本篇内容主要讲解“python爬虫如何绕过 CloudFlare 5秒盾”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“python爬虫如何绕过 CloudFlare 5秒盾”吧!
相信下面这个界面大家都不会陌生。【图1-1】
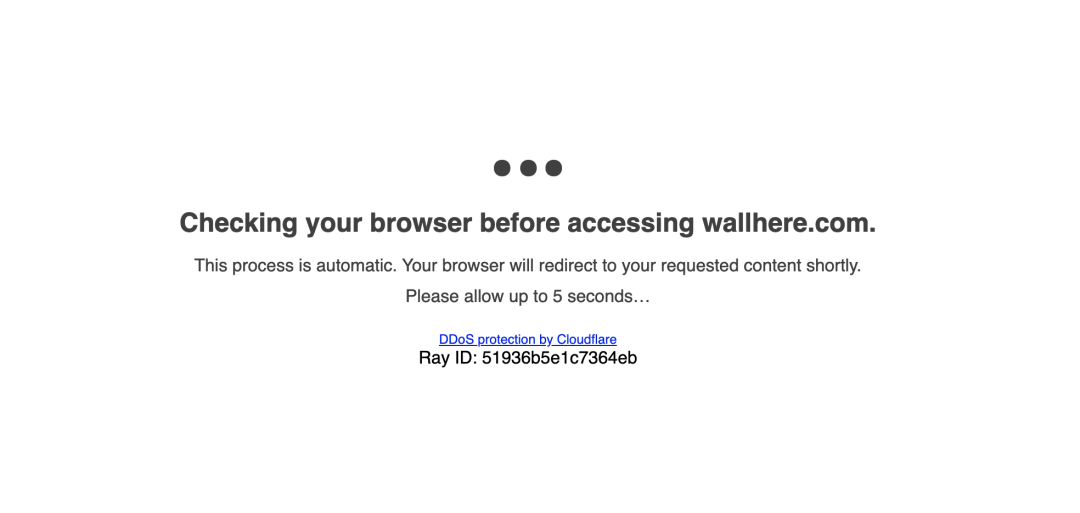
当我们第一次访问使用 CloudFlare 加速的网站时,网站就会出现让我们等待 5 秒种的提示,当我们需要的通过爬虫爬取这类网站的时候,应该如何爬取呢?
首先我们需要分析在这个等待的时间里浏览器做了哪些操作。
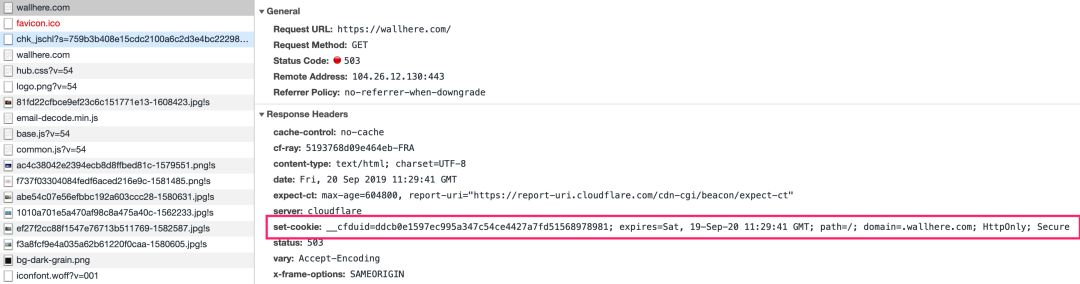
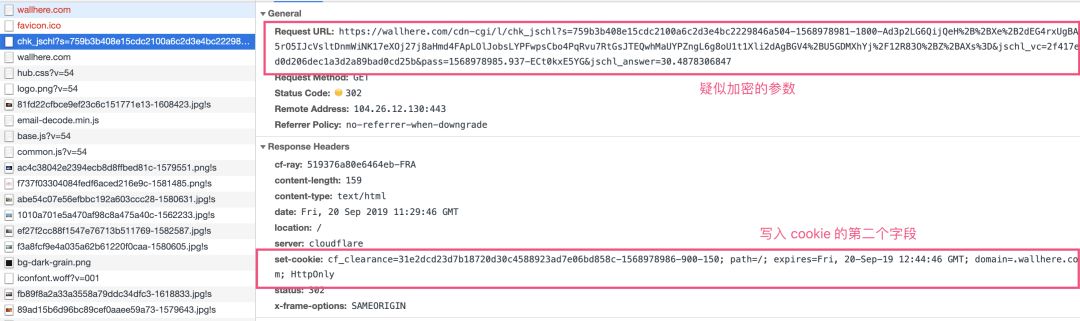
通过抓包,我们可以看到在等待的过程中,浏览器做了下面的三次请求【图1-2】- 【图1-4】:
【图1-2】请求 1 写入 cookie 字段 __cfduid
【图1-3】请求 2 带有疑似加密的请求参数请求并写入 cookie 字段 cf_clearance
【图1-4】请求 3 带上前面写入的cookie 请求网站首页,返回首页内容。

这整个过程需要的请求现在已经分析清楚了,接下来就是使用 Python 实现这个请求流程,不过是这样的话就配不上这个标题了。
先说说这个按照正常流程是怎么实现抓取绕过的:
使用浏览器模拟技术请求目标网站,例如:Selenium、 PhantomJS等
破解请求 2 的加密参数使用请求库模拟整个请求过程
这两个方法当然是可以抓取的,但是都不符合标题的巧字。
接下来给大家介绍一个专门为了绕过这个 CloudFlare 开发的 Python 库 cloudflare-scrape
用上它就可以无感爬取使用了 CloudFlare 的网站,使用这个库非常简单。
使用pip install cfscrape安装cloudflare-scrape,同时确认本地是否安装node.js开发环境,如果没有,需要安装配置nodejs开发环境。
处理 get 请求的 CloudFlare
import cfscrape
# 实例化一个create_scraper对象
scraper = cfscrape.create_scraper()
# 请求报错,可以加上时延
# scraper = cfscrape.create_scraper(delay = 10)
# 获取网页源代码
web_data = scraper.get("https://wallhere.com/").content
print(web_data)
处理 post 请求的 CloudFlare
# import cfscrape
# 实例化一个create_scraper对象
scraper = cfscrape.create_scraper()
# 获取真实网页源代码
web_data = scraper.post("http://example.com").content
print(web_data)使用cloudflare-scrape后整个请求过程如丝般顺滑。
到此,相信大家对“python爬虫如何绕过 CloudFlare 5秒盾”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





