PythonдёӯжҖҺд№Ҳе®һзҺ°ж•°жҚ®еҗҲ并дёҺиҝҪеҠ
жң¬зҜҮж–Үз« дёәеӨ§е®¶еұ•зӨәдәҶPythonдёӯжҖҺд№Ҳе®һзҺ°ж•°жҚ®еҗҲ并дёҺиҝҪеҠ пјҢеҶ…е®№з®ҖжҳҺжүјиҰҒ并且容жҳ“зҗҶи§ЈпјҢз»қеҜ№иғҪдҪҝдҪ зңјеүҚдёҖдә®пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« зҡ„иҜҰз»Ҷд»Ӣз»ҚеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
ж•°жҚ®еҗҲ并пјҲз®ҖеҚ•еҗҲ并пјҢж— йңҖеҢ№й…Қпјү
й’ҲеҜ№з®ҖеҚ•еҗҲ并иҖҢиЁҖпјҢеңЁRиҜӯиЁҖдёӯдё»иҰҒйҖҡиҝҮд»ҘдёӢдёӨдёӘеҮҪж•°жқҘе®һзҺ°пјҡ
cbind()
dplyr::bind_cols()
df1 <- data.frame(A=c('A0', 'A1', 'A2', 'A3'),
B= c('B0', 'B1', 'B2', 'B3'),
C= c('C0', 'C1', 'C2', 'C3'),
D=c('D0', 'D1', 'D2', 'D3')
)
df2 <- data.frame(E=c('A4', 'A5', 'A6', 'A7'),
F= c('B4', 'B5', 'B6', 'B7'),
G=c('C4', 'C5', 'C6', 'C7'),
H= c('D4', 'D5', 'D6', 'D7'))
df3 <-data.frame(I=c('A8', 'A9', 'A10', 'A11'),
J= c('B8', 'B9', 'B10', 'B11'),
K=c('C8', 'C9', 'C10', 'C11'),
