Hadoop 由HDFS 、MapReduce、HBASE、hive 和zookeeper 等成员组成,其中最
基础最重要的元素是底层用于存储集群中所有存储节点文件的文件系统HDFS 来
执行MapReduce 程序的MapReduce 引擎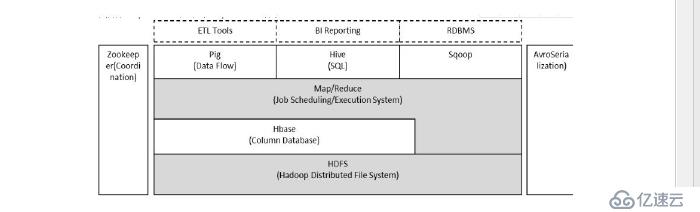
1 pig 是一个基于Hadoop 的大规模数据分析平台,pig 为复杂的海量数据并行计
算提供了一个简单的操作和编程接口
2 hive 是基于Hadoop 的一个工具,提供完整的SQL 查询,可以将sql 语句转换
为MapReduce (映射)任务进行执行
3 zookeeper:高效的,可扩展的协调系统,存储和协调关键共享状态
4 HBASE 是一个开源的,基于列存储模型的分布式数据库
5 hdfs 是一个分布式文件系统,具有高容错的特点,适合于那些超大数据集的应
用程序,
6 MapReduce 是一种编程模式,用于大规模数据集的并行计算

是一个高度容错性的分布式文件系统,可以被广泛的部署于廉价的PC 上,他以流式访问模式访问应用程序的数据,这样可以提高系统的数据吞吐量,因而非常适合用于具有超大数据集的应用程序中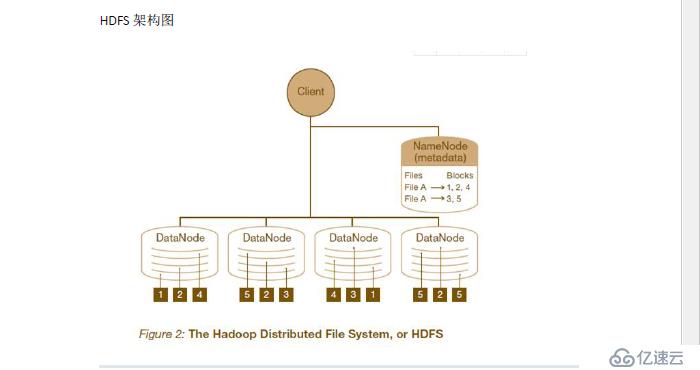
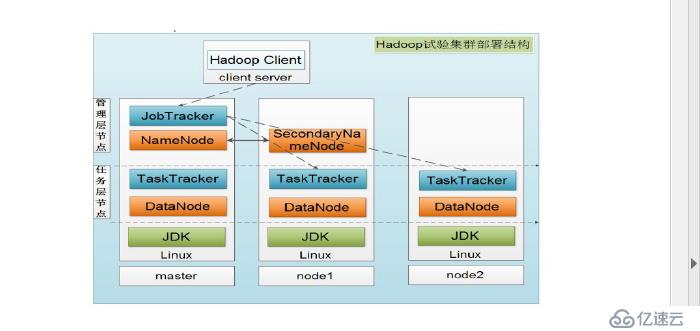
HDFS 架构采用主从架构,一个HDFS 集群应该包含一个namenode 节点和多个datanode 节点,name node 负责整个HDFS 文件系统中的文件元数据的保管和管理,集群中通常只有一台机器上运行namenode,datanode 节点保存文件中的数据,集群中的机器分别运行一个datenode 实例,在HDFS 中,namenode 节点称为名称节点,DataNode 称为数据节点,DataNode 通过心跳机制与namenode 节点进行定时通信Namenode 相当于mfs 中的master serverDatanode 相当于mfs 中的chunk server
2 HDFS 的读写方式
写入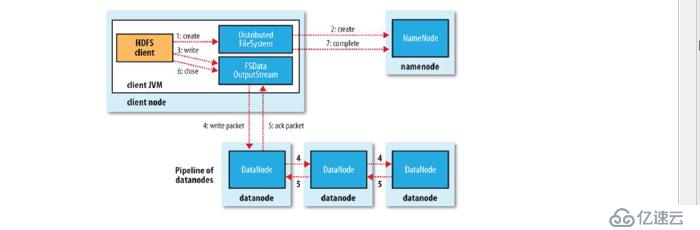
文件写入:如上图
1 客户端向nameode (master server ) 发起文件写入请求
2 namenode 根据文件大小和文件块配置情况,返回给客户端DataNode 信息
(chunkserver)
3 client 将文件划分成多个文件块,根据DataNode 的地址信息,按顺序写入每个
DataNode 中
读取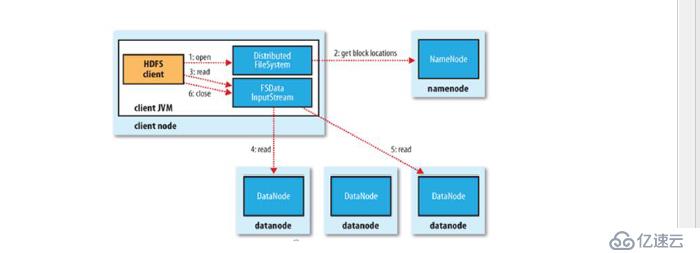
步骤:
1 向namenode 发送读取请求
2 namenode 返回文件位置列表
3 client 根据列表读取文件信息
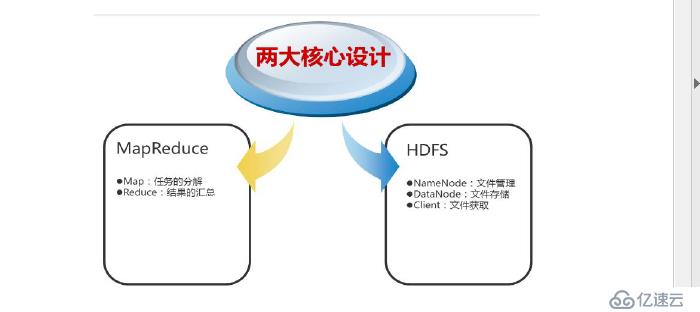
是一种编程模型,用于大规模数据集并行计算,map(映射)和reduce(化简),采用分布方式,(分封制),先把任务分发到集群节点上,并行计算,然后将结果合并,多结点计算,涉及的任务调度,负载均衡,容错,都有MapReduce 完成
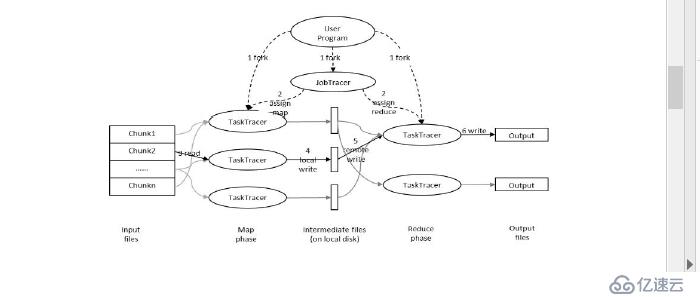
用户提交任务给job tracer ,job tracer 把对应的用户程序中的map 个reduce 操作映射到tasktracee 节点中,输入模块负责把输入数据数据分成小数据块,然后把它们传递给map 节点,map 节点得到每一个key/value 对,然后产生一个或多个key/value 对,然后写入文件,reduce 节点获取临时文件中的数据,对带有相同key 的数据进行迭代计算,后将最终结果写入文件

