TensorFlow如何实现线性支持向量机SVM,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
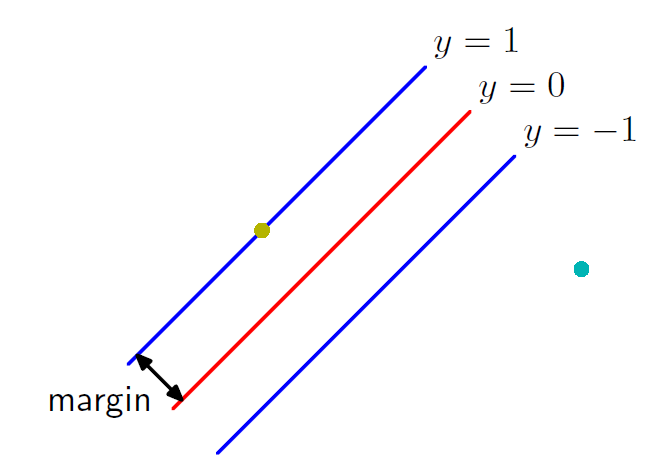
今天要说的是线性可分情况下的支持向量机的实现,如果对于平面内的点,支持向量机的目的是找到一条直线,把训练样本分开,使得直线到两个样本的距离相等,如果是高维空间,就是一个超平面。
然后我们简单看下对于线性可分的svm原理是啥,对于线性模型:
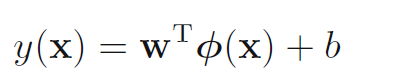
训练样本为

标签为:
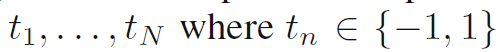
如果
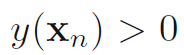
那么样本就归为正类, 否则归为负类。
这样svm的目标是找到W(向量)和b,然后假设我们找到了这样的一条直线,可以把数据分开,那么这些数据到这条直线的距离为:
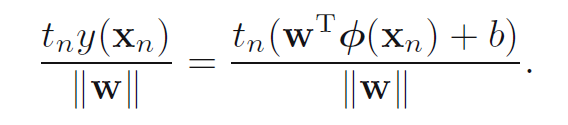
然后我们把超平面两边到超平面的距离叫做间隔(margin),优化目标是使得这个margin最大,使得这样得到的超平面具有良好的泛化能力(用别的数据也能正确分类),
SVM的优化目标是:
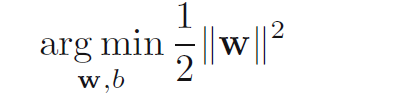
条件是:
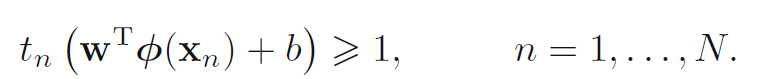
注意这里,因为tn可以取+1和-1,当取-1的时候,不等式两边都会乘以-1,所以不等号的方向会变。求解这个优化问题(二次规划),可以用拉格朗日乘子法,其中alpha是拉格朗日乘子。
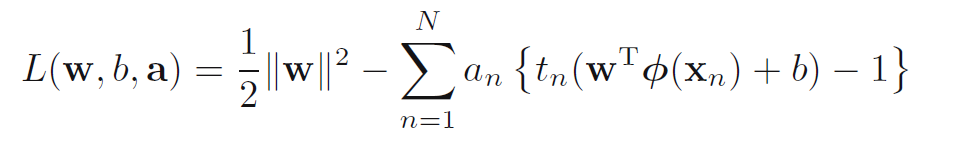
对w和b求导,可以得到:
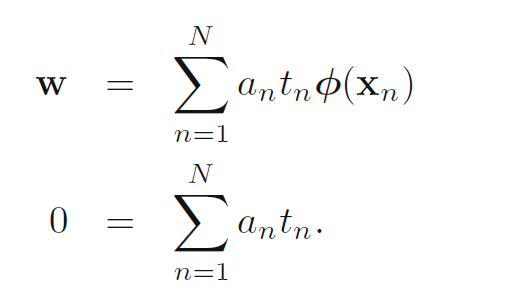
然后把这个求解的结果代到上面的L里面,可以得到L的对偶形式,得L~:
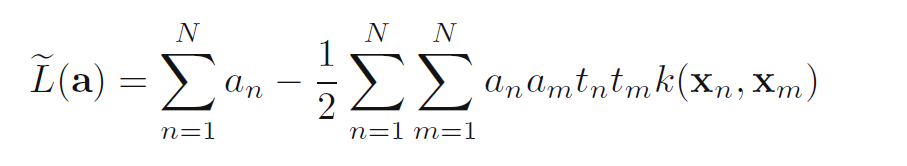
对偶形式的条件是:
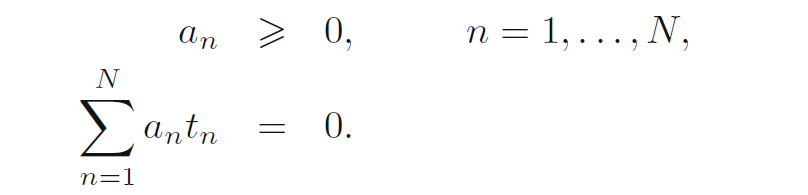
然后将开始的那个线性模型中的参数W用核函数代替得到:
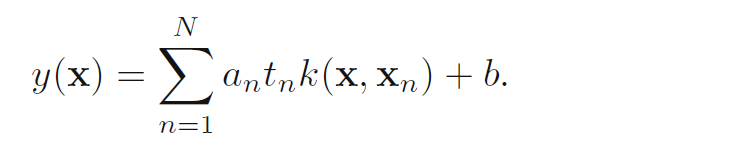
上面L的对偶形式,就是一个简单的二次规划问题,可以利用KKT条件求解:
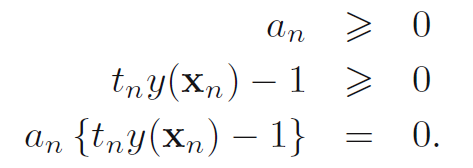
然后把上面的y(xn)带入到这个等式里面,就得到下面这个式子:
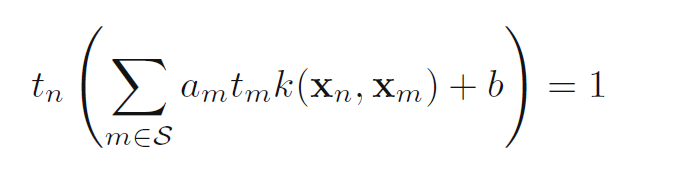
求解上式,得b为:
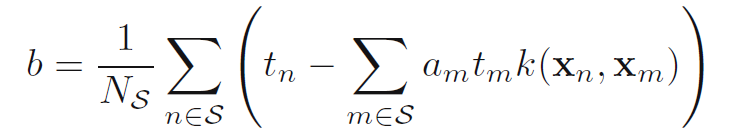
其中Ns表示的就是支持向量,K(Xn,Xm)表示核函数。
下面举个核函数的栗子,对于二维平面内的点,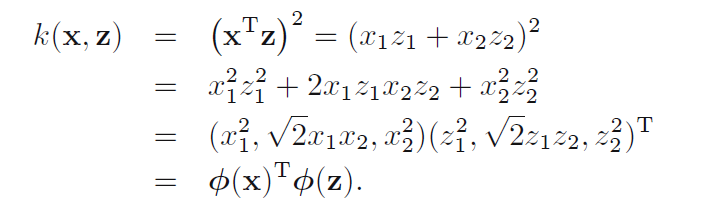
花了两个多小时,终于算是把代码调通了,虽然不难,但是还是觉得自己水平有限,实现起来还是会有很多问题
import numpy as np
import tensorflow as tf
from sklearn import datasets
x_data = tf.placeholder(shape=[None, 2], dtype=tf.float32)
y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32)
# 获得batch大小的数据
def gen_data(batch_size):
iris = datasets.load_iris()
iris_X = np.array([[x[0], x[3]] for x in iris.data])
iris_y = np.array([1 if y == 0 else -1 for y in iris.target])
train_indices = np.random.choice(len(iris_X),
int(round(len(iris_X) * 0.8)), replace=False)
train_x = iris_X[train_indices]
train_y = iris_y[train_indices]
rand_index = np.random.choice(len(train_x), size=batch_size)
