本篇文章给大家分享的是有关怎么探讨RPC框架中的服务线程隔离,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
微服务如今应当是一个优秀的程序员必须学习的一种架构思想,而RPC框架作为微服务的核心,不说读一遍源码吧,起码它的实现原理还是应该知道的。
然而目前的RPC服务框架,大多存在一个问题,就是当服务提供端Provider应用中,有的服务流量大,耗时长,导致线程池资源被这些服务占尽,从而影响同一应用中的其他服务正常提供。为此,下面主要介绍一下我对于这方面的思考。
在进入正文之前,可以先看一下阿里中间件岛风大佬的这篇博文(传送门),这篇博文复现了Dubbo应用中,线程池耗尽的场景。这其实在线上是十分普遍,解决方法无非是根据业务调整参数,或者引入其他的限流、资源隔离框架,例如Hystrix、Sentinel等,使得资源间互不干扰。其实本身Dubbo也可以对不同的服务配置不同的业务线程池(通过配置protocol)从而实现服务的资源隔离,但是这种方式的弊端在于,一旦服务增多,线程数量会迅速膨胀。线程池过多不便于统一管理,同时过多的线程所带来过多的上下文切换也会影响服务器性能。
在绝大多数场景下,对服务资源的隔离可以通过开源框架Sentinel来实现,其通过配置某个服务的并发数,来达到限流和线程资源隔离的目的。坦白的讲,这已经能够满足绝大多数需求了,但是手动取配置这些参数还是比较有难度的,大多得靠大佬们的经验了,而且也不够灵活。
我在学习的时候,也突发奇想,有没有可能不依赖外部的组件,而实现内部的服务资源隔离?再更进一步,有没有可能根据应用内各个服务的流量数据,对每个服务资源进行动态的分配和绑定呢?
打个比方说,某个应用里存在A、B两个服务,100个线程。白天的时候,A服务的流量大,B服务的流量很小,那么在这个时间段内,我们的应用分配给A的资源理应更多。但是也不能全给A拿走了,B也得喝口汤,不然又会出现线程耗尽的情况,所以此时我们可能根据流量数据的比对分给A服务80个线程,B服务20个线程;而到了晚上,A服务没啥人用了,B服务流量来了,那我们就给B更多的资源,但也要保证A可用,比如说,A服务20线程,B服务80线程。
