本篇文章为大家展示了Python爬虫的起点是什么,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
好好的讲爬虫和HTTP有什么关系?其实我们常说的爬虫(也叫网络爬虫)就是使用一些网络协议发起的网络请求,而目前使用最多的网络协议便是HTTP/S网络协议簇。
在真实浏览网页我们是通过鼠标点击网页然后由浏览器帮我们发起网络请求,那在Python中我们又如何发起网络请求的呢?答案当然是库,具体哪些库?猪哥给大家列一下:
Python2: httplib、httplib2、urllib、urllib2、urllib3、requests
Python3: httplib2、urllib、urllib3、requests
Python网络请求库有点多,而且还看见网上还都有用过的,那他们之间有何关系?又该如何选择?
httplib/2:
这是一个Python内置http库,但是它是偏于底层的库,一般不直接用。
而httplib2是一个基于httplib的第三方库,比httplib实现更完整,支持缓存、压缩等功能。
一般这两个库都用不到,如果需要自己 封装网络请求可能会需要用到。
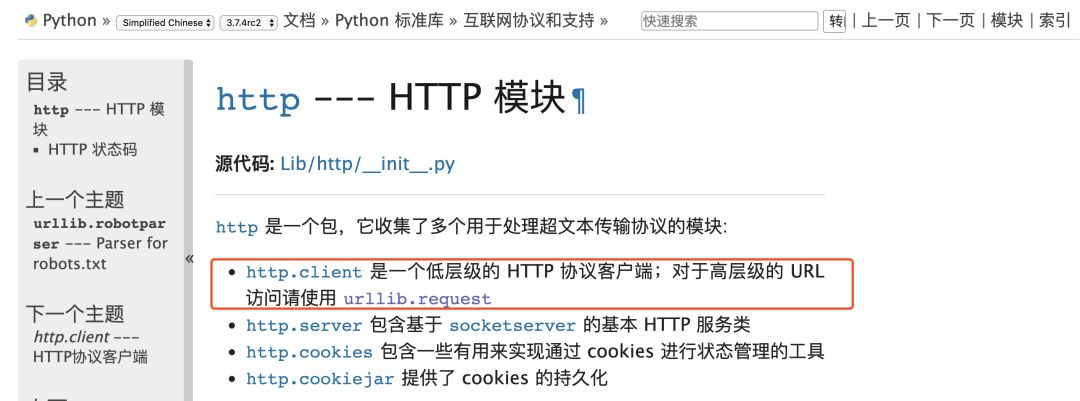
urllib/urllib2/urllib3:
urlliib是一个基于httplib的上层库,而urllib2和urllib3都是第三方库,urllib2相对于urllib增加一些高级功能,如:
HTTP身份验证或Cookie等,在Python3中将urllib2合并到了urllib中。
urllib3提供线程安全连接池和文件post等支持,与urllib及urllib2的关系不大。
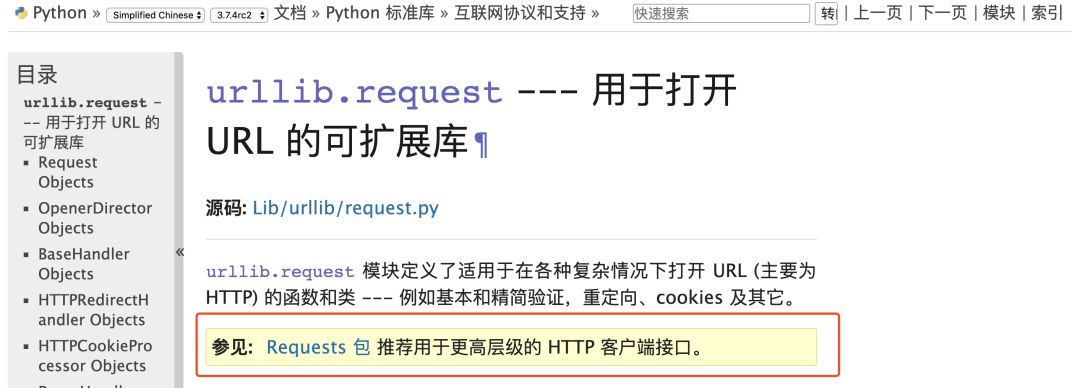
requests:
requests库是一个基于urllib/3的第三方网络库,它的特点是功能强大,API优雅。
由上图我们可以看到,对于http客户端python官方文档也推荐我们使用requests库,实际工作中requests库也是使用的比较多的库。
综上所述,我们选择选择requests库作为我们爬虫入门的起点。另外以上的这些库都是同步网络库,如果需要高并发请求的话可以使用异步网络库:aiohttp,这个后面猪哥也会为大家讲解。
希望大家永远记住:学任何一门语言,都不要忘记去看看官方文档。也许官方文档不是最好的入门教程,但绝对是最新、最全的教学文档!
