这篇文章主要讲解了“HashMap遍历方法是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“HashMap遍历方法是什么”吧!
Iterator<Map.Entry<String, Integer>> entryIterator = map.entrySet().iterator(); while (entryIterator.hasNext()) { Map.Entry<String, Integer> next = entryIterator.next(); System.out.println("key=" + next.getKey() + " value=" + next.getValue()); }Iterator<String> iterator = map.keySet().iterator(); while (iterator.hasNext()){ String key = iterator.next(); System.out.println("key=" + key + " value=" + map.get(key)); }map.forEach((key,value)->{ System.out.println("key=" + key + " value=" + value);});强烈建议使用第一种 EntrySet 进行遍历。
第一种可以把 key value 同时取出,第二种还得需要通过 key 取一次 value,效率较低, 第三种需要 JDK1.8 以上,通过外层遍历 table,内层遍历链表或红黑树。
在并发环境下使用 HashMap 容易出现死循环。
并发场景发生扩容,调用 resize() 方法里的 rehash() 时,容易出现环形链表。这样当获取一个不存在的 key 时,计算出的 index 正好是环形链表的下标时就会出现死循环。
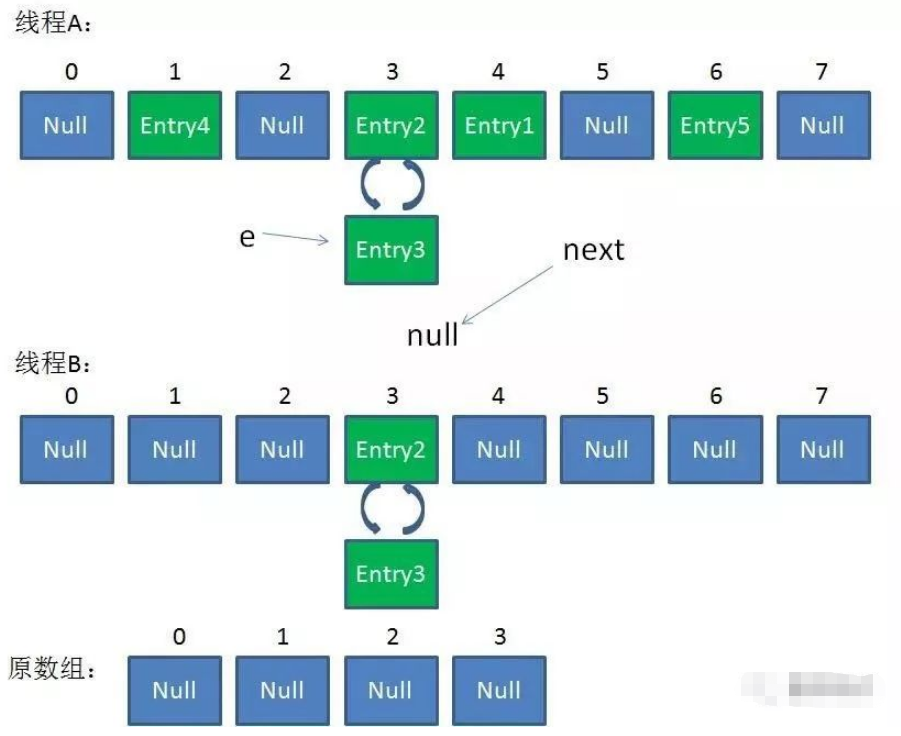
所以 HashMap 只能在单线程中使用,并且尽量的预设容量,尽可能的减少扩容。
在 JDK1.8 中对 HashMap 进行了优化: 当 hash 碰撞之后写入链表的长度超过了阈值(默认为8),链表将会转换为红黑树。
假设 hash 冲突非常严重,一个数组后面接了很长的链表,此时重新的时间复杂度就是 O(n) 。
如果是红黑树,时间复杂度就是 O(logn) 。
大大提高了查询效率。
感谢各位的阅读,以上就是“HashMap遍历方法是什么”的内容了,经过本文的学习后,相信大家对HashMap遍历方法是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/likeyoucool/blog/4389761



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



