今天就跟大家聊聊有关MongoDB开发系中什么是数据集设计分桶范式,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
数据集设计模式,MongoDB在官方文档https://docs.mongodb.com/ecosystem/ 中的use cases部分提供了详细的参考内容。
分桶模式是MongoDB数据集设计的一种范式。
所谓分桶优化,就是与其对每一条数据创建一个文档,我们可以把某一个时间段内的测量数据聚合到一起放到一个文档内,利用MongoDB提供的内嵌式数组或子文档特性
我们知道许多传感器数据都是时间序列数据。例如:风传感器,潮汐监测以及位置追踪等采集数据的无非这种类型: Timestamp,采集器名称/ID,采集值。对于时序类型的数据,我们可以采用一种叫做时间分桶的优化策略。
简单的说 时间序列就是各时间点上形成的数值序列,时间序列分析就是通过观察历史数据预测未来的值。采用分桶设计写入的数据集,元素更多的是采用时间作为排序元素,依次写入和读取。
官方有一篇翻译文章,专门叙述 分桶设计模式
基础数据集如下
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:00:00.000Z"),
temperature: 40
}
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:01:00.000Z"),
temperature: 40
}
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:02:00.000Z"),
temperature: 41
}
改进后的文档集如下
{
sensor_id: 12345,
start_date: ISODate("2019-01-31T10:00:00.000Z"),
end_date: ISODate("2019-01-31T10:59:59.000Z"),
measurements: [
{
timestamp: ISODate("2019-01-31T10:00:00.000Z"),
temperature: 40
},
{
timestamp: ISODate("2019-01-31T10:01:00.000Z"),
temperature: 40
},
…
{
timestamp: ISODate("2019-01-31T10:42:00.000Z"),
temperature: 42
}
],
transaction_count: 42,
sum_temperature: 2413
}
我们在程序写入文档时,可以做一些简单的计算和整理,按时间分段,根据业务需要,将一个时间断内的大量文档合并,避免数据使用时的随机聚合和查询。这样的时间段,可以理解为桶。
在处理时间序列数据时,知道2018年7月13日加利福尼亚州康宁市下午2:00至3:00的平均温度通常比知道下午2:03那一时刻的温度更有意义也更重要。通过用桶组织数据并进行预聚合,我们可以更轻松地提供这些信息。
官方有一篇关于Iot使用场景的推荐文章 https://www.mongodb.com/customers/bosch,可以作为参考。
https://docs.mongodb.com/ecosystem/use-cases/storing-comments/ Hybrid Schema Design节点下说明了评论中的分桶操作场景。
首先我们看数据集模式
_id: ObjectId(...),
discussion_id: ObjectId(...),
bucket: 1,
count: 42,
comments: [ {
slug: '34db',
posted: ISODateTime(...),
author: { id: ObjectId(...), name: 'Rick' },
text: 'This is so bogus ... ' },
... ]
}
我在数据集设计的文章中提到分桶模式的设计场景,主要用于时间序列的数据预处理和分块存储。时间序列也就是按照时间的先后排序,依次写入。分块的标准可以是时间,比如一天,一个小时,或者是评论数目。
Also, 100 comments is a soft limit for the number of comments per bucket. This value is arbitrary: choose a value that will prevent the maximum document size from growing beyond the 16MB BSON documentsize limit,
以上总体含义是说每个桶内的元素个数不是固定的,是应用开发时,根据实际情况评估后的一个度量。但是需要考虑MongoDB本身每个文档最多16M的限制。
对于应用程序来说,这样的设计模式在写入操作是需要做一些简单的逻辑,来确定写入哪个桶,以及简单计算,如下
if bucket['count'] > 100:
db.discussion.update(
{ 'discussion_id: discussion['_id'],
'num_buckets': discussion['num_buckets'] },
{ '$inc': { 'num_buckets': 1 } } )
借助2019年MongoDB中国用户大会的一张PPT更加清晰的认识下分桶范式
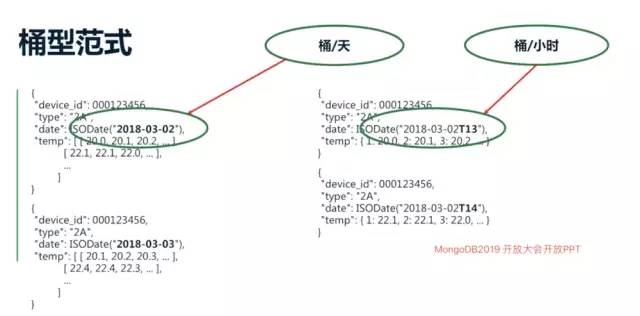
buckets.png
文章中的观点有不严谨之处,欢迎评论沟通。边学习,边实践,边参考,边改进,在问题中成长。
看完上述内容,你们对MongoDB开发系中什么是数据集设计分桶范式有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