requests的官方文档(目前已支持中文)链接:http://cn.python-requests.org
源代码地址:https://github.com/kennethreitz/requests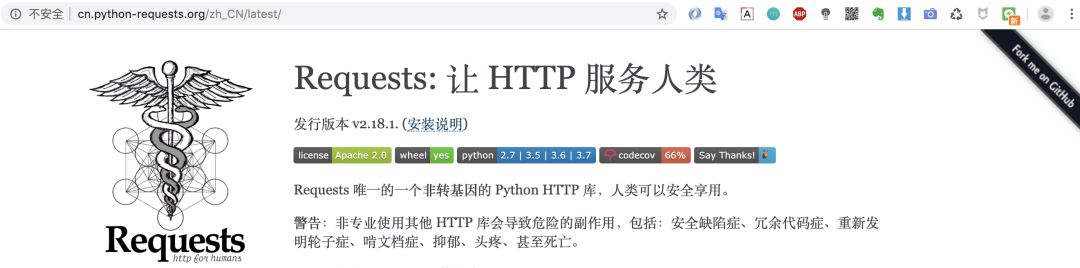
从首页中让HTTP服务人类这几个字中我们便能看出,requests核心宗旨便是让用户使用方便,间接表达了他们设计优雅的理念。
注:PEP 20便是鼎鼎大名的Python之禅。
警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症、冗余代码症、重新发明轮子症、啃文档症、抑郁、头疼、甚至死亡。
都说requests功能强大,那我们来看看requests到底有哪些功能特性吧:
Keep-Alive & 连接池
国际化域名和 URL
带持久 Cookie 的会话
浏览器式的 SSL 认证
自动内容解码
基本/摘要式的身份认证
优雅的 key/value Cookie
