这篇文章将为大家详细讲解有关如何用nodejs源码分析线程,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
我们先看一下一般的使用例子。
const { Worker, isMainThread, parentPort } = require('worker_threads');if (isMainThread) { const worker = new Worker(__filename); worker.once('message', (message) => { ... }); worker.postMessage('Hello, world!');} else { // 做点耗时的事情 parentPort.once('message', (message) => { parentPort.postMessage(message); });}我们先分析一下这个代码的意思。因为上面的代码在主线程和子线程都会被执行一遍。所以首先通过isMainThread判断当前是主线程还是子线程。主线程的话,就创建一个子线程,然后监听子线程发过来的消息。子线程的话,首先执行业务相关的代码,还可以监听主线程传过来的消息。下面我们开始分析源码。分析完,会对上面的代码有更多的理解。
首先我们从worker_threads模块开始分析。这是一个c++模块。我们看一下他导出的功能。require("work_threads")的时候就是引用了InitWorker函数导出的功能。
void InitWorker(Local<Object> target, Local<Value> unused, Local<Context> context, void* priv) { Environment* env = Environment::GetCurrent(context); { // 执行下面的方法时,入参都是w->GetFunction() new出来的对象 // 新建一个函数模板,Worker::New是对w->GetFunction()执行new的时候会执行的回调 Local<FunctionTemplate> w = env->NewFunctionTemplate(Worker::New); // 设置需要拓展的内存,因为c++对象的内存是固定的 w->InstanceTemplate()->SetInternalFieldCount(1); w->Inherit(AsyncWrap::GetConstructorTemplate(env)); // 设置一系列原型方法,就不一一列举 env->SetProtoMethod(w, "setEnvVars", Worker::SetEnvVars); // 一系列原型方法 // 导出函数模块对应的函数,即我们代码中const { Worker } = require("worker_threads");中的Worker Local<String> workerString = FIXED_ONE_BYTE_STRING(env->isolate(), "Worker"); w->SetClassName(workerString); target->Set(env->context(), workerString, w->GetFunction(env->context()).ToLocalChecked()).Check(); } // 导出getEnvMessagePort方法,const { getEnvMessagePort } = require("worker_threads"); env->SetMethod(target, "getEnvMessagePort", GetEnvMessagePort); /* 线程id,这个不是操作系统分配的那个,而是nodejs分配的,在新开线程的时候设置 const { threadId } = require("worker_threads"); */ target ->Set(env->context(), env->thread_id_string(), Number::New(env->isolate(), static_cast<double>(env->thread_id()))) .Check(); /* 是否是主线程,const { isMainThread } = require("worker_threads"); 这边变量在nodejs启动的时候设置为true,新开子线程的时候,没有设置,所以是false */ target ->Set(env->context(), FIXED_ONE_BYTE_STRING(env->isolate(), "isMainThread"), Boolean::New(env->isolate(), env->is_main_thread())) .Check(); /* 如果不是主线程,导出资源限制的配置, 即在子线程中调用const { resourceLimits } = require("worker_threads"); */ if (!env->is_main_thread()) { target ->Set(env->context(), FIXED_ONE_BYTE_STRING(env->isolate(), "resourceLimits"), env->worker_context()->GetResourceLimits(env->isolate())) .Check(); } // 导出几个常量 NODE_DEFINE_CONSTANT(target, kMaxYoungGenerationSizeMb); NODE_DEFINE_CONSTANT(target, kMaxOldGenerationSizeMb); NODE_DEFINE_CONSTANT(target, kCodeRangeSizeMb); NODE_DEFINE_CONSTANT(target, kTotalResourceLimitCount);}翻译成js大概是