Hadoop 的核心是MapReduce,而MapReduce 的核心又在于map 和reduce 函数。它们是交给用户实现的,这两个函数定义了任务本身。
map 函数:接受一个键值对(key-value pair)(例如上图中的Splitting 结果),产生一组中间键值对(例如上图中Mapping 后的结果)。Map/Reduce 框架会将map 函数产生的中间键值对里键相同的值传递给一个reduce 函数。
reduce 函数:接受一个键,以及相关的一组值(例如上图中Shuffling 后的结果),将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)(例如上图中Reduce 后的结果)
但是,Map/Reduce 并不是万能的,适用于Map/Reduce 计算有先提条件:
(1)待处理的数据集可以分解成许多小的数据集;
(2)而且每一个小数据集都可以完全并行地进行处理;
若不满足以上两条中的任意一条,则不适合适用Map/Reduce 模式。
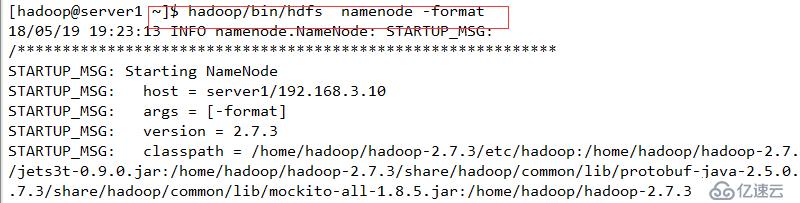
软件下载位置
链接:https://pan.baidu.com/s/1lBQ0jZC6MGj9zfV-dEiguw
密码:13xi