自动解压
Unicode 响应体
HTTP(S) 代理支持
文件分块上传
流下载
连接超时
分块请求
支持 .netrc
requests 完全满足今日 web 的需求。Requests 支持 Python 2.6—2.7以及3.3—3.7,而且能在 PyPy 下完美运行
pip install requests
如果是pip3则使用
pip3 install requests
如果你使用anaconda则可以
conda install requests
如果你不想用命令行,可在pycharm中这样下载库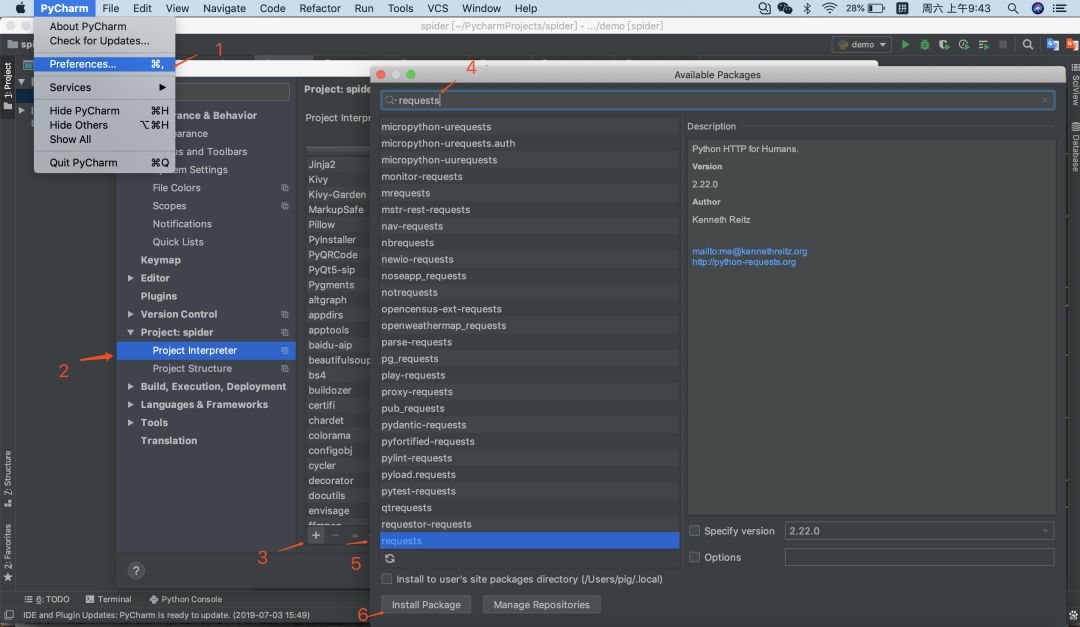
下图是猪哥之前工作总结的一个项目开发流程,算是比较详细,在开发一个大型的项目真的需要这么详细,不然项目上线出故障或者修改需求都无法做项目复盘,到时候程序员就有可能背锅祭天。。。
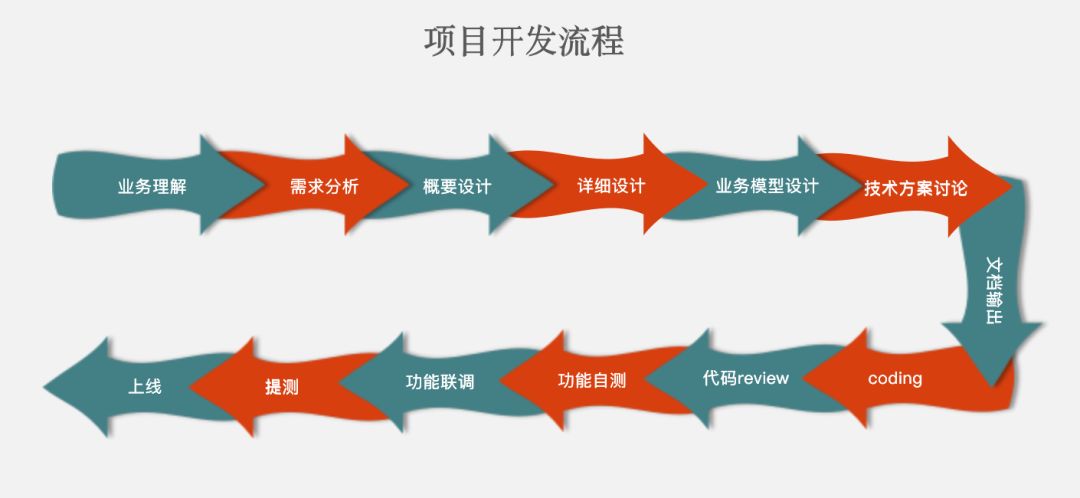
言归正传,给大家看项目的开发流程是想引出爬虫爬取数据的流程:
确定需要爬取的网页
浏览器检查数据来源(静态网页or动态加载)
寻找加载数据url的参数规律(如分页)
代码模拟请求爬取数据
猪哥就以某东商品页为例子带大家学习爬虫的简单流程,为什么以某东下手而不是某宝?因为某东浏览商品页不需要登录,简单便于大家快速入门!
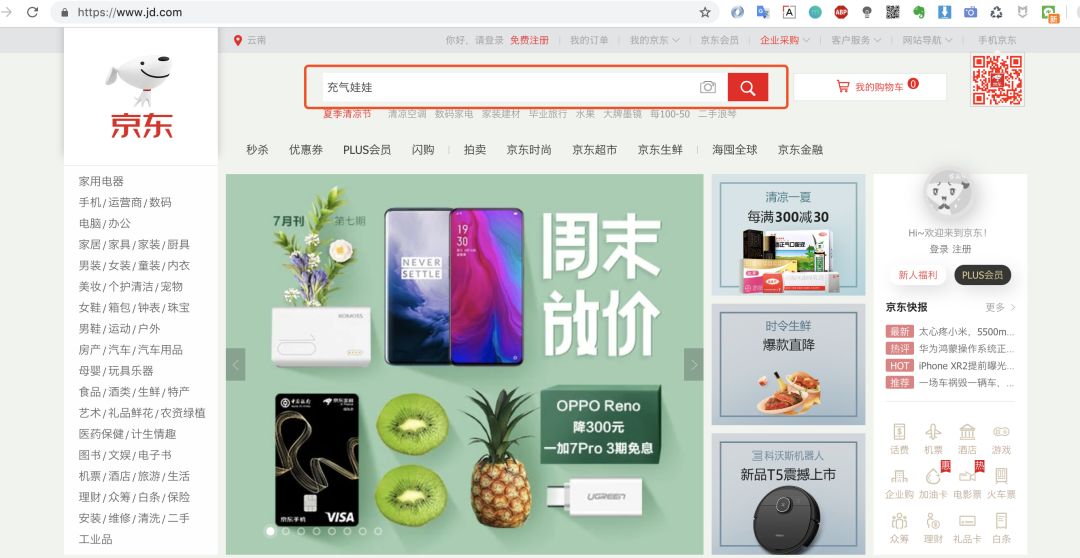
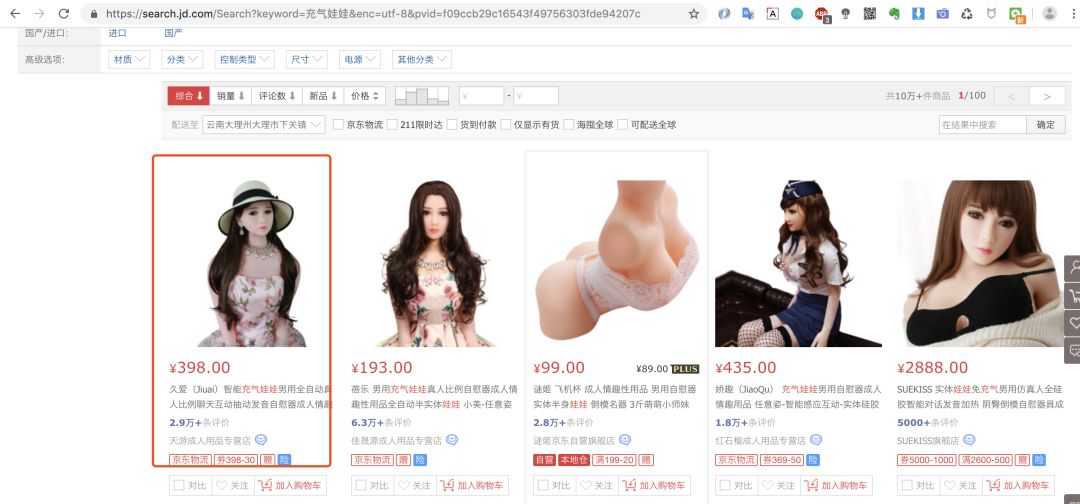
ps:猪哥并不是在开车哦,为什么选这款商品?因为后面会爬取这款商品的评价做数据分析,是不是很刺激!
打开浏览器调试窗口是为了查看网络请求,看看数据是怎么加载的?是直接返回静态页面呢,还是js动态加载呢?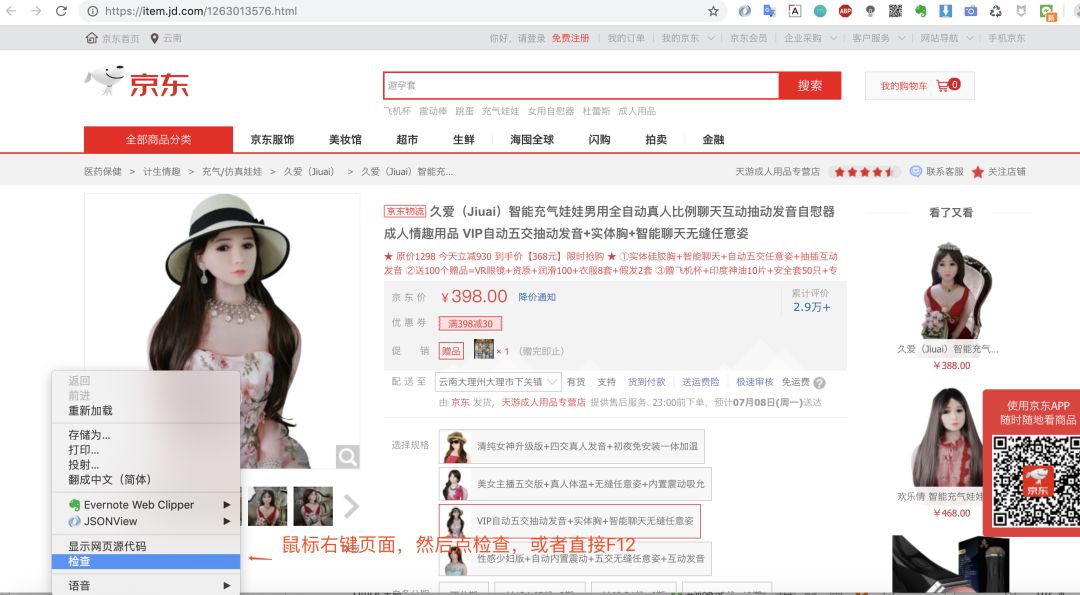
鼠标右键然后点检查或者直接F12即可打开调试窗口,这里猪哥推荐大家使用Chrome浏览器,为什么?因为好用,程序员都在用!具体的Chrome如何调试,大家自行网上看教程!