batch_train_x = train_x[rand_index]
batch_train_y = np.transpose([train_y[rand_index]])
test_indices = np.array(
list(set(range(len(iris_X))) - set(train_indices)))
test_x = iris_X[test_indices]
test_y = iris_y[test_indices]
return batch_train_x, batch_train_y, test_x, test_y
# 定义模型
def svm():
A = tf.Variable(tf.random_normal(shape=[2, 1]))
b = tf.Variable(tf.random_normal(shape=[1, 1]))
model_output = tf.subtract(tf.matmul(x_data, A), b)
l2_norm = tf.reduce_sum(tf.square(A))
alpha = tf.constant([0.01])
classification_term = tf.reduce_mean(tf.maximum(0.,
tf.subtract(1., tf.multiply(model_output, y_target))))
loss = tf.add(classification_term, tf.multiply(alpha, l2_norm))
my_opt = tf.train.GradientDescentOptimizer(0.01)
train_step = my_opt.minimize(loss)
return model_output, loss, train_step
def train(sess, batch_size):
print("# Training loop")
for i in range(100):
x_vals_train, y_vals_train,\
x_vals_test, y_vals_test = gen_data(batch_size)
model_output, loss, train_step = svm()
init = tf.global_variables_initializer()
sess.run(init)
prediction = tf.sign(model_output)
accuracy = tf.reduce_mean(tf.cast(
tf.equal(prediction, y_target), tf.float32))
sess.run(train_step, feed_dict=
{
x_data: x_vals_train,
y_target: y_vals_train
})
train_loss = sess.run(loss, feed_dict=
{
x_data: x_vals_train,
y_target: y_vals_train
})
train_acc = sess.run(accuracy, feed_dict=
{
x_data: x_vals_train,
y_target: y_vals_train
})
test_acc = sess.run(accuracy, feed_dict=
{
x_data: x_vals_test,
y_target: np.transpose([y_vals_test])
})
if i % 10 == 1:
print("train loss: {:.6f}, train accuracy : {:.6f}".
format(train_loss[0], train_acc))
print
print("test accuracy : {:.6f}".format(test_acc))
print("- * - "*15)
def main(_):
with tf.Session() as sess:
train(sess, batch_size=16)
if __name__ == "__main__":
tf.app.run()
总结一下,SVM里面的坑,首先要知道SVM的目的找到一条线或者超平面,然后会计算点到超平面的距离,然后把这个距离转化为一个二次规划问题,然后就是使用拉格朗日方法求解这个优化问题,最后会涉及核函数方法。
看完上述内容,你们掌握TensorFlow如何实现线性支持向量机SVM的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