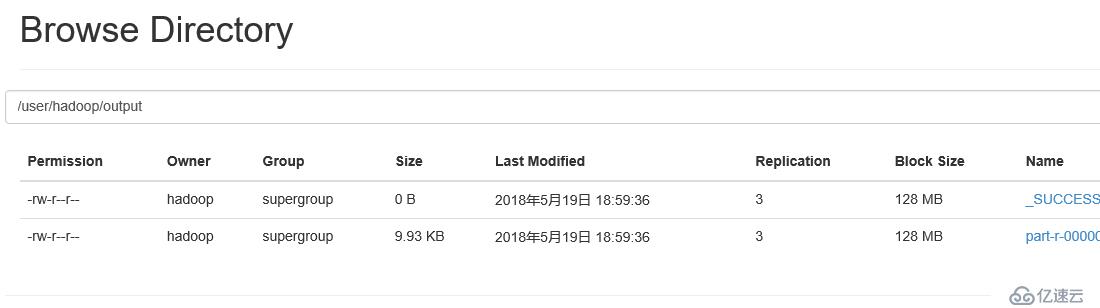
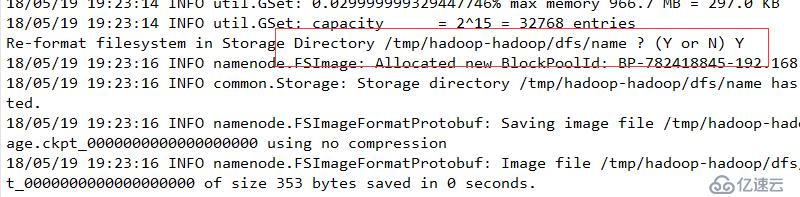
并使用Hadoop内部方法完成基本配置。其中output是自动创建的,无需手工创建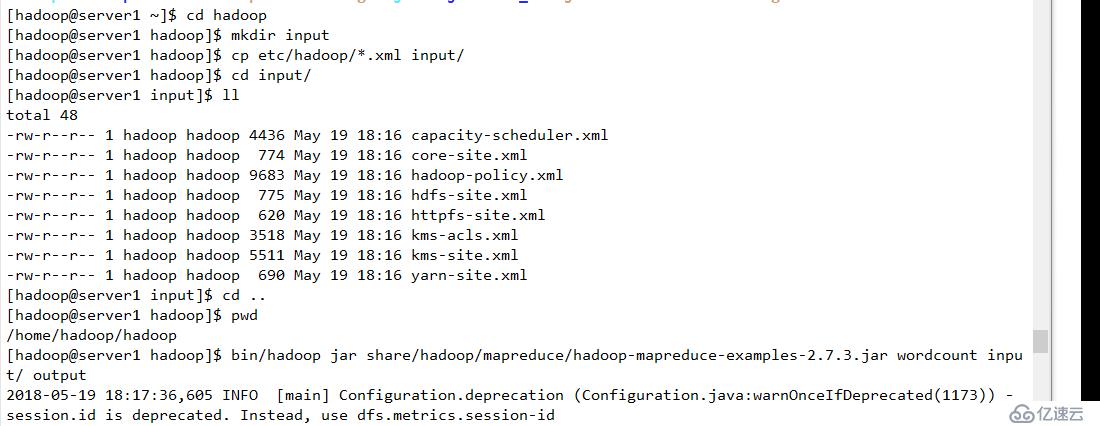