打开调试窗口之后,我们就可以重新请求数据,然后查看返回的数据,确定数据来源。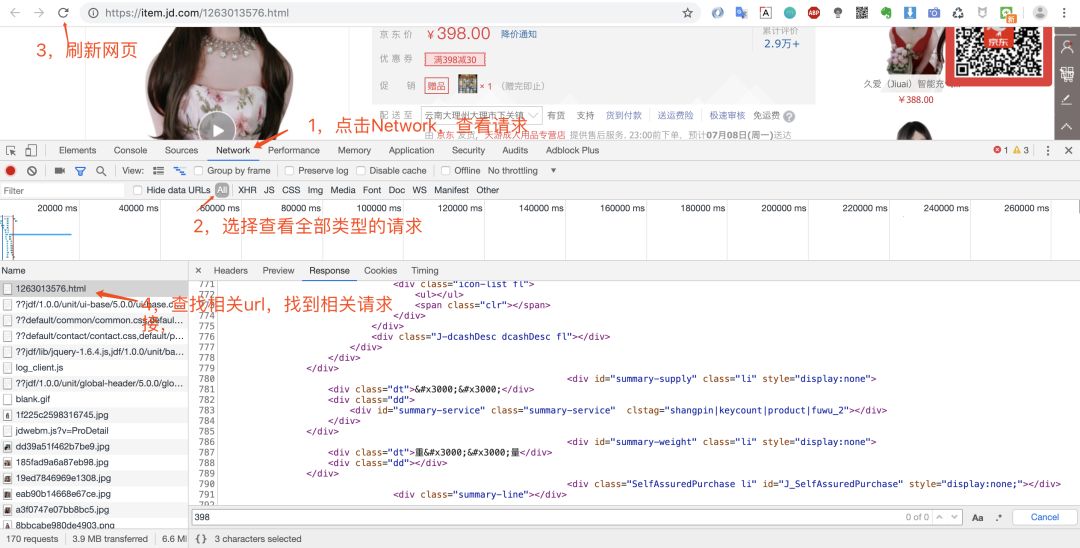
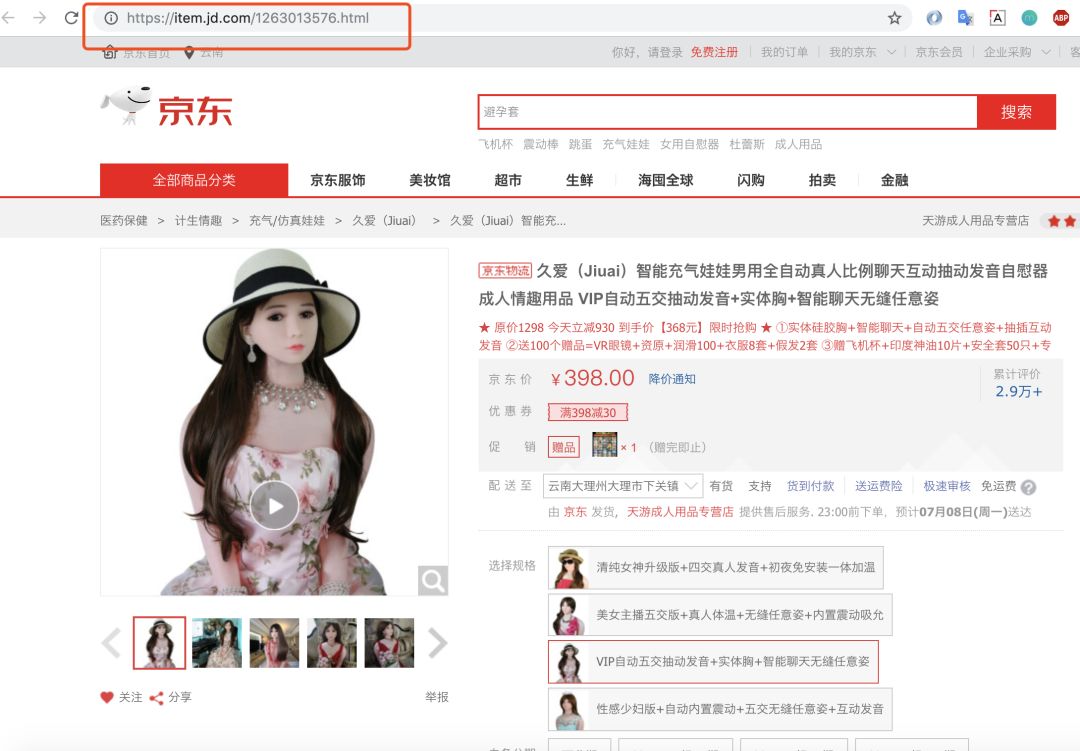
我们可以看到第一个请求链接:https://item.jd.com/1263013576.html 