L=c('D8', 'D9', 'D10', 'D11')
)
df1;df2;df3
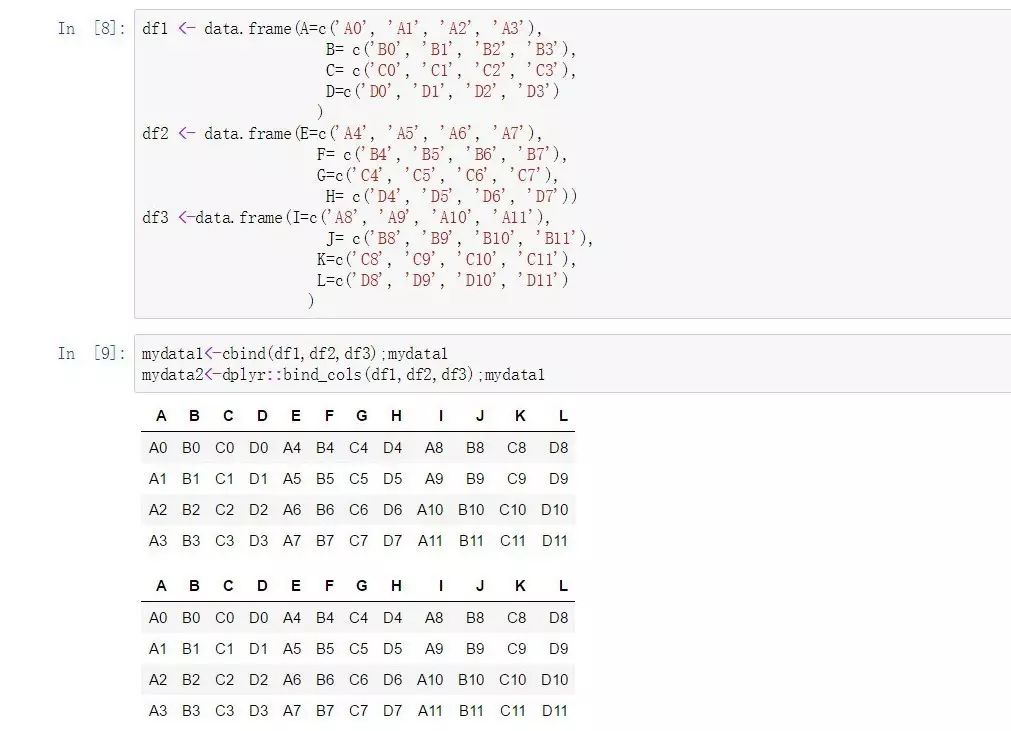
mydata1<-cbind(df1,df2,df3);mydata1
mydata2<-dplyr::bind_cols(df1,df2,df3);mydata1
еңЁPythonдёӯпјҢз®ҖеҚ•зҡ„еҗҲ并еҸҜд»ҘйҖҡиҝҮPandasдёӯзҡ„concatеҮҪж•°жқҘе®һзҺ°зҡ„гҖӮ
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
df2 = pd.DataFrame({'E': ['A4', 'A5', 'A6', 'A7'],
'F': ['B4', 'B5', 'B6', 'B7'],
'G': ['C4', 'C5', 'C6', 'C7'],
'H': ['D4', 'D5', 'D6', 'D7']},
index=[0, 1, 2, 3])
df3 = pd.DataFrame({'I': ['A8', 'A9', 'A10', 'A11'],
'J': ['B8', 'B9', 'B10', 'B11'],
'K': ['C8', 'C9', 'C10', 'C11'],
'L': ['D8', 'D9', 'D10', 'D11']},
index=[0, 1, 2, 3])
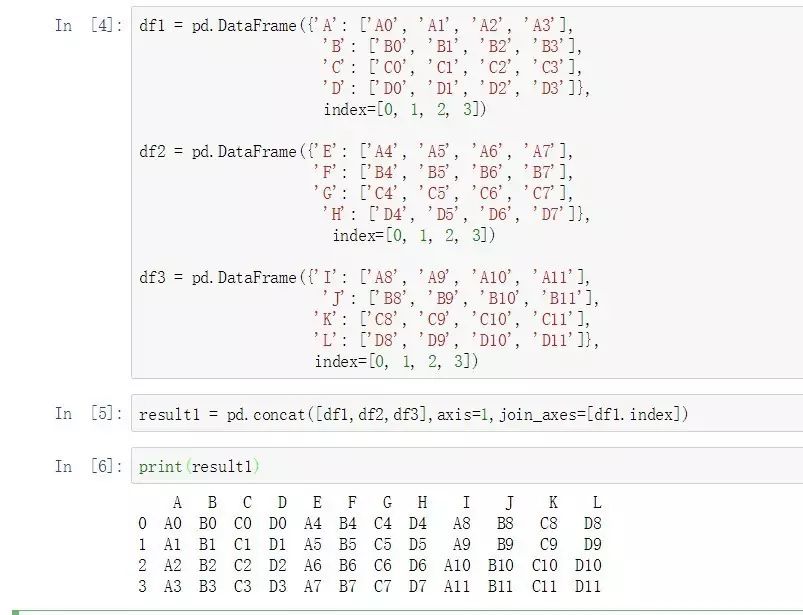
result1 = pd.concat([df1,df2,df3],axis=1,join_axes=[df1.index])
жЁӘеҗ‘еҗҲ并пјҡпјҲйңҖеҢ№й…Қпјү
