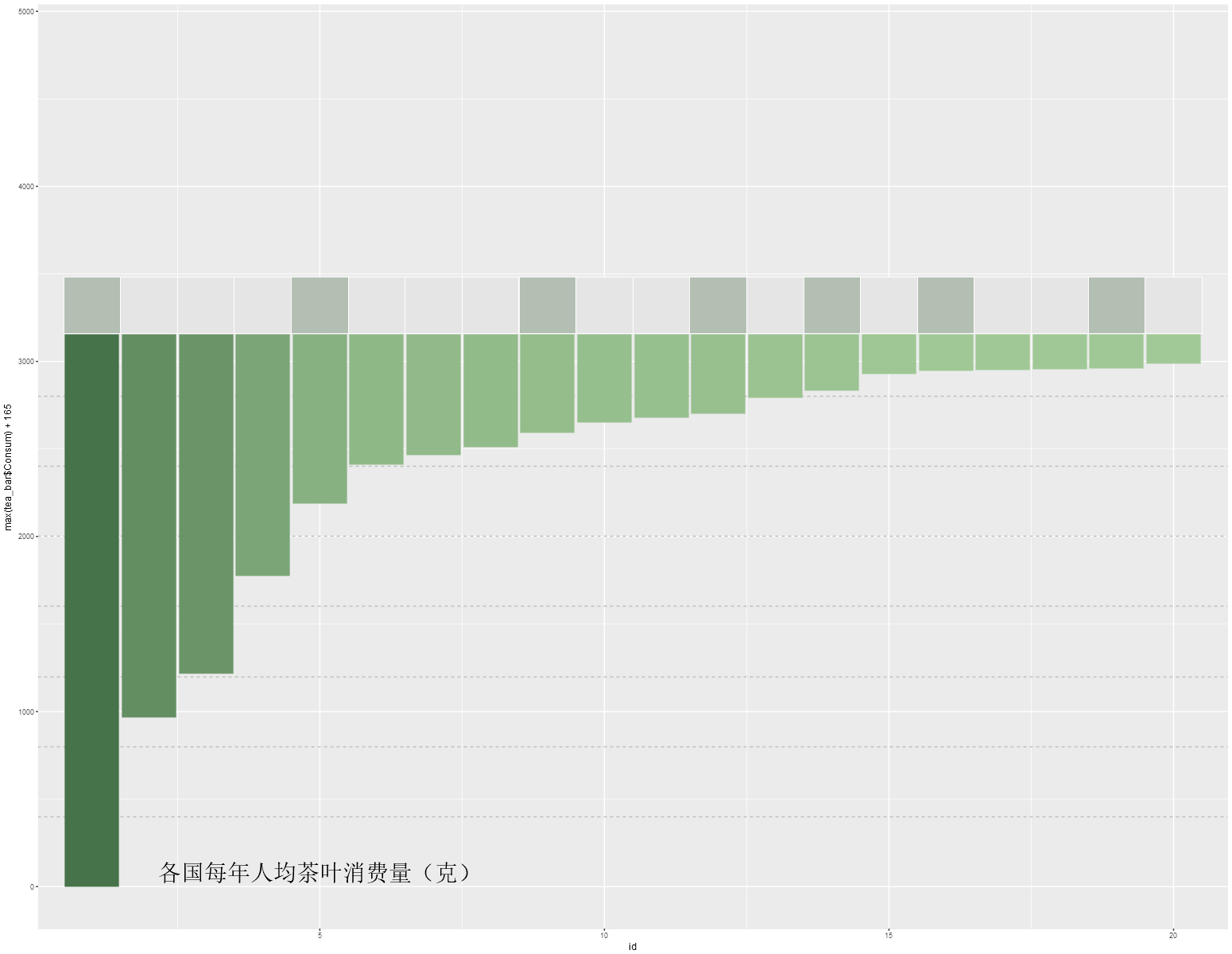
底部柱形图对象:
(因为需要拼图,所以图形对象要临时存储)
p1<-ggplot()+
geom_hline(aes(yintercept=1:7*400),colour="grey",linetype=2)+
geom_linerange(data=tea_bar,aes(x=id,ymin=max(tea_bar$Consum)-Consum,ymax=max(tea_bar$Consum),colour=Consum),size=24)+
geom_point(data=tea_bar,aes(x=id,y=max(tea_bar$Consum)+165,fill=colorpal),shape=22,colour="white",size=37.5)+
geom_text(data=tea_bar,aes(x=id,y=max(tea_bar$Consum)+165,label=State),size=6,family="myfont",vjust=.5)+
geom_text(data=tea_bar,aes(x=id,y=max(tea_bar$Consum)-Consum+80,label=Consum),size=6,family="myfont",vjust=0.5,colour="white")+
annotate("text",x =5,y=80,label="各国每年人均茶叶消费量(克)",family="myfzhzh",size=11,colour="#515551")+
ylim(0,4800)+
geom_linerange()+
guides(fill=FALSE,colour=FALSE)+
scale_colour_gradient(low="#A1C997",high="#47734A")+
scale_fill_manual(values=c("#B4BFB4","#E5E5E5"))+
theme_map(base_family="myfont") %+replace%
theme(