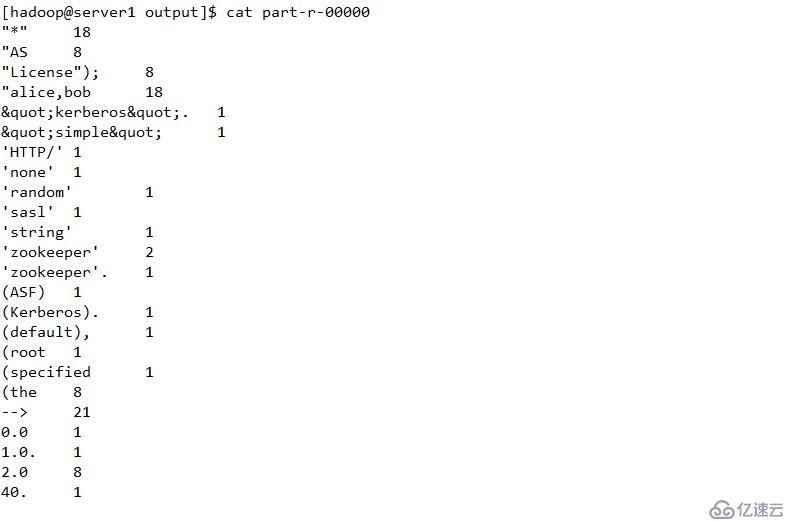





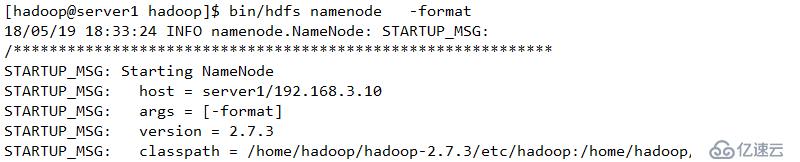
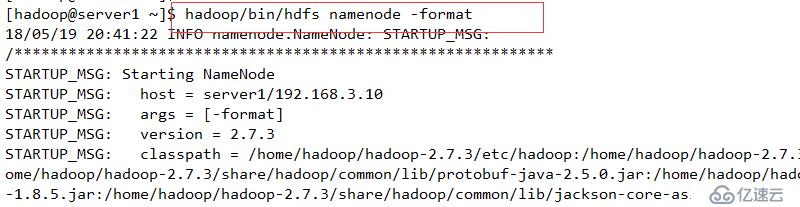
返回值为0,表示格式化成功
测试显示结果
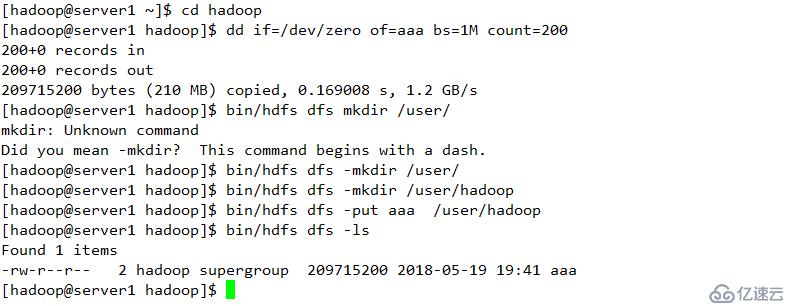
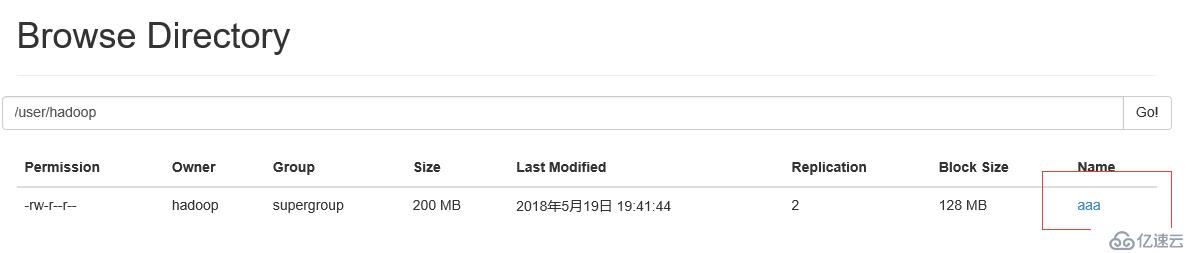
创建目录上传
查看
上传文件至服务端
查看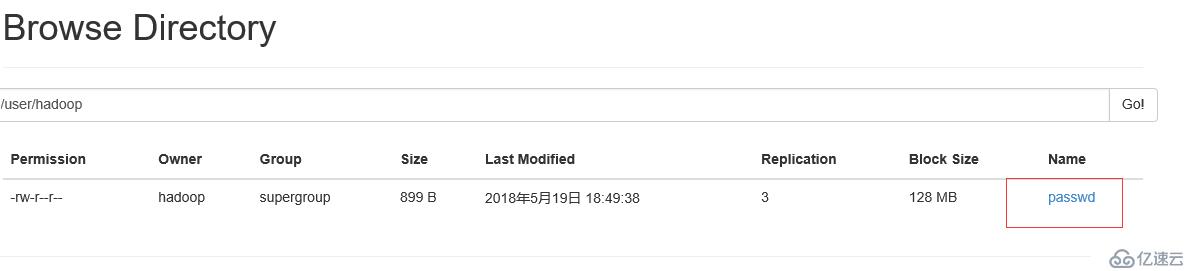
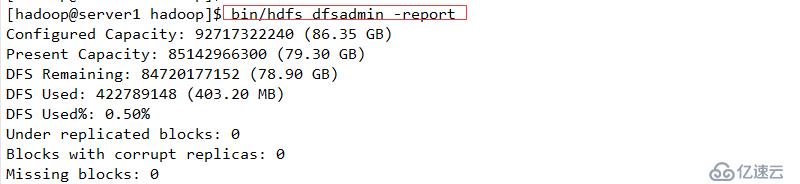
使用命令查看结果
删除并查看其显示结果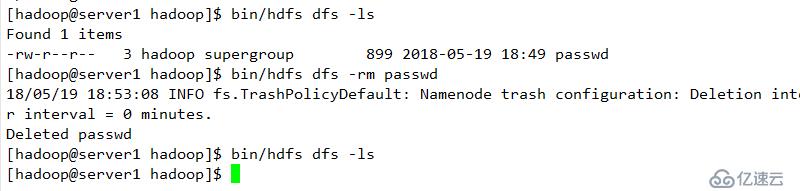
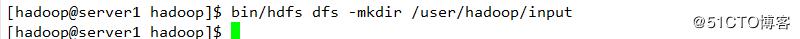