еңЁRиҜӯиЁҖдёӯпјҢиҝҷз§Қж“ҚдҪңжңүеҫҲеӨҡеҸҜйҖүж–№жЎҲпјҢеҰӮеҹәзЎҖеҮҪж•°mergeгҖҒplyrеҢ…дёӯзҡ„joinеҮҪж•°д»ҘеҸҠdplyrеҢ…дёӯзҡ„left/right/inter/full_joinзӯүеҮҪж•°гҖӮ
иҝҷйҮҢдёәдәҶиҠӮзңҒж—¶й—ҙпјҢеҸӘд»Ӣз»Қ第дёҖз§ҚеҹәзЎҖеҮҪж•°пјҢж¬ІдәҶи§ЈиҜҰжғ…пјҢеҸҜд»ҘжҹҘзңӢиҝҷзҜҮеҺҶеҸІж–Үз« пјҡ
пјҲRиҜӯиЁҖж•°жҚ®еӨ„зҗҶвҖ”вҖ”ж•°жҚ®еҗҲ并дёҺиҝҪеҠ пјү
merge(x, y, #еёҰеҗҲ并зҡ„ж•°жҚ®йӣҶеҗҚз§°пјҲе·ҰеҸійЎәеәҸпјү
by = intersect(names(x), names(y)), #еҗҲ并дҫқжҚ®еӯ—ж®өпјҲеҗҚз§°зӣёеҗҢпјү
by.x = by, #еҗҚз§°дёҚеҗҢж—¶йңҖеҗҢж—¶ж—¶еЈ°жҳҺ
by.y = by, #еҗҚз§°дёҚеҗҢж—¶йңҖеҗҢж—¶ж—¶еЈ°жҳҺ
all = FALSE,#еҗҲ并зұ»еһӢпјҢTRUEдёәе…ЁиҝһжҺҘ пјҲfullпјүпјҢFALSEдёәеҶ…иҝһжҺҘ пјҲinterпјү
all.x = all,#е·ҰиҝһжҺҘ
all.y = all,#еҸіиҝһжҺҘ
)
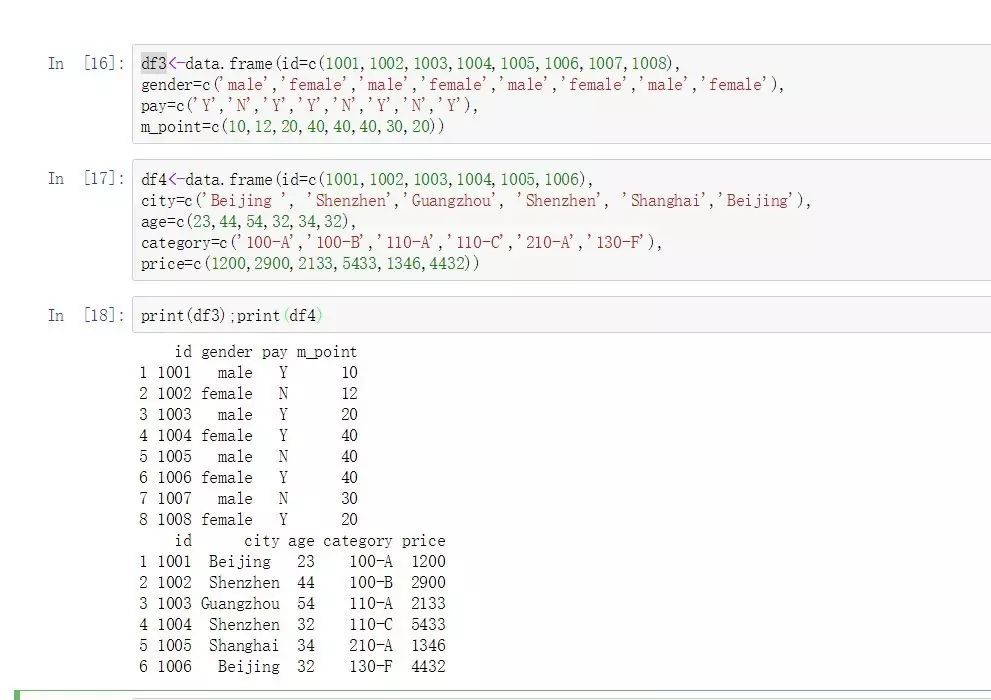
df3<-data.frame(id=c(1001,1002,1003,1004,1005,1006,1007,1008),
gender=c('male','female','male','female','male','female','male','female'),