plot.margin=unit(c(0,1.5,0,1.5), "cm"),
)
以下数据是构造模块2辅助数据:
(上半部分堆积柱形图的下侧连接带数据)的辅助数据,我打算使用多边形几何对象了来模拟那些参差交错的连接带。这就意味着我要找到每一条带子,即四边形的四个拐点坐标,并按顺序排列。)
如果你看的不是很懂,实属正常,这种笨拙的想法,我也不知道是从哪里学来的。
tea_chord<-data.frame(State=tea_data$State)
tea_chord$id<-1:nrow(tea_chord)
tea_chord$mean<-sum(tea_bump$Yield)/nrow(tea_chord)
tea_chord$xend<-cumsum(tea_chord$mean)
tea_chord$xstart<-c(0,tea_chord$xend[1:nrow(tea_chord)-1])

tea_chord_data<-tea_chord[tea_chord$State %in% tea_bump$State,c("State","xstart","xend")]
tea_chord_data<-merge(tea_chord_data,tea_bump[tea_bump$State!="其他",c("State","start","end")],by="State")
tea_chord_data<-tea_chord_data[,c("State","start","end","xend","xstart")]
tea_chord_newdata<-data.frame(t(tea_chord_data),stringsAsFactors=FALSE)
names(tea_chord_newdata)<-tea_chord_data$State;tea_chord_newdata<-tea_chord_newdata[-1,]
rownames(tea_chord_newdata)<-NULL
tea_chord_newdata$order<-1:nrow(tea_chord_newdata)
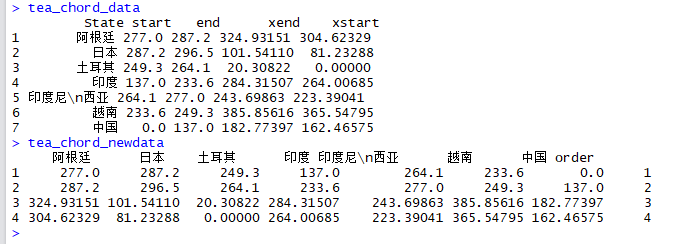