我承认我一开始只是想简单写个RPC框架,学习实现原理而已。但突然有了这样一个想法,我就来了动力,想看看自己的想法行不行得通,下面我便介绍下我的思考,说的有不对的地方也欢迎大家指出和探讨。
借鉴了传统的RPC框架的实现原理后,我们只需要修改或者增加三样东西,就可以完成上述的功能,分别为:线程池、数据监控节点Metric和线程动态分配的Monitor。这三者之间的关系可以先看一下这张图有个大概的印象。
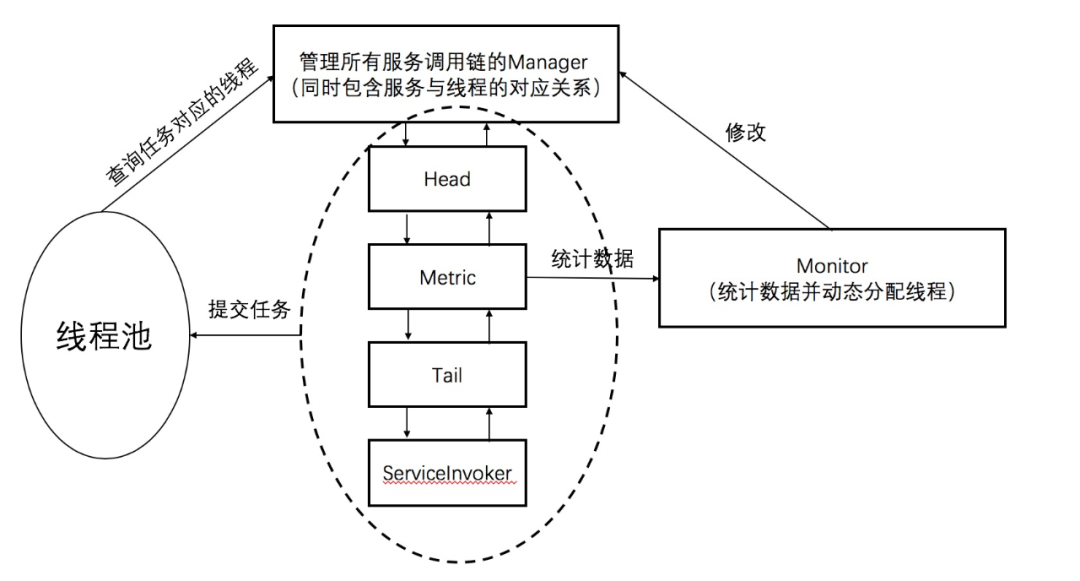
首先需要修改的自然是线程池。以Dubbo为例,其默认的线程池为fixed线程池,io线程接收到请求后,委托Dubbo线程池完成后续的处理,通过调用ExecutorService.execute。
但是在这里,使用JDK中的线程池显然是行不通了。线程池中的Thread也不再是单纯的Thread,而需要更进一步的抽象。这里参考Netty中NioEventLoop的设计思想,将每条Thread抽象为一条Loop,其既是任务执行的本体Thread,也是ExecutorService的抽象,而所有Loop交由LoopGroup统一管理,由LoopGroup决定将任务提交至哪一个线程。这里我实现的比较简单,每个线程有个专属的id,通过拿到线程的id,将任务提交到对应的线程,原理可以参考下图:
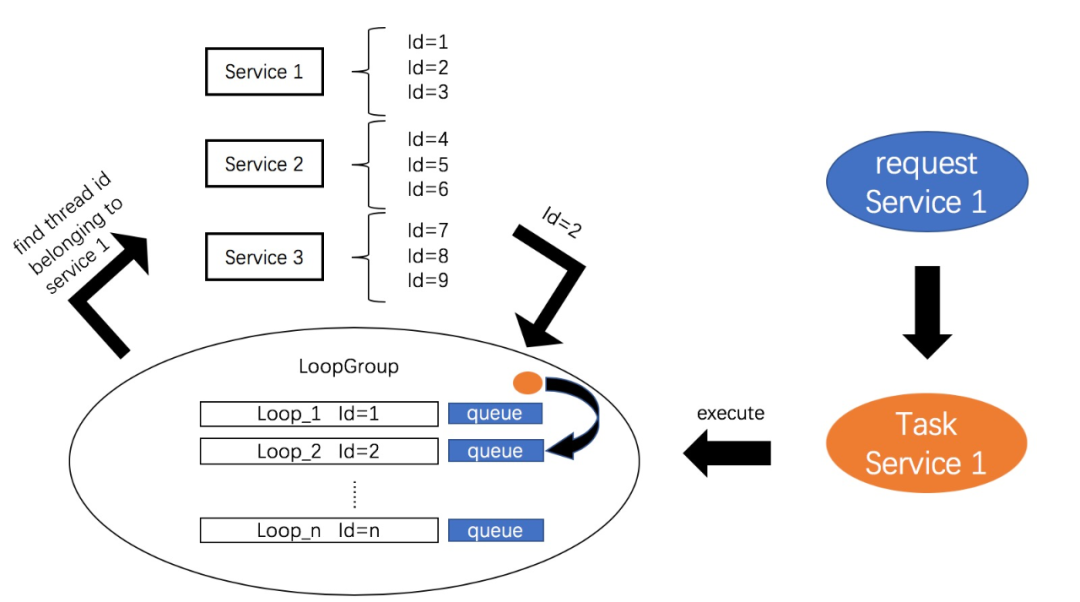
私以为核心在于维护服务与线程id的对应关系,以及在请求到来时,LoopGroup会根据请求中服务的类型,选择对应id的线程,并交由该线程去处理请求。
数据的监控相对来说是最好办的。这里我参考了Sentinel的实现,使用时间窗口法统计各个服务的流量数据,包括pass、success、rt、reject、excetpion等。(关于Sentinel中的时间窗口,后面有时间再专门写篇源码分析)
而至于监控节点的形式,根据调用链路的具体实现不同,在Dubbo中可以是一个filter,而我因为将调用链路抽象为一个Pipeline,所以它作为Pipeline上的一个节点,参考下图:
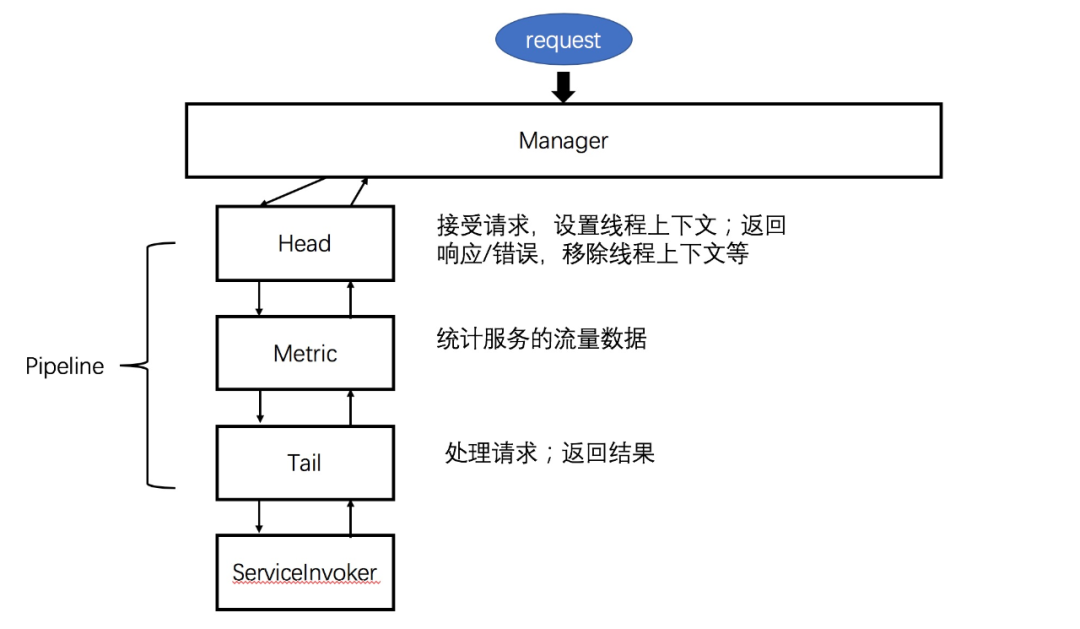
这里贴上MetricContext的关键源码:
//处理请求时,pass+1,同时记录开始时间并保存在线程上下文中@Overrideprotected void handle(Object obj) { if(obj instanceof RpcRequest){ RpcContext rpcContext=RpcContext.getContext(); rpcContext.setStartTime(TimeUtil.currentTimeMillis()); paladinMetric.addPass(1); }}//响应请求时,说明请求处理正常,则通过线程上下文拿到开始时间,//计算出响应时间rt后将rt写入统计数据,同时success+1@Overrideprotected void response(Object obj) { RpcContext rpcContext=RpcContext.getContext(); Long startTime=rpcContext.getStartTime(); if(startTime!=null){ Long rt=TimeUtil.currentTimeMillis()-startTime; paladinMetric.addRT(rt); paladinMetric.addSuccess(1); logger.warn(rpcContext.getRpcRequest().getClassName() +":" +rpcContext.getRpcRequest().getMethodName() +" 's RT is " +rt); }else{ logger.error(rpcContext.getRpcRequest().getClassName() +":" +rpcContext.getRpcRequest().getMethodName() +"has no start