pay=c('Y','N','Y','Y','N','Y','N','Y'),
m_point=c(10,12,20,40,40,40,30,20))
df4<-data.frame(id=c(1001,1002,1003,1004,1005,1006),
city=c('Beijing ', 'Shenzhen','Guangzhou', 'Shenzhen', 'Shanghai','Beijing'),
age=c(23,44,54,32,34,32),
category=c('100-A','100-B','110-A','110-C','210-A','130-F'),
price=c(1200,2900,2133,5433,1346,4432))
print(df3);print(df4)
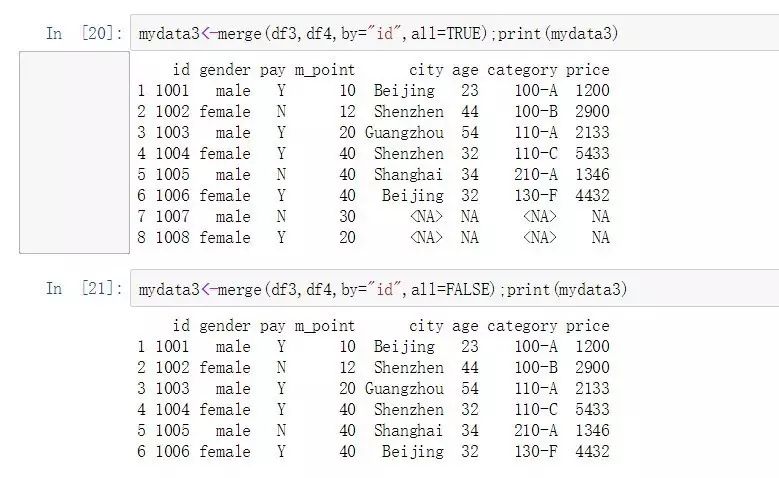
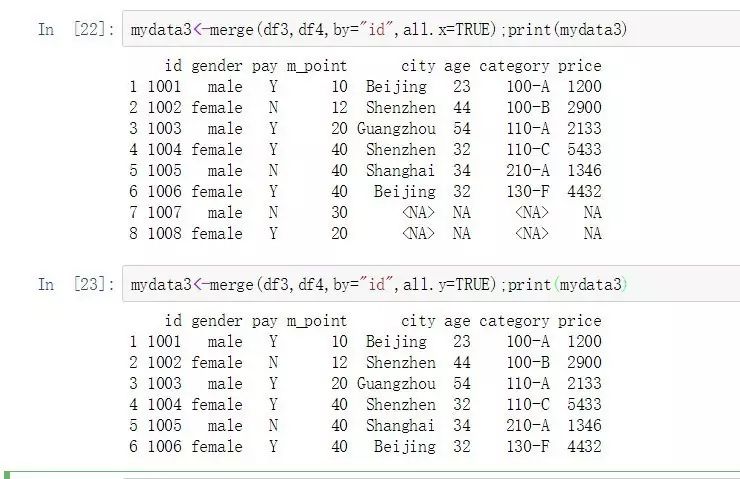
mydata3<-merge(df3,df4,by="id",all=TRUE);print(mydata3)
mydata3<-merge(df3,df4,by="id",all=FALSE);print(mydata3)
mydata3<-merge(df3,df4,by="id",all.x=TRUE);print(mydata3)
mydata3<-merge(df3,df4,by="id",all.y=TRUE);print(mydata3)
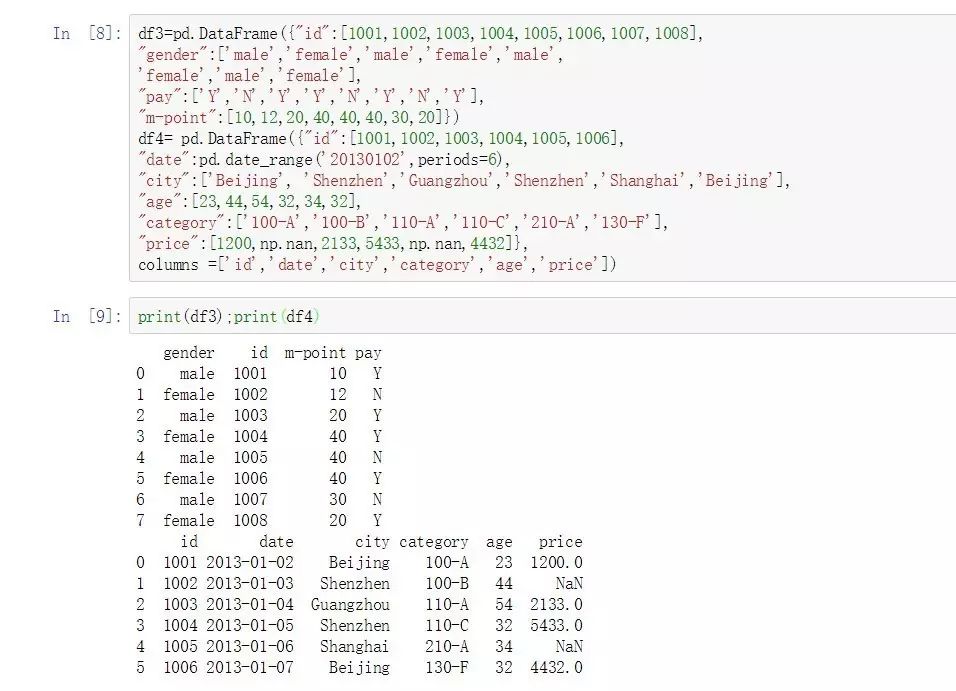
еңЁPythonдёӯпјҢиҝҷдёҖж“ҚдҪңд№ҹеҸҜд»ҘйҖҡиҝҮеҮҪж•°Pandasеә“дёӯзҡ„cancatеҮҪж•°жҲ–иҖ…mergeеҮҪж•°жқҘе®ҢжҲҗгҖӮ
Pandas-merge
