如何分析POSTGRESQL FULL PAGE优化与CHECKPOINT的矛盾,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
在说完mysql 不要关DW 后,祭出 POSTGRESQL FULL PAGE 的确是有点不厚道,所以必然会引出 FULL PAGE 也存在性能问题的话题。到底是大公鸡和大马猴的问题,还是小绵羊的牧羊犬的故事。
首先FULL PAGE 和 MYSQL的 DW 一样,都是为了解决数据库CRASH 时数据的那一刻存在的缺失问题。我看来看看相关的解释
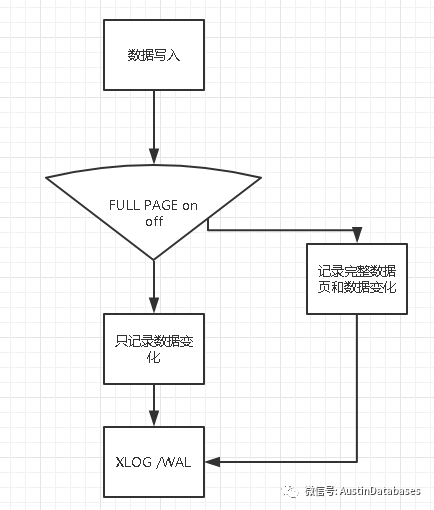
PostgreSQL 在 checkpoint 之后在对数据页面的第一次写的时候会将整个数据页面写到 xlog 里面。当出现主机断电或者OS崩溃时,redo操作时通过checksum发现“部分写”的数据页,并将xlog中保存的这个完整数据页覆盖当前损坏的数据页,然后再继续redo就可以恢复整个数据库了。
看完以后会突然冒出一个想法
1 checkpoint 越密集,那FULL PAGE 也就越多咯
2 FULL PAGE 第一个页面的大小会影响写性能
那我关掉FULL PAGE 不就好了
当然不是,FULL PAGE 在某些时候,不是你要开就开,要关就关的,尤其你在操作 pg_basebackup(或者一连串利用这命令的伪装者们)的操作时 FULL PAGE 是强制打开的,到底为什么这就不解释了,和 备份的原理有关。
其实这个想法是比较巧妙的,他仅仅针对CHECK POINT 的第一个页面进行检测并写入到 XLOG 中
而提出异议或否定的意见是,full_page_write需要在xlog(wal)中记录数据页,会进行更多写操作,不仅数据变,还有数据页的信息,这会增加的IO和磁盘消耗,引起主备延迟变大。
另外具体相关的FULL PAGE 的解释和讲解,参见下边的图,如有需要(可以入群,免费下载相关书籍)

于此同时,很多的优化的方法就来了 ,有一种就很像 MYSQL的 DW 的方式来优化PG 的FULL PAGE 方式, 但需要在PG上打PATCH。(这里不详细展开)
另外降低CHECKPOINT 的频率也可以降低 FULL PAGE 所带来的性能影响,也有提出将PG的数据页面在编译的时候变小(个人觉得有点过了), 当然这还不是终极的优化方法,还有的文章中提出了,使用序列,与 UUID 对FULL PAGE 的不同的性能影响,其中指出,如果使用序列的方式,则在插入同样行数的数据时,对比 UUID ,产生的WAL 的大小相差20倍。

其中关键的一段话在上,提出如果使用序列的方式作为主键,则插入到btree索引中的相同叶页面,只有对页面的第一次修改才会触发整个页面的写入。UUID是完全不同的情况,UUID值完全不是连续的,实际上每次插入都可能接触到全新的叶索引叶页面,造成写入日志的量大影响I/O的性能。
上文中也提出可以调整 CHECK POINT 的间距,来降低FULL PAGE 造成的影响,具体怎么调整CHECK POINT 的间距。

上面是我们在每个PG 中都能看到的与CHECKPOINT 有关的东西,在一个负载很重的系统中,我们是否可以将MAX_WAL_SIZE 调大,(有人可能会问这个数字初期是怎么来的,那我觉得你可能对PG的安装方面还可以在了解一下),调整到多大,8 - 10G 是没有问题的。增加检查点之间的距离可以减少WAL -但是为什么会发生这种情况呢?请记住:将事务日志放在首位的目的是确保系统在崩溃后仍然能够正常运行。将WAL中的这些更改应用到数据文件将修复数据文件并在启动时恢复系统。为了安全起见,PostgreSQL不能简单地记录对一个块所做的更改—如果一个块在通过检查点后第一次被更改,那么整个页面都必须被发送到WAL。
两个检查点之间的距离不仅由于检查点的减少而提高了速度,更少的检查点还会影响所写事务日志的数量。所以在优化FULL PAGE 的时候是要考虑,降低检查点,其实这和 MYSQL 里面调整innodb log file size 是一个意思。
在 Postgresql 11 Administratoration Cookbook, 这本书中的427页也中对这两个参数也有相关的讲解,
两个参数控制CHECKPOINT发生的频率与预期,首先checkpoint_timout 这个参数会触发在上一次CHECKPOINT 发生后多少秒后,进行HECKPOINT,这直接影响有多少量的 WAL data 将要写入目标文件,实际上控制WAL写入的数量的参数有两个地方
MAX_WAL_SIZE
CHECKPOINT_TIMEOUT
然而当你调大参数,你应该考虑系统如果CRASH 后的恢复时间,与多长时间做一次CHECKPOINT 之间做一个衡量,并且也要考虑WAL 日志的空间在磁盘上是否有充足的空间。
同时除2个参数可以优化FULL PAGE 的性能的同时,是否还有其他的方法,我们知道 WAL 日志的也是有缓冲,默认是同步提交,只要是有COMMIT 日志信息就会刷入到磁盘, wal_buffers可以调整wal_buffer 的大小,并且调整 synchronous_commit 不在同步提交,减少磁盘交互,但这会打破系统CRASH 后的数据库安全,有数据库丢失的风险。
那怎么有的放矢的更大利用wal_buffers ,可以根据业务,在某些情况下,通过调整下面的参数在session 的级别,来对某些可以容忍 1秒内数据库丢失的情况中,将syschronous_commit = off.

看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4582201/blog/4378092



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