time!"); }}//这里就是统一处理异常的方法,区分为普通异常和拒绝异常,//如果是拒绝异常,说明线程已满,拒绝添加任务,reject+1@Overrideprotected void caughtException(Object obj) { paladinMetric.addException(1); if(obj instanceof RejectedExecutionException){ paladinMetric.addReject(1); }}每个Context都会继承AbstractContext,只需要实现handle、response和caughtException方法即可,由AbstractContext屏蔽了底层pipeline的顺序调用。
最后就是如何动态的将线程分配给服务。在这里,我们需要抽象一个评价模型,去评估各个服务应该占用多少资源(线程),可以参考下图:
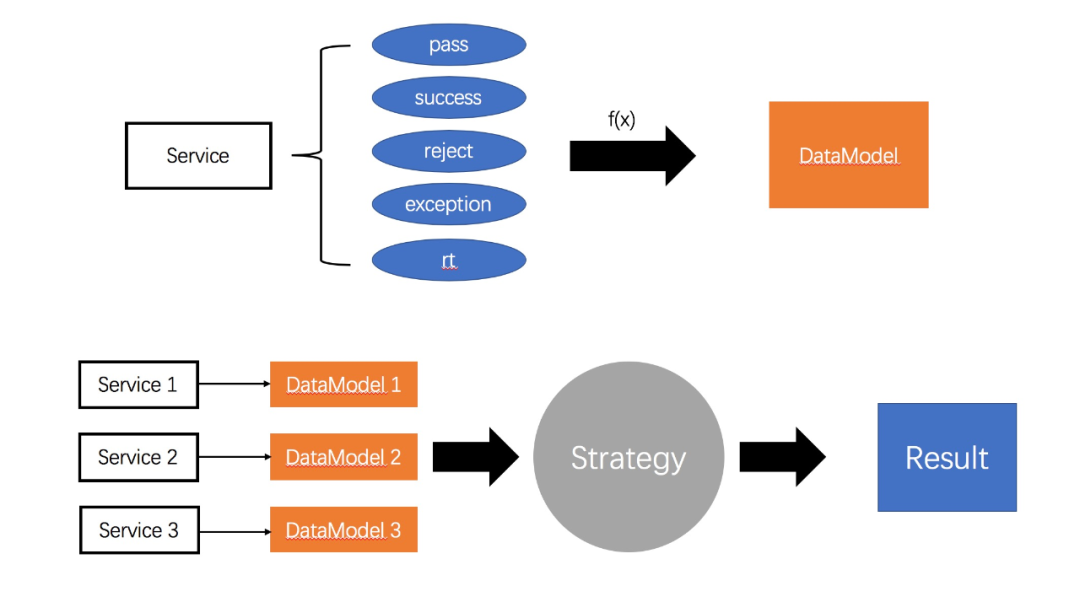
简单来说,由于监控节点的存在,我们很容易就拿到每个服务的流量数据,然后抽象出每一个服务的评价模型,最后通过某种策略,得到线程分配的结果。
同时服务-线程的对应关系的读写,显然是一个读多写少的场景。可以后台开启一个线程,每隔一段时间(比如20s),执行一次动态分配的策略。采用CopyOnWrite的思想,将对应关系的引用用volatile修饰,线程重新分配完成之后,直接替换掉其引用即可,这样对性能的影响便没有那么大了。
这里的问题在于,如何合理的制定分配的策略。由于我实在缺乏相应的经验,所以写的比较捞,希望有大佬可以指点一二。
说了这么多,那我们便来看看效果如何。代码我都放在了github上(由于时间比较短再加上本人菜,写得比较粗糙,请大家见谅T T),代码样例都在paladin-demo模块中,这里我就直接上结果了。
先定义一下参数,线程数总共20,每个服务最少能分配线程数为5,每条线程的阻塞队列容量为4,服务端两个服务,一个阻塞时间长,另一个无阻塞。
这里先定义一个阻塞时间长的服务HelloWorld。
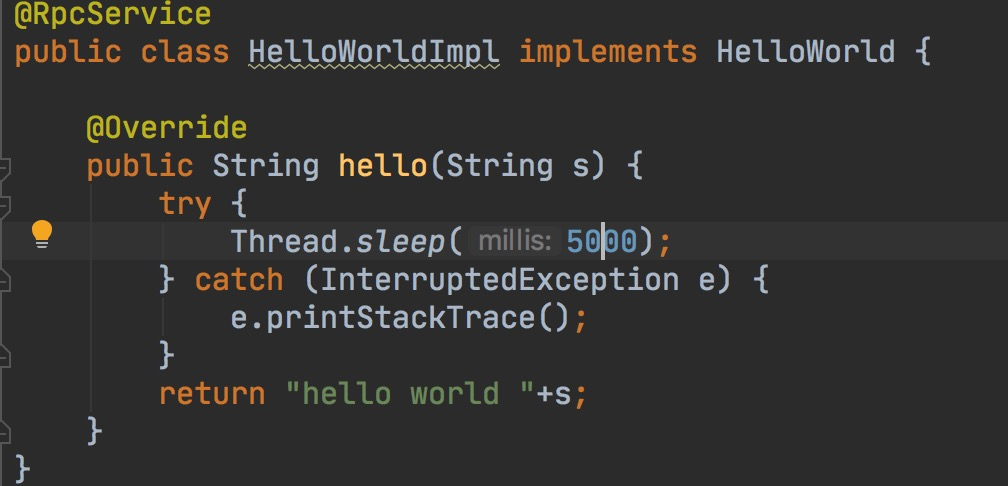
然后我们通过http请求触发任务,模拟大流量请求。