返回的数据便是我们要的网页数据。因为我们是爬取商品页,所以不存在分页之说。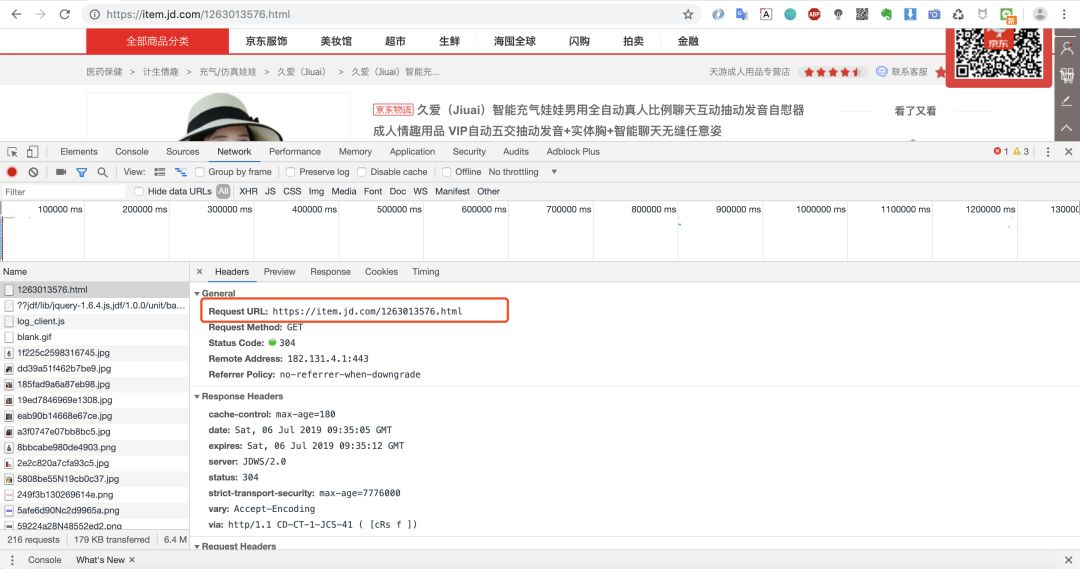
当然价格和一些优惠券等核心信息是通过另外的请求加载,这里我们暂时不讨论,先完成我们的第一个小例子!
