本篇文章给大家分享的是有关如何用R语言和Python进行相关性分析,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
由于最近毕业论文缠身,一直都没有太多时间和精力撰写长篇的干货,但是呢学习的的脚步不能停止,今天跟大家盘点一下R语言与Python中到的相关性分析部分的常用函数。
常用的衡量随机变量相关性的方法主要有三种:
pearson相关系数;即皮尔逊相关系数,用于横向两个连续性随机变量间的相关系数。
spearman相关系数;即斯皮尔曼相关系数,用于衡量分类定序变量间的相关程度。
kendall相关系数;即肯德尔相关系数,也是一种秩相关系数,不过它所计算的对象是分类变量。
R语言:
cor
cor.test
corrplot
cor(x,y=NULL,use="everything",method= c("pearson","kendall","spearman"))
在R语言中,通常使用cor函数进行相关系数分析,可以分别指定向量,也可以指定给cor函数一个数据框。
use函数指定处理缺失值的方式
method是可选的三种相关系数计算方法。
这里以diamonds数据集为例:
library("ggplot2")
str(diamonds)
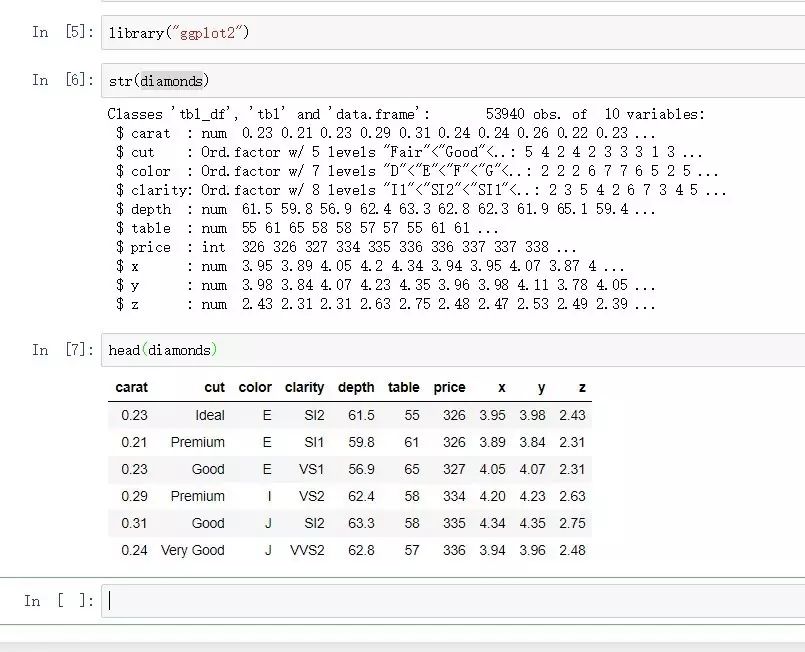