tea_chord_newdata_final<-gather(tea_chord_newdata,State,long,-order)
tea_chord_newdata_final$lat<-5
tea_chord_newdata_final$lat[tea_chord_newdata_final$order==3|tea_chord_newdata_final$order==4]<--5
tea_chord_newdata_final$long<-as.numeric(tea_chord_newdata_final$long)
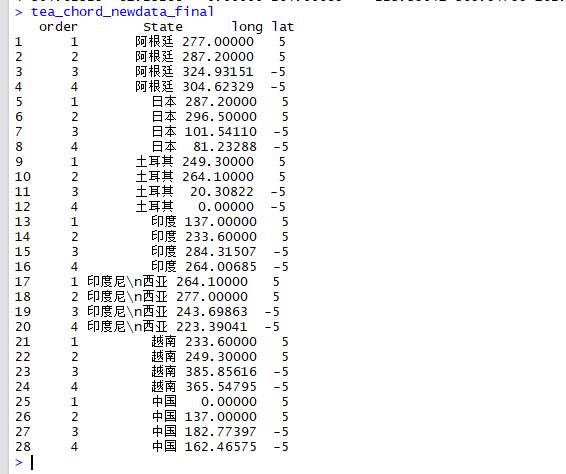
所以说上半部分的堆积柱形图(附加连接带)其实是用了两份不同的数据源模拟出来的。
以下是模块2的可视化代码部分:
(也需临时存储)
p2<-ggplot()+
geom_rect(data=tea_bump,aes(xmin=start,xmax=end,ymin=5,ymax=15,fill=Consum),colour="white")+
geom_polygon(data=tea_chord_newdata_final,aes(x=long,y=lat,group=State),fill="#B1C6B0",colour=NA,size=.25,alpha=.8)+
labs(title="全国茶叶年产量406.7(万吨)")+
geom_text(data=tea_bump[tea_bump$State!="其他",],aes(x=start+5.5,y=13,label=round(Yield,1)),size=5.5,family="myfont",vjust=0.5,colour="white")+
geom_text(data=tea_bump[tea_bump$State!="其他",],aes(x=start+6,y=7,label=percent(Ratio,d=1,sep="")),size=5.5,family="myfont",vjust=0.5,colour="white")+