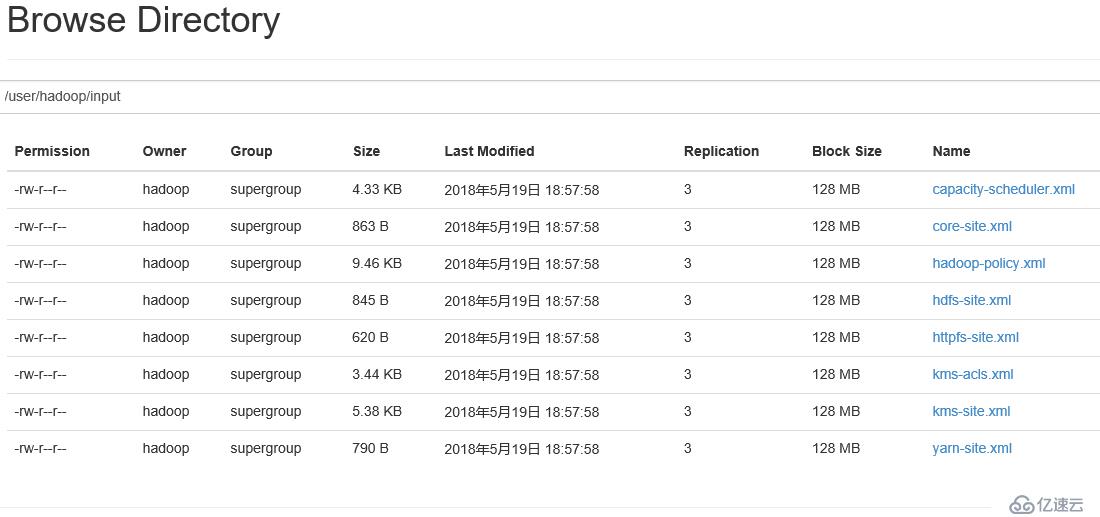



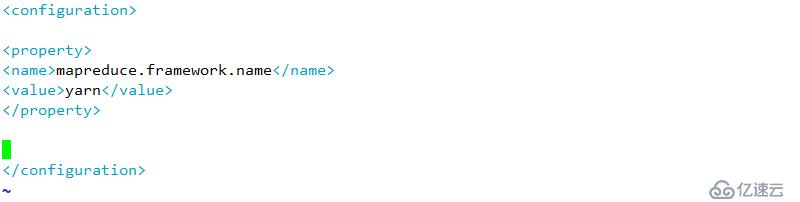
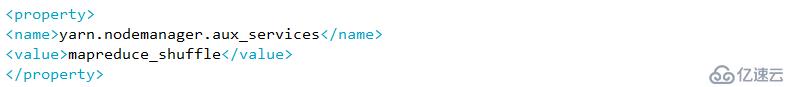

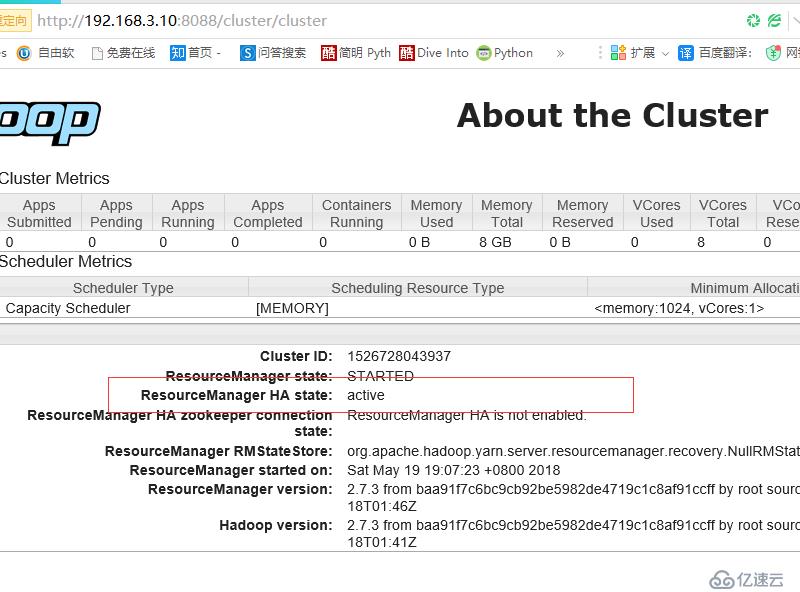





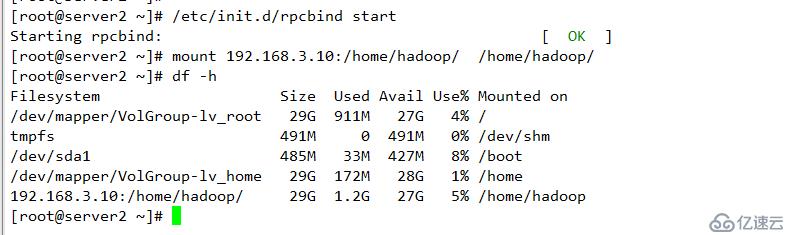
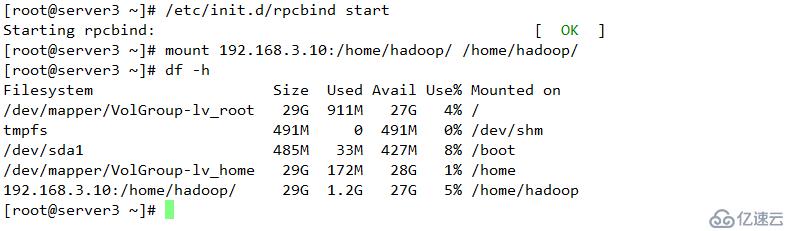



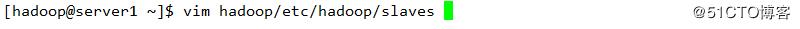

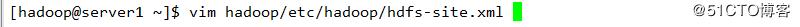


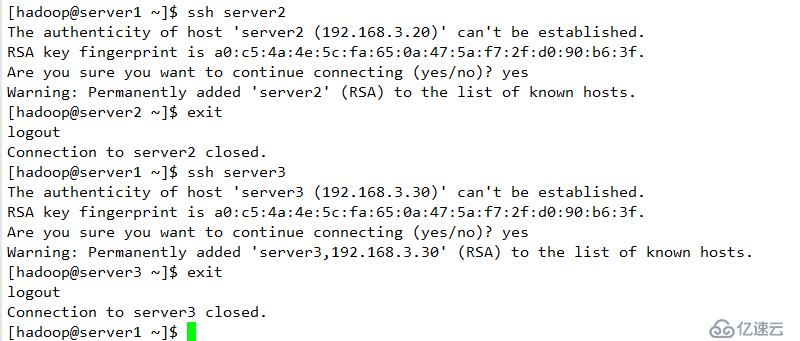
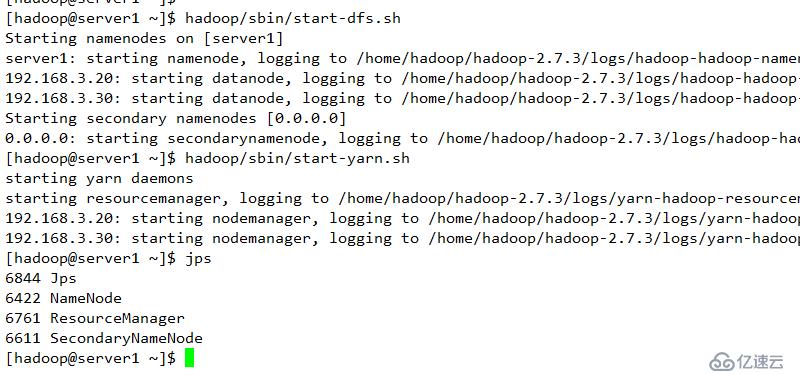