cor(diamonds[,c("carat","depth","price")])
cor(diamonds[,c("carat","depth","price")],method= "pearson")
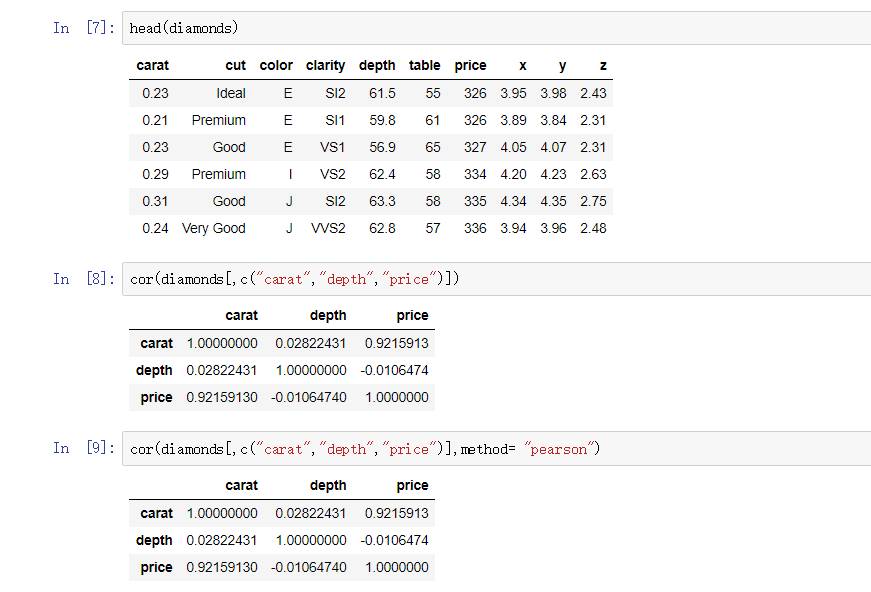
默认情况下使用的是pearson相关系数。
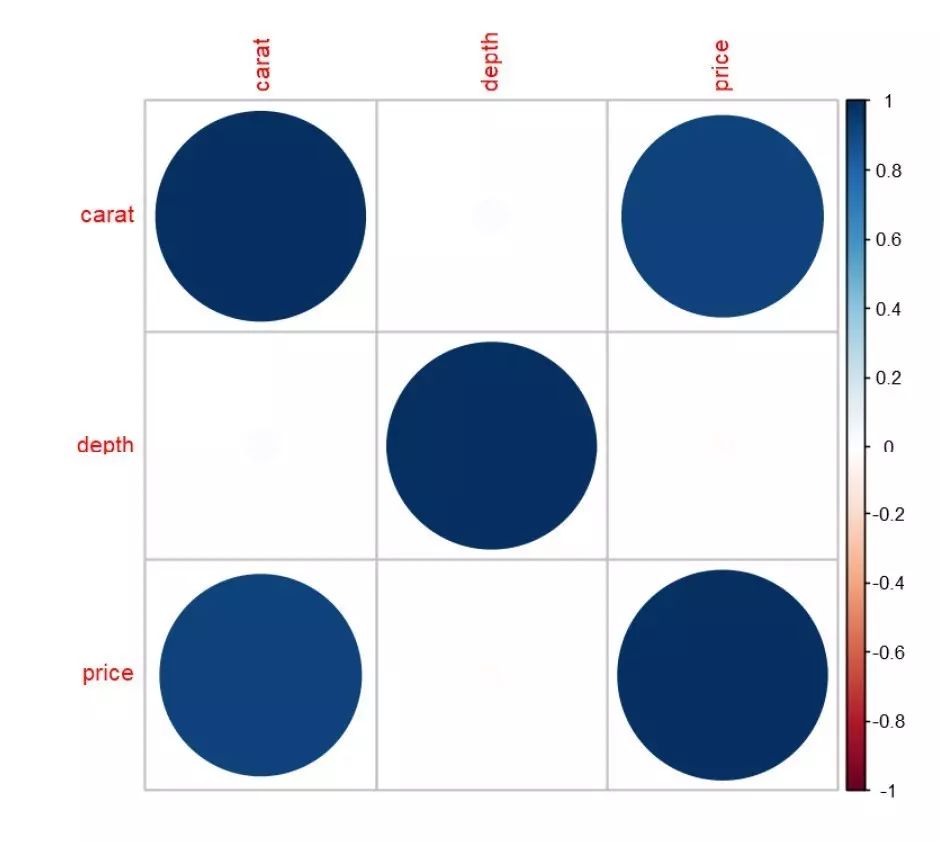
corrplot函数可以针对相关系数输出的结果进行可视化:
library("corrplot")
library("dplyr")
cor(diamonds[,c("carat","depth","price")])%>%corrplot()
使用cor.test函数进行相关性的检验:
cor.test(x, y, #指定带分析变量
alternative = c("two.sided", "less", "greater"),
#双侧检验,单侧检验(默认双侧)
method = c("pearson", "kendall", "spearman"),
#相关性算法(默认pearson法)
exact = NULL, conf.level = 0.95, continuity = FALSE, ...)