df3=pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006,1007,1008],
"gender":['male','female','male','female','male',
'female','male','female'],
"pay":['Y','N','Y','Y','N','Y','N','Y'],
"m-point":[10,12,20,40,40,40,30,20]})
df4= pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006],
"date":pd.date_range('20130102',periods=6),
"city":['Beijing', 'Shenzhen','Guangzhou','Shenzhen','Shanghai','Beijing'],
"age":[23,44,54,32,34,32],
"category":['100-A','100-B','110-A','110-C','210-A','130-F'],
"price":[1200,np.nan,2133,5433,np.nan,4432]},
columns =['id','date','city','category','age','price'])
print(df3);print(df4)
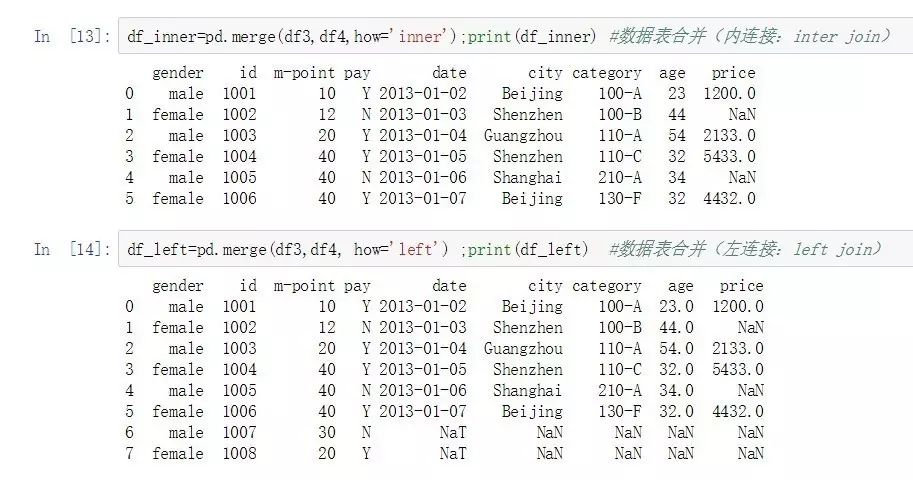
df_inner=pd.merge(df3,df4,how='inner');print(df_inner) #ж•°жҚ®иЎЁеҗҲ并пјҲеҶ…иҝһжҺҘпјҡinter joinпјү
df_left=pd.merge(df3,df4, how='left') ;print(df_left) #ж•°жҚ®иЎЁеҗҲ并пјҲе·ҰиҝһжҺҘпјҡleft joinпјү