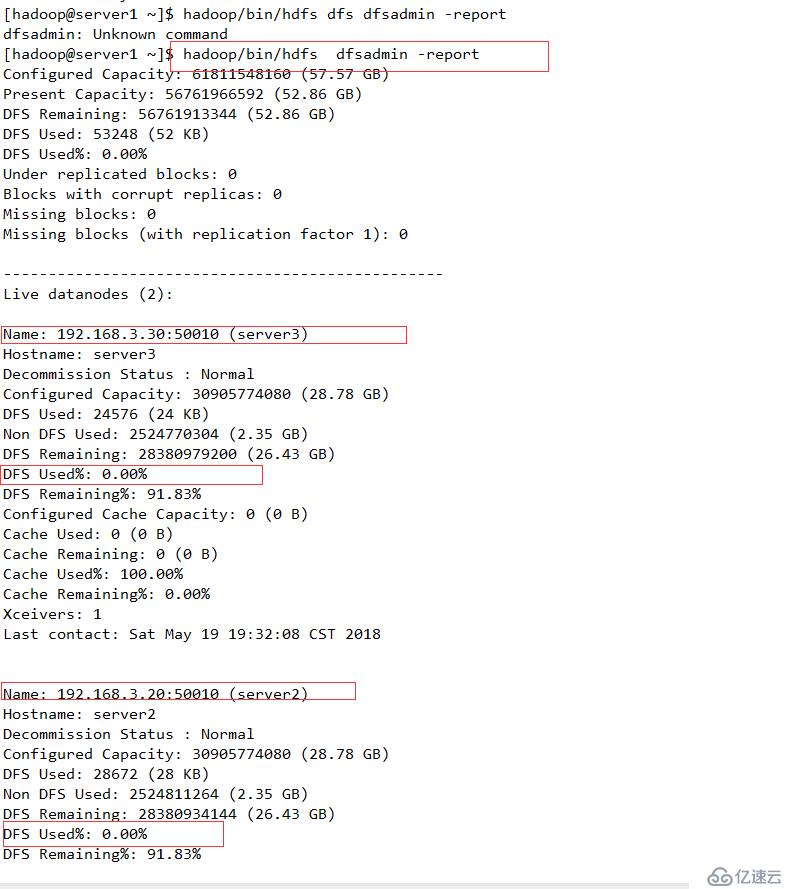


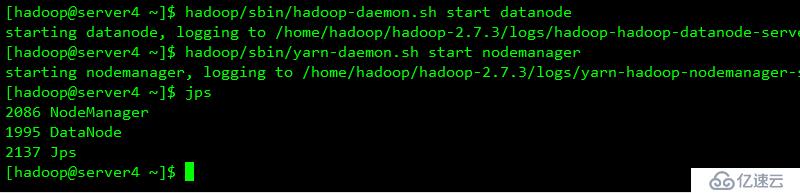
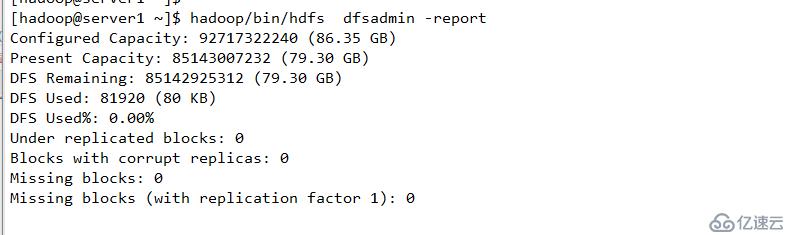
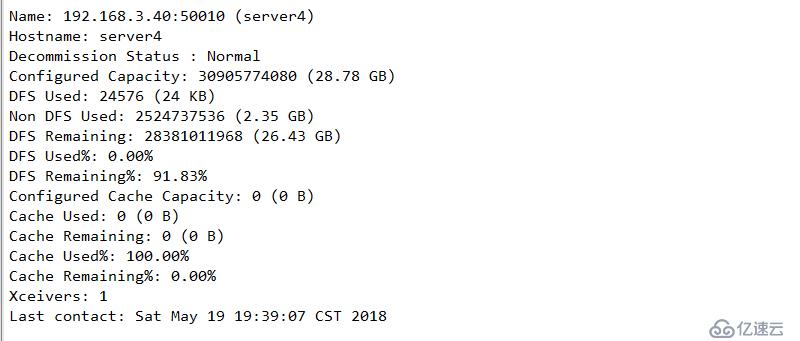
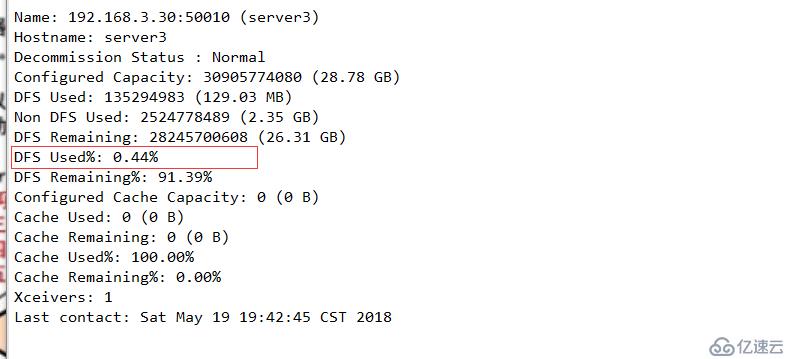