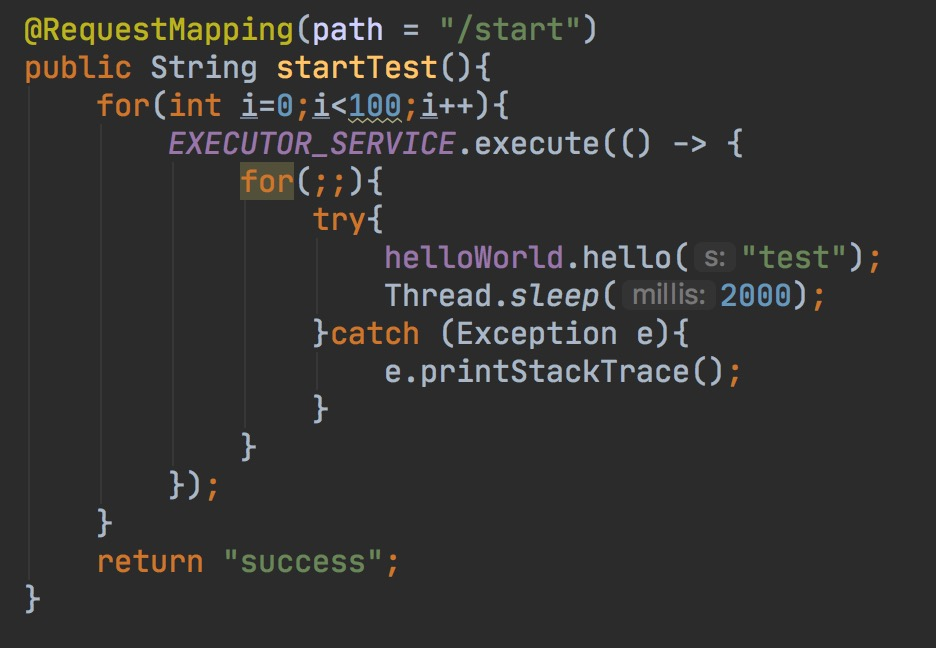
同时给出一个无阻塞的服务HelloPaladin,可以通过http访问。

先后启动服务服务提供端和消费端,开启任务。控制台直接炸裂。
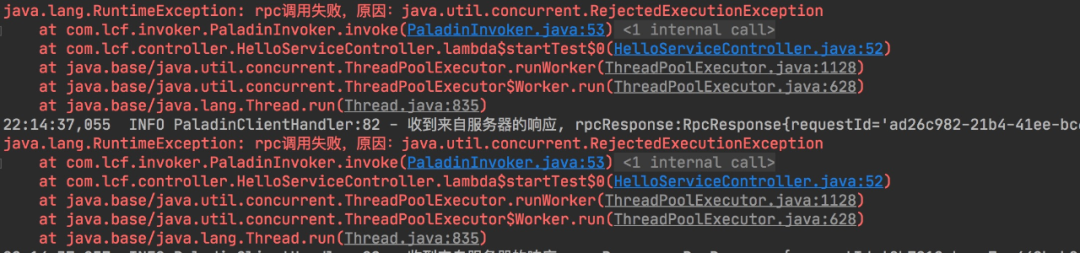
服务疯狂抛出拒绝异常。我们再输入localhost:8080/helloPaladin?value=lalala,多点几次,可以发现页面很快就能返回结果,这也意味着这个服务并没有被干扰。
最后我们来看一下,在任务启动后,线程分配的情况如何:
22:15:06,653 INFO PaladinMonitor:81 - totalScore: 59480722:15:06,653 INFO PaladinMonitor:91 - service: com.lcf.HelloPaladin:1.0.0_paladin, score: 164622:15:06,653 INFO PaladinMonitor:91 - service: com.lcf.HelloWorld:1.0.0_paladin, score: 59316122:15:06,654 INFO PaladinMonitor:113 - Threads re-distribution result: {com.lcf.HelloPaladin:1.0.0_paladin=[1, 2, 3, 4, 5], com.lcf.HelloWorld:1.0.0_paladin=[6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]}第一行输出的是所有服务总共的分数,接下来两行分别是两个服务所得到的分数,最后一行是线程分配之后的结果。
我们穿插调用的HelloPaladin服务得到的分数远远低于跑任务的服务HelloWorld,但是由于设置了最小线程数,所以HelloPaladin服务分到了5条线程,而HelloWorld服务占据了其余的线程。(这里由于还开启了一个单线程服务,所以没有0号线程,至于什么是单线程服务可以看后文)