function c++Worker(object) { // 关联起来,后续在js层调用c++层函数时,取出来,拿到c++层真正的worker对象 object[0] = this; ...}function New(object) { const worker = new c++Worker(object);}function Worker() { New(this);}Worker.prototype = { startThread,StartThread, StopThread: StopThread, ...}module.exports = { Worker: Worker, getEnvMessagePort: GetEnvMessagePort, isMainThread: true | false ...}了解work_threads模块导出的功能后,我们看new Worker的时候的逻辑。根据上面代码导出的逻辑,我们知道这时候首先会新建一个c++对象。对应上面的Worker函数中的this。然后执行New回调,并传入tihs。我们看New函数的逻辑。我们省略一系列的参数处理,主要代码如下。
// args.This()就是我们刚才传进来的thisWorker* worker = new Worker(env, args.This(), url, per_isolate_opts, std::move(exec_argv_out));我们再看Worker类。
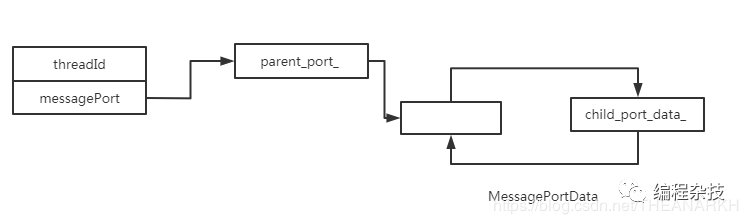
Worker::Worker(Environment* env, Local<Object> wrap,...) // 在父类构造函数中完成对象的Worker对象和args.This()对象的关联 : AsyncWrap(env, wrap, AsyncWrap::PROVIDER_WORKER), ... // 分配线程id thread_id_(Environment::AllocateThreadId()), env_vars_(env->env_vars()) { // 新建一个端口和子线程通信 parent_port_ = MessagePort::New(env, env->context()); /* 关联起来,用于通信 const parent_port_ = {data: {sibling: null}}; const child_port_data_ = {sibling: null}; parent_port_.data.sibling = child_port_data_; child_port_data_.sibling = parent_port_.data; */ child_port_data_ = std::make_unique<MessagePortData>(nullptr); MessagePort::Entangle(parent_port_, child_port_data_.get()); // 设置Worker对象的messagePort属性为parent_port_ object()->Set(env->context(), env->message_port_string(), parent_port_->object()).Check(); // 设置Worker对象的线程id,即threadId属性 object()->Set(env->context(), env->thread_id_string(), Number::New(env->isolate(), static_cast<double>(thread_id_))) .Check();}新建一个Worker,结构如下
constructor(filename, options = {}) { super(); // 忽略一系列参数处理,new Worker就是上面提到的c++层的 this[kHandle] = new Worker(url, options.execArgv, parseResourceLimits(options.resourceLimits)); // messagePort就是上面图中的messagePort,指向_parent_port this[kPort] = this[kHandle].messagePort; this[kPort].on('message', (data) => this[kOnMessage](data)); // 开始接收消息,我们这里不深入messagePort,后续单独分析 this[kPort].start(); // 申请一个通信管道,两个端口 const { port1, port2 } = new MessageChannel(); this[kPublicPort] = port1; this[kPublicPort].on('message', (message) => this.emit('message', message)); // 向另一端发送消息 this[kPort].postMessage({ argv, type: messageTypes.LOAD_SCRIPT, filename, doEval: !!options.eval, cwdCounter: cwdCounter || workerIo.sharedCwdCounter, workerData: options.workerData, publicPort: port2, manifestSrc: getOptionValue('--experimental-policy') ? require('internal/process/policy').src : null, hasStdin: !!options.stdin }, [port2]); // 开启线程 this[kHandle].startThread(); }上面的代码主要逻辑如下
1 保存messagePort,然后给messagePort的对端(看上面的图)发送消息,但是这时候还没有接收者,所以消息会缓存到MessagePortData,即child_port_data_ 中。
2 申请一个通信管道,用于主线程和子线程通信。_parent_port和child_port是给nodejs使用的,新申请的管道是给用户使用的。
3 创建子线程。
我们看创建线程的时候,做了什么。