cor.test(diamonds$carat,diamonds$depth)
cor.test(~carat+depth,diamonds)
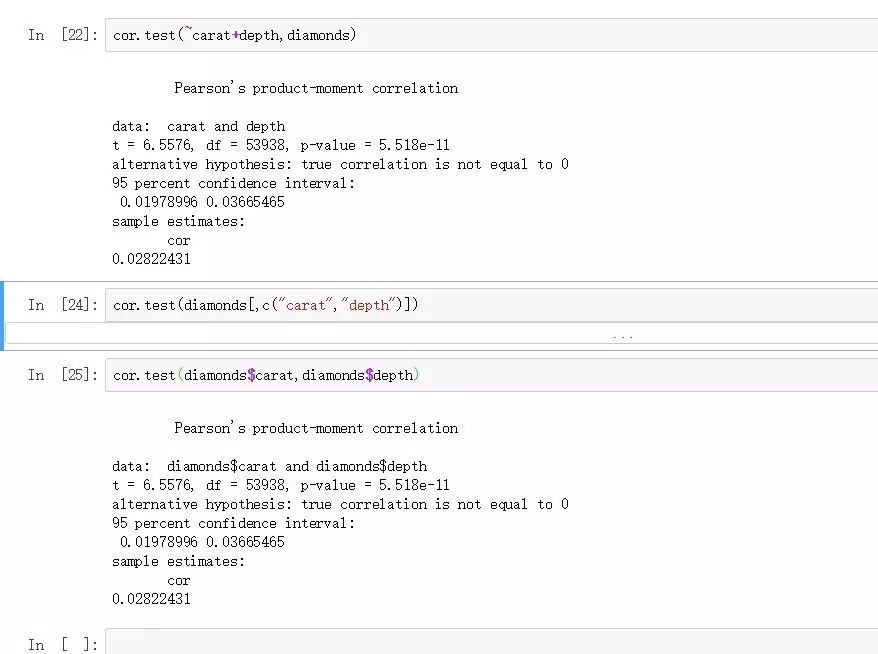
以上两种写法都是支持的。
从结果可以看到,两者几乎不相关,pearson相关系数仅有0.02左右。
Pyhton:
import pandas as pd
import numpy as np
diamonds=pd.read_csv('D:/R/File/diamonds.csv',sep = ',',encoding = 'utf-8')
diamonds.info()
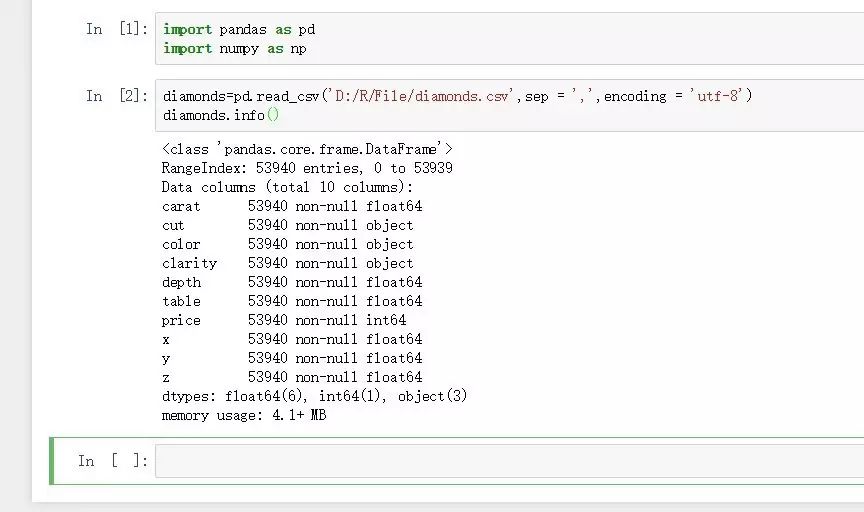
pandas中带有相关系数函数pandas.corr

mydata=diamonds[["carat","depth","table","price"]]
mydata.info()
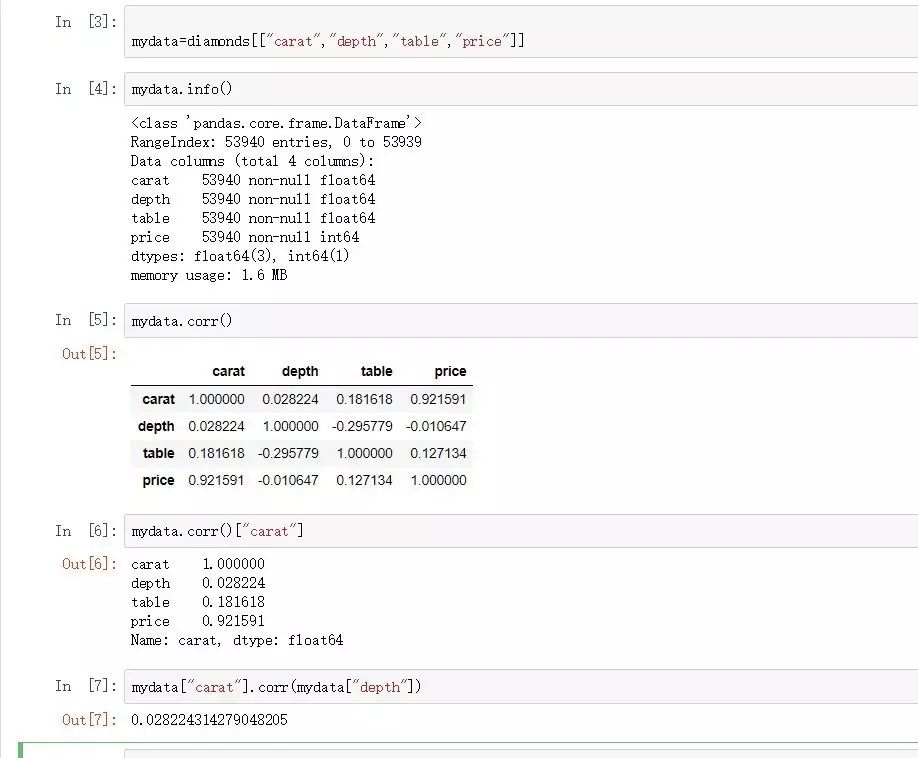
mydata.corr()
#可以直接给出数据框的相关系数矩阵
