这篇文章将为大家详细讲解有关MySQL Cost中怎么优化语句,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
小文一个数据库新鸟,但脾气比较急?今天有程序员问他新上的业务有没有不好的SQL 语句, 小文没好气的说,怎么看,你们自己写的,问我?
程序员也没好气的回怼 ? 我算是问错人了,估计你也不会看COST ,优化问你算是白瞎了。
到底怎么能快速应付程序员的 ASKING 并且还能技高一筹的回怼他。Follow me.
基本每种数据库,在执行语句前都会评估执行语句的执行计划的 cost ,通过cost 来判断到底目前哪个 prepare plan 更好更快更强?
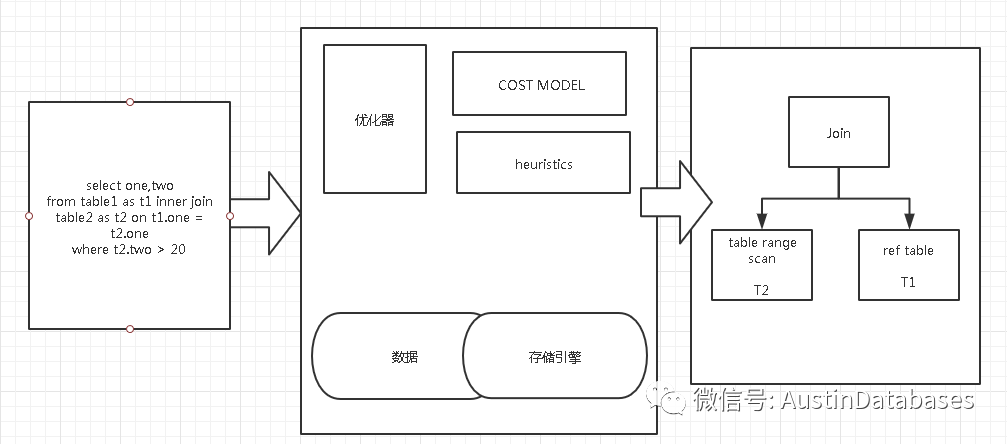
大致画了一个图
首先数据库的获知, 1 操作的成本 , 2 是否有替换的方案 3 在众多的方案中找到“最低”的执行计划
上边的查询会包含几个 点 1 JOIN 的次序, 2 访问的方法 3 子查询
那到底怎么评判那个 JOIN 的次序好,方法秒,子查询怎么查,MYSQL 基于 CPU I/O 两个量来进行计算和最重的判断哪个COST 最低.
那下面问题来了,到底我怎么知道我要访问的表的cost是多少,有没有索引,索引里面怎么设置的。
那就引出 METADATA 数据库表状态, 其中包含了 row ,index 的SIZE, index 的信息, 是否是唯一的索引, 表的大小, 范围的评估 ,基数等等信息,(今天不谈统计信息)
STOP STOP 你巴拉巴拉说了这么多,对我有什么帮助? 小文愤怒到,你就告诉我怎么优化 那个什么鬼 语句?
好的我们先打开 OPTIMIZER_TRACE 功能 (小文:我不知道
我们先执行一条语句
select *
from employees as em
left join titles as ti on em.emp_no = ti.emp_no
left join (select emp_no from salaries where salary > 40000) as sa on em.emp_no = sa.emp_no limit 1;
然后我们在打开OPTIMIZER_TRACE功能的状态下, 执行这条语句后,我们看看OPTIMIZER_TRACE能给我什么?
首先通过 optimizer_trace可以看到,一条语句的执行过程分为三个步骤
1 preparation 2 optimization 3 execution

下面我们根据上面的语句以及 OPTIMIZER_TRACE反馈的信息,来看看到底MYSQL 在prepare 阶段做了什么。
1 格式化语句,由于语句撰写的不规范,所以语句一般都会在第一步进行规范的转换,例如字段,条件不带数据库前缀的等等