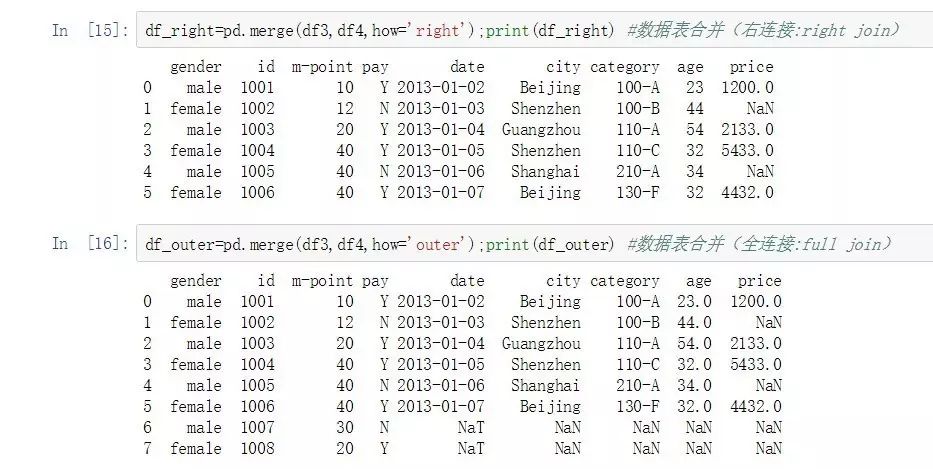
df_right=pd.merge(df3,df4,how='right');print(df_right) #ж•°жҚ®иЎЁеҗҲ并пјҲеҸіиҝһжҺҘ:right joinпјү
df_outer=pd.merge(df3,df4,how='outer');print(df_outer) #ж•°жҚ®иЎЁеҗҲ并пјҲе…ЁиҝһжҺҘ:full joinпјү
ж•°жҚ®иҝҪеҠ пјҡ
ж•°жҚ®иҝҪеҠ йҖҡеёёеҸӘйңҖдҝқиҜҒж•°жҚ®еҸҠзҡ„е®ҪеәҰдёҖиҮҙдё”еҲ—еӯ—ж®өеҗҚз§°дёҖиҮҙпјҢзӣёеҜ№жқҘиҜҙжҜ”иҫғз®ҖеҚ•гҖӮеңЁRиҜӯиЁҖе’ҢPythonдёӯпјҢд№ҹеҫҲеҘҪе®һзҺ°гҖӮ
еңЁRиҜӯиЁҖдёӯпјҢеҸҜи§ҶеҢ–жңұж•°жҚ®иҝҪеҠ зҡ„еҮҪж•°жңүпјҡ
rbind()
dplyr::bind_rows()
mydata3<-rbind(df1,df2,df3);mydata3
mydata4<-dplyr::bind_rows(df1,df2,df3);mydata4
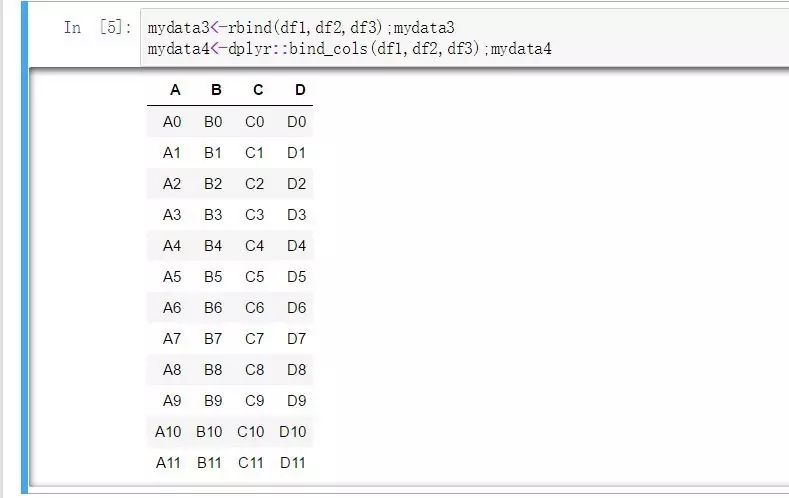
pythonдёӯеҲҷеҸҜд»ҘеҫҲе®№жҳ“зҡ„йҖҡиҝҮж•°жҚ®жЎҶжң¬иә«зҡ„appendеҮҪж•°жқҘе®һзҺ°з®ҖеҚ•зҡ„ж•°жҚ®иҝҪеҠ пјҡ
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']},
index=[4,5,6,7])