可以看到,服务间的线程资源确实隔离了,某一个服务的不可用不会影响到其他服务,同时资源也会向大流量的服务倾斜。
在实现上面的功能之后,或许还有更加花哨的玩法。考虑这样一个场景,如果某个服务存在频繁加锁的场景,那么多个线程并发加锁执行,未必会有单个线程串行无锁执行来的效率高,毕竟锁和线程切换的开销也不容忽视。
在实现了服务与线程的对应关系之后,这种串行无锁执行的思路就很容易实现了,在初始化的时候,直接分配给这个服务固定的线程id号即可,这个线程也不会参与后续的动态分配流程。可以通过注解参数的方式来实现:
@RpcService(type = RpcConstans.SINGLE)public class HelloSynWorldImpl implements HelloSynWorld就是这么简单,服务器启动之后你就会发现,这个服务都会使用某条固定的线程去执行,自然也就用不着加锁了(除非要跟其他服务同时操作共享资源,那就不适用于这种场景),不过这种串行场景我想了想,好像并不多,只有在那种纯内存的操作中可能会比较有性能优势(是不是很像Redis),所以也就图一乐。
话又说回来了,虽然解决了服务资源隔离和分配的问题,那么相比原来的线程模型是否就没有劣势了呢?
因为加入了更多的组件,考虑到监控节点的性能损耗,增加了分配线程、选择线程的逻辑,或许在性能上相比原来的线程模型会差一点,至于差多少,我可能也没法定量给出解答,还需要进一步的测试。不过可以肯定的是,可以通过更多的优化,使得两者的性能更加接近,例如:用JcTool的无锁队列替换JDK中的阻塞队列;给出合适的评价模型,使得资源分配更合理以及分配过程性能更优等等。
当然最关键的还是你业务代码写的咋样,毕竟框架优化的再好,业务代码不大行,那点优化效果微乎其微。
以上就是怎么探讨RPC框架中的服务线程隔离,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4021601/blog/4449367



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