最终我们的上边的语句被格式化成下面图的样子

OK ,在基本上准备好要优化的语句后,下面就需要优化器开始优化了,一般提到优化就有次序的问题,到底怎么优化有是怎么个次序
在本次优化的语句,优化的步骤有 8步

1 condition_processing 首先先判断是否有 where 条件,由于语句最外层没有 where 条件,这里显示的是为 null

2 在下面是开始整理相关的表关系 table_dependencies

其中row_may_be_null:列是否允许为NULL,意思不是指表中的列属性是否允许为NULL,这里说的是JOIN操作之后的列是否为NULL,是一个集合的概念,所以写语句如果可以写 JOIN 或者 INNER JOIN 就别在大大咧咧的写 LEFT JOIN 。
3 下面是要考虑可能会产生键与键之间的关联

4 然后给出了各个参与运算表的全表扫描的行数并且给出了cost 值,这里的表的行数准不准,或者cost 值是否能调整, 答案是行可能不准,cost 值可以调(PG 就可以调,并且可以很方便的调)

有人可能会问为什么呢,全都是全表扫描,看看执行计划便知,没有索引

小文插嘴道,哎哎哎 没索引 ,我加索引不就完了
别急:优化语句可不是这样做的,如果光是添加索引这么简单,那不谁都会做了。优化语句,首先要明白业务逻辑(能从逻辑入手的那才是高手),然后在看语句的撰写是否是标准并符合当前数据库的优化引擎的要求,最后才是添加索引。如果在第一步就发现这条语句根本不符合业务逻辑,那你连优化的必要都没有直接就CANCEL这条语句了。
那现在怎么办? 小文问道
我们先看完当前的 optimizer_trace 在继续好吧
最后我们看一下生成的执行计划, MYSQL 会将几个执行计划进行比较,下面可以看到会出现一个 considered_execution_plan 和 rest_of_plan
前面的就是要使用的执行计划,而后面是多个执行计划进行比对败下阵的执行计划这里不再多说。具体的可以自己做一下,比对一下。

那我们添加索引吧 ?小文说到 ,别急 我们在来看看这语句的写法
下面这两条语句最后的结果都是一样的,那个你觉得更优
select *
from (select emp_no from salaries where salary > 40000) as sa
left join titles as ti on ti.emp_no = sa.emp_no
left join employees as em on ti.emp_no = em.emp_no limit 1;
select *
from employees as em
left join titles as ti on em.emp_no = ti.emp_no
left join (select emp_no from salaries where salary > 40000) as sa on em.emp_no = sa.emp_no limit 1;
另外这条语句的逻辑要干什么?如果是语句的意思是,找到雇员里面工资超过40000块的雇员的名单。你觉得他这样写对吗?
是是是,我去问问,小文答到。
最后的结果是什么小文,小文不好意思的回答,给开发看完语句他们说些的语句不对,他们重新写,大致的意思是找到雇员里面工资曾经超过 40000人员的名单。(如果是工资表,那里面可以没有去重,获得名单都是重复的)
后面他们给的语句是
select distinct * from (
select em.emp_no,em.first_name,em.last_name
from employees as em
inner join (select emp_no from salaries where salary > 40000) as sa on em.emp_no = sa.emp_no) as a
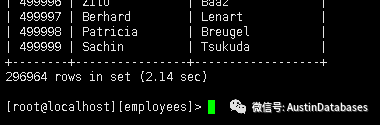
NO NO NO ,小文你看看如果我们把他们的语句改写成这样如何,快了不到0.9秒。
select em.emp_no,em.first_name,em.last_name
from (select distinct emp_no from salaries where salary > 40000) as sa
inner join employees as em on em.emp_no = sa.emp_no;

小文喜上眉梢,问为什么这样写会快 ??? 老鸟瞟了一眼小文,“保密”
其实SQL 语句的优化,可以走这样一个步骤
1 弄清语句的业务逻辑,能在业务逻辑上修改,或者优化的就不要推到语句的层面
2 在语句的层面要理解所在数据库的优化引擎大致的工作原理,将不符合优化器的语句,进行修改
3 根据最后定型的语句,添加适当的索引,加速语句的执行
关于MySQL Cost中怎么优化语句就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