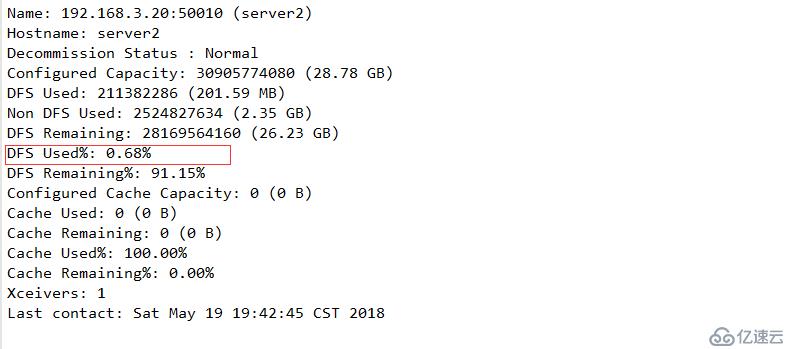
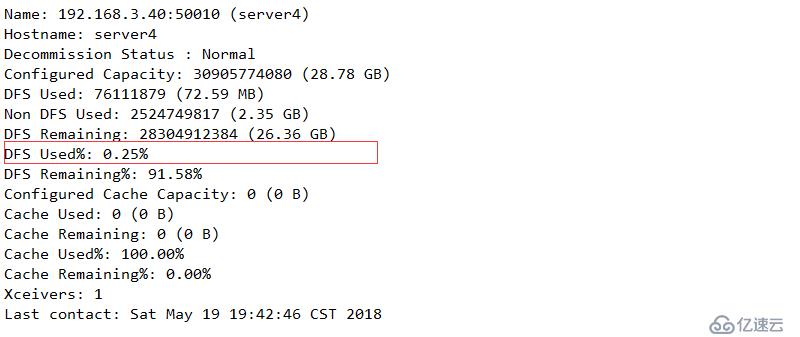

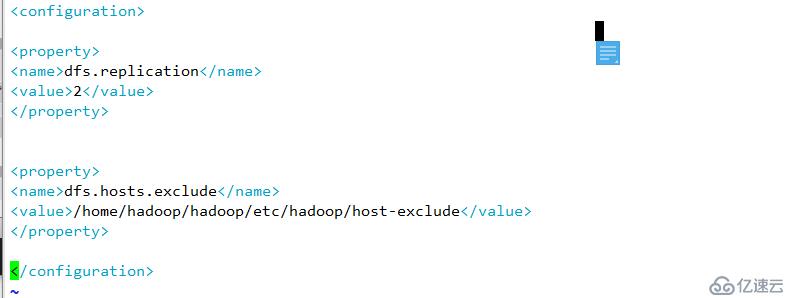
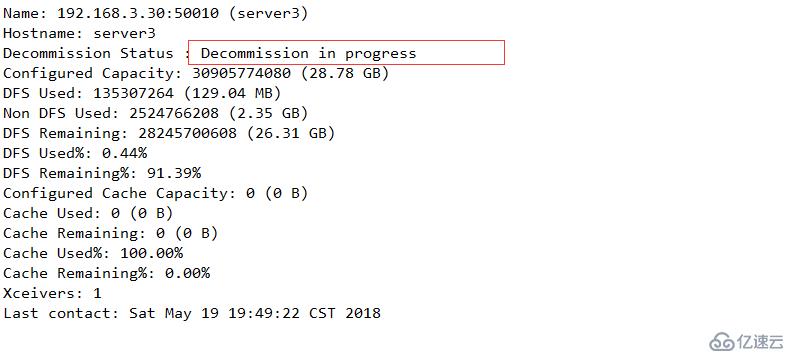
配置下线用户为server3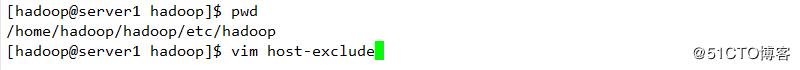