scale_fill_gradient(low="#A1C997",high="#47734A",na.value="#E5E5E5",guide=FALSE)+
theme_map() %+replace%
theme(
plot.title=element_text(size=35,family="myfzhzh",hjust=.5)
)

有了上下两部分的对象,剩下的就好办了,无非就是拼接起来嘛,但是拼接的过程相当考验人的耐性和毅力,不适合浮躁型的人来做。
CairoPNG(file="E:/bump_bar.png",width=1550,height=1200)
showtext.begin()
vie<-viewport(width=1,height=0.215,x=0.5,y=0.8)
p1;print(p2,vp=vie)
grid.text(label="全球茶叶消费排行榜\n喝茶最多的不是中国人",x=.80,y=.20,gp=gpar(col="black",fontsize=45,fontfamily="myfzhzh",draw=TRUE,just="right"))
grid.text(label="数据来源:Euromonitor、国际茶叶委员会(ITC)",x=.80,y=.13,gp=gpar(col="black",fontsize=20,fontfamily="myfzhzh",draw=TRUE,just="right"))
showtext.end()
dev.off()
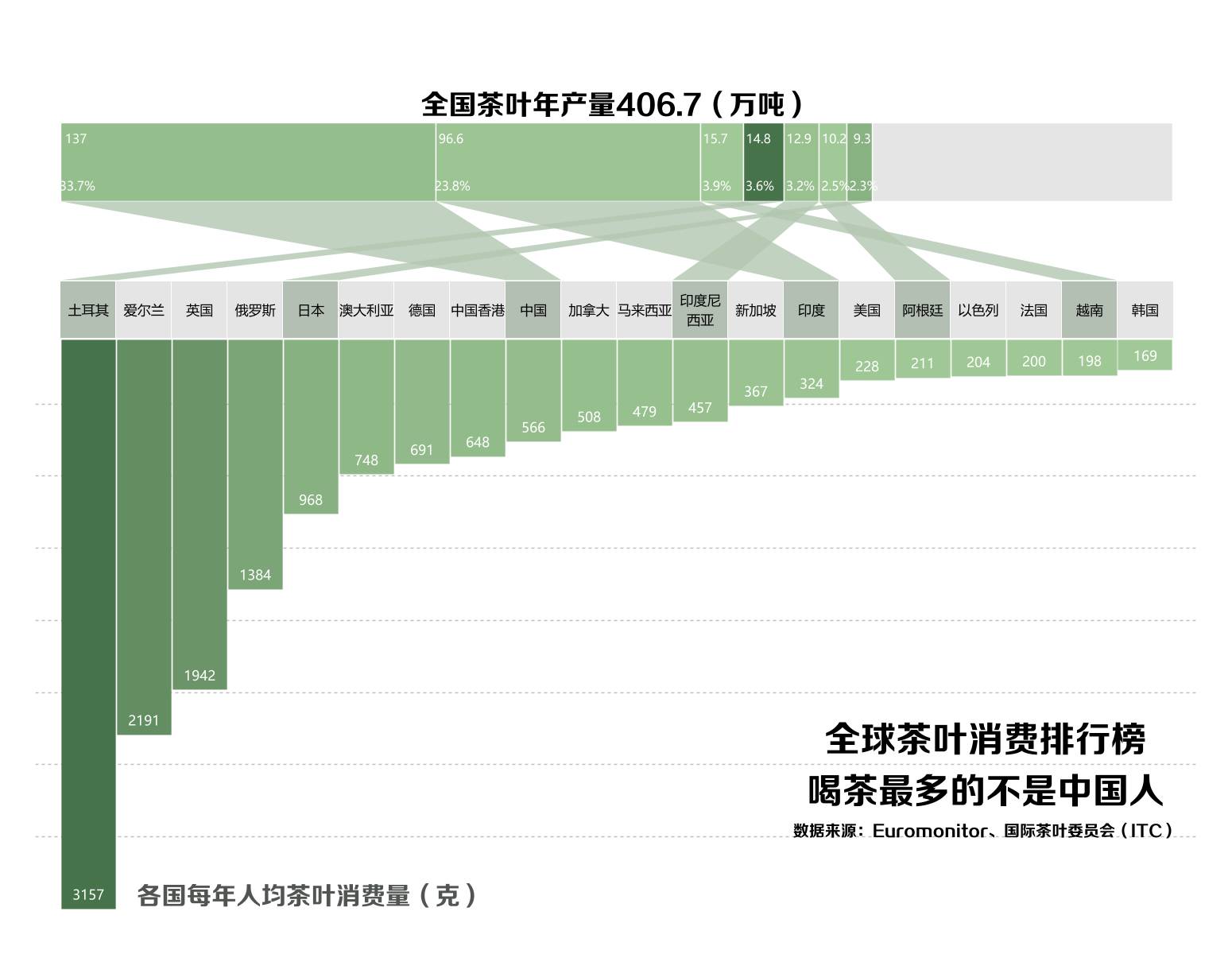
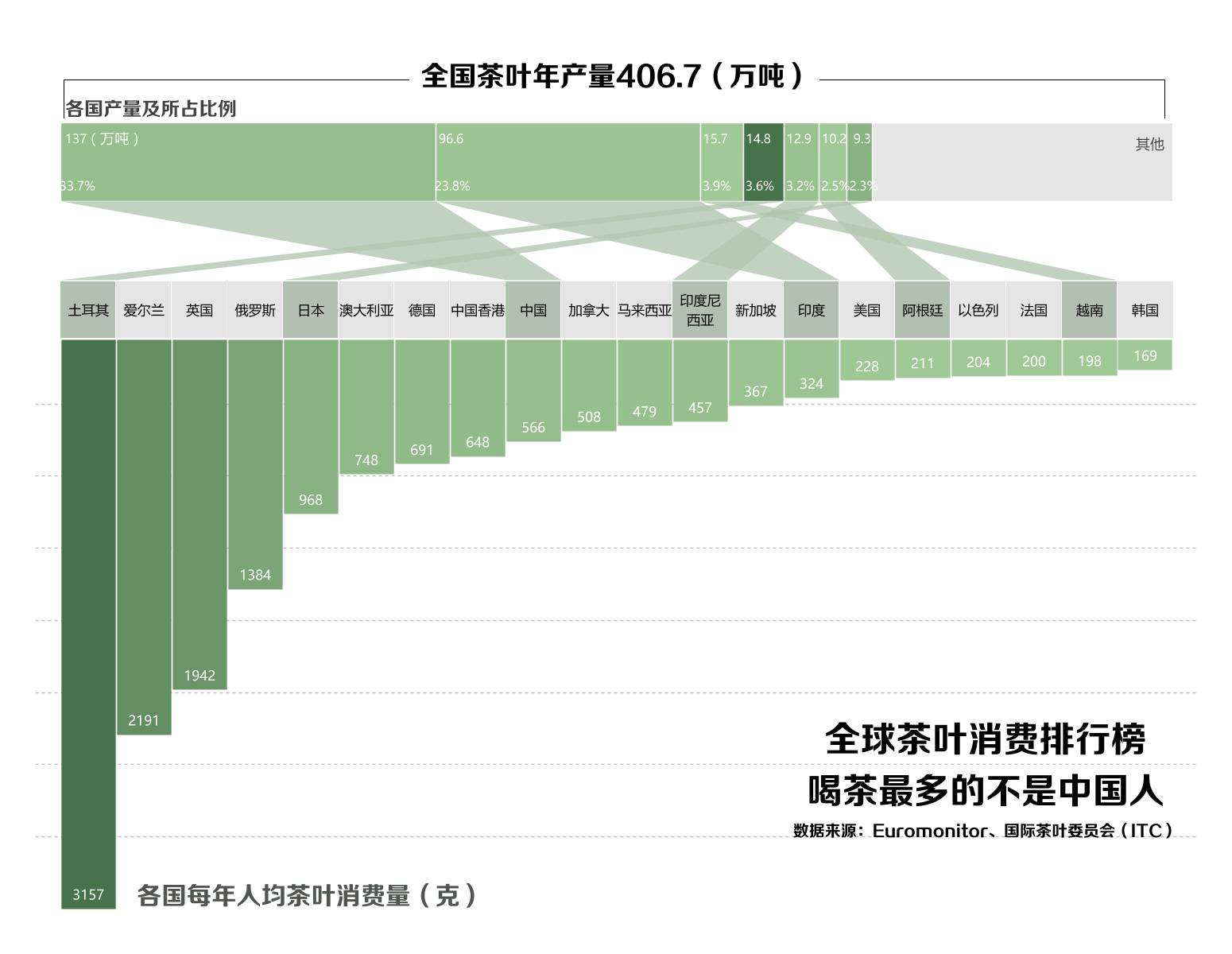
为了与原图对比,我使用PS修饰了一些细节:
读到这里,这篇“R语言数据可视化案例分析”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3335309/blog/4391875



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