df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']},
index=[8, 9,10,11])
result = df1.append(df2);print(result)
result = result.append(df3);print(result)
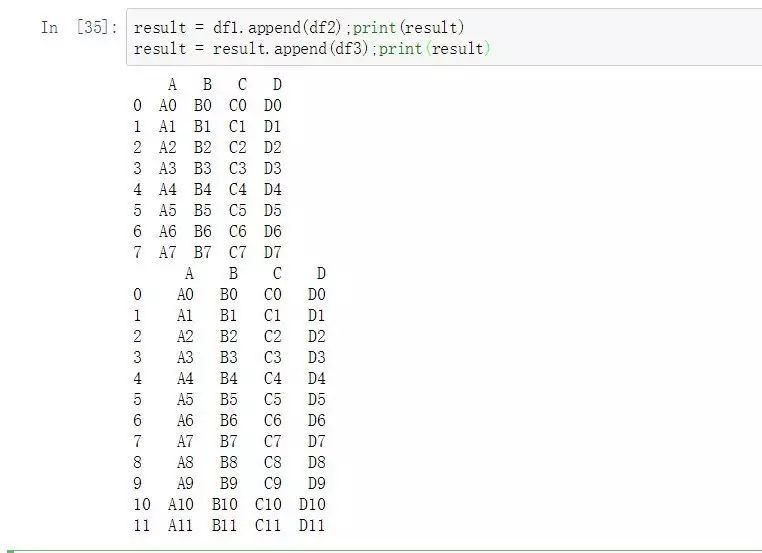
еҰӮжһңжҳҜдҪҝз”ЁcanatеҮҪж•°д№ҹеҸҜд»ҘйқһеёёиҪ»жқҫзҡ„е®ҢжҲҗж•°жҚ®иҝҪеҠ пјҡ
result = pd.concat([df1, df2, df3]);print(result)
жң¬ж–ҮжұҮжҖ»пјҡ
ж•°жҚ®еҗҲ并пјҲз®ҖеҚ•еҗҲ并пјү
Rпјҡ
cbind()
dplyr::bind_cols()
Python:
Pandas-cancat()
ж•°жҚ®еҗҲ并пјҲеҢ№й…Қе’Ң并пјү
R:
merge
plyr::join()
dplyr::left/right/inter/full_join()
Python:
Pandas-merge
ж•°жҚ®иҝҪеҠ пјҡ
Rпјҡ
rbind()
dplyr::bind_rows()
Python:
Pandas-append()
Pandas-cancat()
дёҠиҝ°еҶ…е®№е°ұжҳҜPythonдёӯжҖҺд№Ҳе®һзҺ°ж•°жҚ®еҗҲ并дёҺиҝҪеҠ пјҢдҪ 们еӯҰеҲ°зҹҘиҜҶжҲ–жҠҖиғҪдәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–иҖ…дё°еҜҢиҮӘе·ұзҡ„зҹҘиҜҶеӮЁеӨҮпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