获取url链接之后我们来开始写代码吧
import requestsdef spider_jd(): """爬取京东商品页""" url = 'https://item.jd.com/1263013576.html' try: r = requests.get(url) # 有时候请求错误也会有返回数据 # raise_for_status会判断返回状态码,如果4XX或5XX则会抛出异常 r.raise_for_status() print(r.text[:500]) except: print('爬取失败')if __name__ == '__main__': spider_jd()检查返回结果
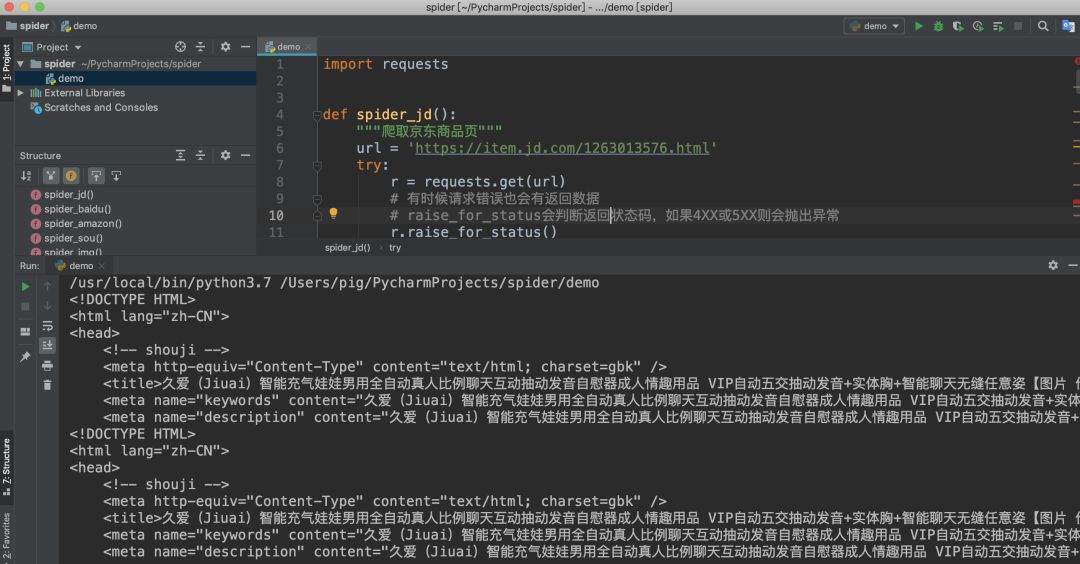
至此我们就完成了某东商品页的爬取,虽然案例简单,代码很少,但是爬虫的流程基本差不多,希望想学爬虫的同学自己动动手实践一把,选择自己喜欢的商品抓取一下,只有自己动手才能真的学到知识!
上面我们使用了requests的get方法,我们可以查看源码发现还有其他几个方法:post、put、patch、delete、options、head,他们就是对应HTTP的请求方法。
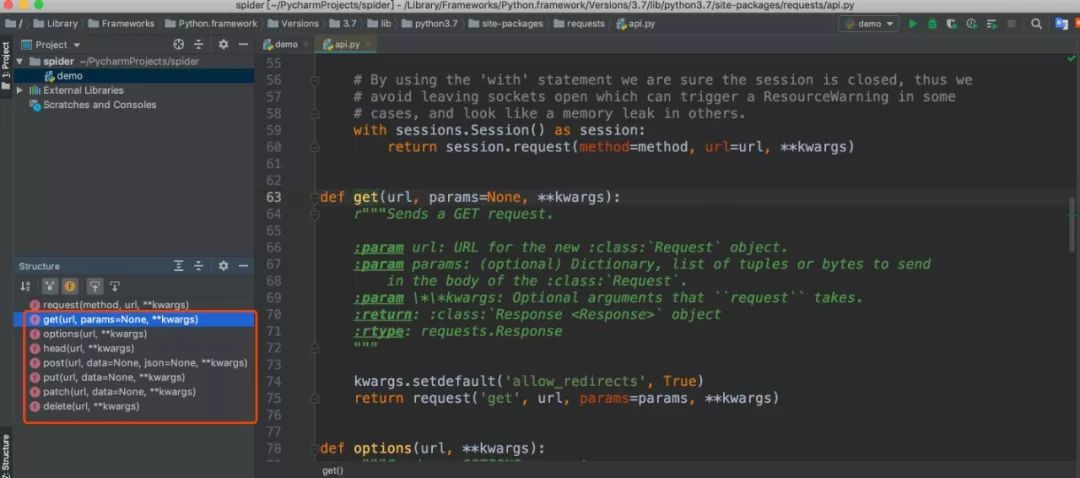
这里简单给大家列一下,后面会用大量的案例来用而后学,毕竟枯燥的讲解没人愿意看。
requests.post('http://httpbin.org/post', data = {'key':'value'})requests.patch('http://httpbin.org/post', data = {'key':'value'})requests.put('http://httpbin.org/put', data = {'key':'value'})requests.delete('http://httpbin.org/delete')requests.head('http://httpbin.org/get')requests.options('http://httpbin.org/get')注:httpbin.org是一个测试http请求的网站,能正常回应请求
看完上述内容,你们掌握Python爬虫的起点是什么的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
上述内容就是Python爬虫的起点是什么,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3936891/blog/4386342



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