mydata.corr()["carat"]
#给出caret变量与其他变量之间的相关系数
mydata["carat"].corr(mydata["depth"])
#计算"carat"与"depth"之间的相关系数
与R语言中一样,pandas中内置的相关系数算法也是针对针对数值型变量的pearson法。
mydata.corr(method='pearson')
mydata.corr(method='pearson')["carat"]
mydata["carat"].corr(method='pearson',mydata["depth"])
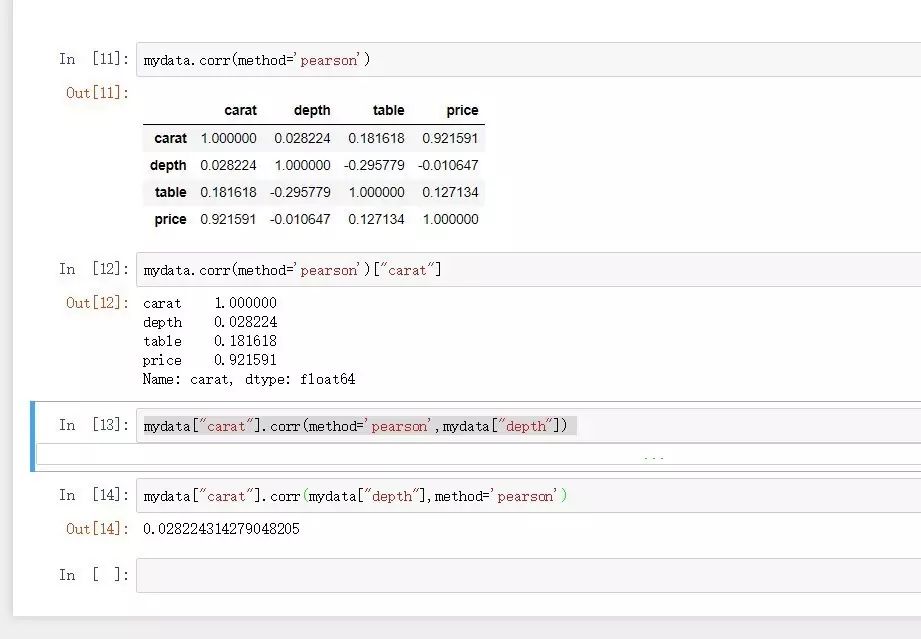
method也可以指定spearman法和kendall法计算相关系数。
本文小结:
R语言:
cor
cor.test
corplot
Python:
pandas.corr
以上就是如何用R语言和Python进行相关性分析,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