void Worker::StartThread(const FunctionCallbackInfo<Value>& args) { Worker* w; // 解包出对应的Worker对象 ASSIGN_OR_RETURN_UNWRAP(&w, args.This()); // 新建一个子线程,然后执行Run函数,从此在子线程里执行 uv_thread_create_ex(&w->tid_, &thread_options, [](void* arg) { w->Run(); }, static_cast<void*>(w))}我们继续看Run
void Worker::Run() { { // 新建一个env env_.reset(new Environment(data.isolate_data_.get(), context, std::move(argv_), std::move(exec_argv_), Environment::kNoFlags, thread_id_)); // 初始化libuv,往libuv注册 env_->InitializeLibuv(start_profiler_idle_notifier_); // 创建一个MessagePort CreateEnvMessagePort(env_.get()); // 执行internal/main/worker_thread.js StartExecution(env_.get(), "internal/main/worker_thread"); // 开始事件循环 do { uv_run(&data.loop_, UV_RUN_DEFAULT); platform_->DrainTasks(isolate_); more = uv_loop_alive(&data.loop_); if (more && !is_stopped()) continue; more = uv_loop_alive(&data.loop_); } while (more == true && !is_stopped()); }}我们分步骤分析上面的代码
1 CreateEnvMessagePort
void Worker::CreateEnvMessagePort(Environment* env) { child_port_ = MessagePort::New(env, env->context(), std::move(child_port_data_)); if (child_port_ != nullptr) env->set_message_port(child_port_->object(isolate_));}child_port_data_这个变量我们应该很熟悉,在这里首先申请一个新的端口。负责端口中数据管理的对象是child_port_data_。然后在env缓存起来。一会要用。
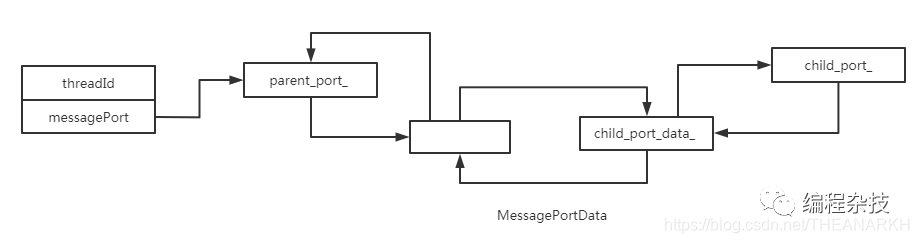
// 设置process对象patchProcessObject();// 获取刚才缓存的端口onst port = getEnvMessagePort();port.on('message', (message) => { // 加载脚本 if (message.type === LOAD_SCRIPT) { const { argv, cwdCounter, filename, doEval, workerData, publicPort, manifestSrc, manifestURL, hasStdin } = message; const CJSLoader = require('internal/modules/cjs/loader'); loadPreloadModules(); /* 由主线程申请的MessageChannel管道中,某一端的端口, 设置publicWorker的parentPort字段,publicWorker就是worker_threads导出的对象,后面需要用 */ publicWorker.parentPort = publicPort; // 执行时使用的数据 publicWorker.workerData = workerData; // 通知主线程,正在执行脚本 port.postMessage({ type: UP_AND_RUNNING }); // 执行new Worker(filename)时传入的文件 CJSLoader.Module.runMain(filename);})// 开始接收消息port.start()这时候我们再回头看一下,我们调用new Worker(filename),然后在子线程里执行我们的filename时的场景。我们再次回顾前面的代码。
const { Worker, isMainThread, parentPort } = require('worker_threads');if (isMainThread) { const worker = new Worker(__filename); worker.once('message', (message) => { ... }); worker.postMessage('Hello, world!');} else { // 做点耗时的事情 parentPort.once('message', (message) => { parentPort.postMessage(message); });}我们知道isMainThread在子线程里是false,parentPort 就是就是messageChannel中的一端。所以parentPort.postMessage给对端发送消息,就是给主线程发送消息,我们再看看worker.postMessage('Hello, world!')。
postMessage(...args) { this[kPublicPort].postMessage(...args); }kPublicPort指向的就是messageChannel的另一端。即给子线程发送消息。那么on('message')就是接收对端发过来的消息。
关于如何用nodejs源码分析线程就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4217331/blog/4473938



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