简介:
在典型的HA集群中,通常有两台不同的机器充当NN(namenode),在任何时间,只有一台机器处于active状态,另一台机器则处于standby状态,active NN负责集群中所有客户端的操作,而standby NN主要用于备用,主要维持足够的状态,如果有必要,可以提供快速的故障恢复
为了让standby NN状态和 active NN 保持同步,及元数据保持一致,他会都会和journalnodes 守护进程通信,当active NN 执行任何有关命名空间的修改,他都需要持久化到一半以上的journalnodes 上(通过edits log 持久化存储),而standby NN负责观察edits log 的变化,他能够从JNS 中读取edits 信息,并更新其内部的名称空间,一旦active NN 出现故障,standby NN 会将保证从JNS中读取了全部edits,然后切换成active 状态,standby NN读取全部的edits 可确保发生故障转移之前,是和active NN拥有完全同步的命名空间状态
为了提供快速的故障恢复,standby NN也需要保存集群中各个文件块的存储位置,为了实现这个,集群中的所有Datanode 将配置好的active NN和standby NN的位置,并向他们发送快文件所在的位置及心跳。
为了部署HA 集群,你需要准备以下事项:
(1)、NameNode machines:运行Active NN 和Standby NN 的机器需要相同的硬件配置;
(2)、JournalNode machines:也就是运行JN 的机器。JN 守护进程相对来说比较轻量,所以这些守护进程可以可其他守护线程(比如NN,YARN ResourceManager)运行在同一台机器上。在一个集群中,最少要运行3 个JN 守护进程,这将使得系统有一定的容错能力。当然,你也可以运行3 个以上的JN,但是为了增加系统的容错能力,你应该运行奇数个JN(3、5、7 等),当运行N 个JN,系统将最多容忍(N-1)/2 个JN 崩溃。在HA 集群中,Standby NN 也执行namespace 状态的checkpoints,所以不必要运行Secondary NN、CheckpointNode 和BackupNode;事实上,运行这些守护进程是错误的。
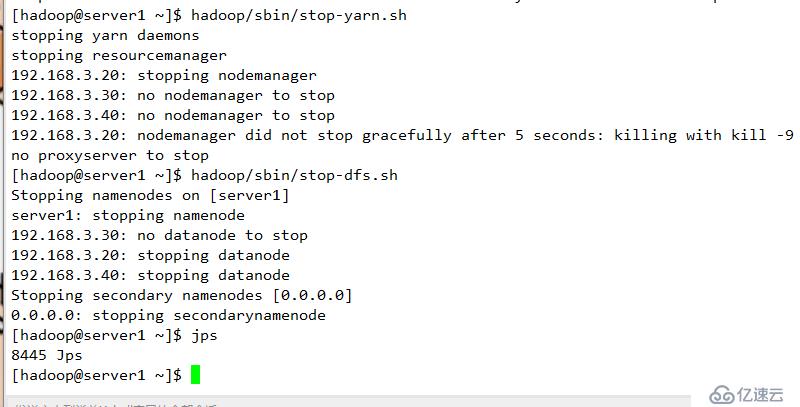



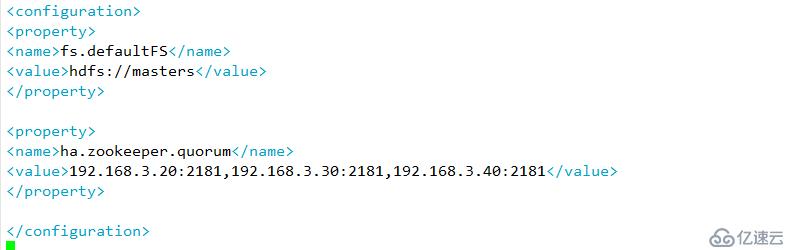





zookeeper 至少为三台,总结点数为奇数个






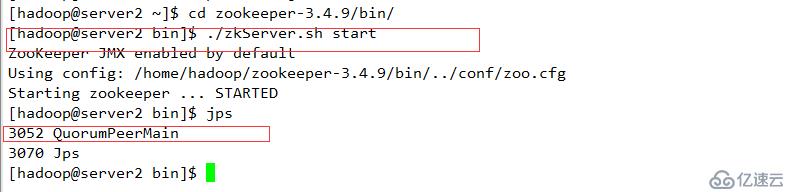
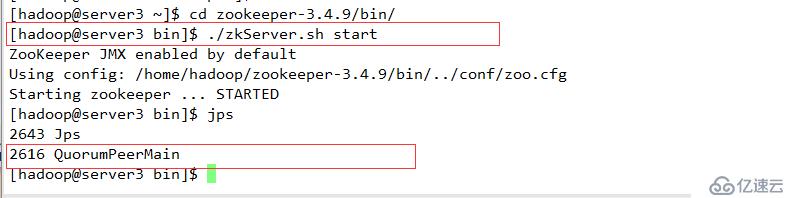





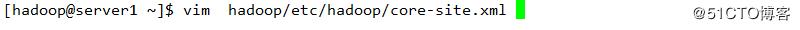
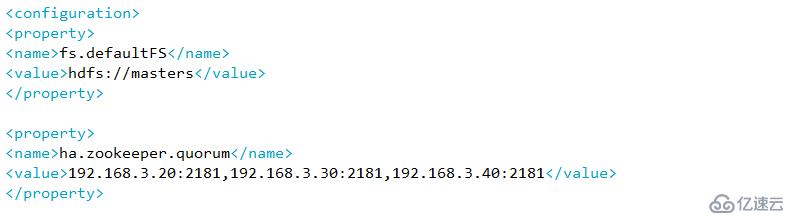

A 指定hdfs的nameservices 为master
B 定义namenode节点(server1 server5 )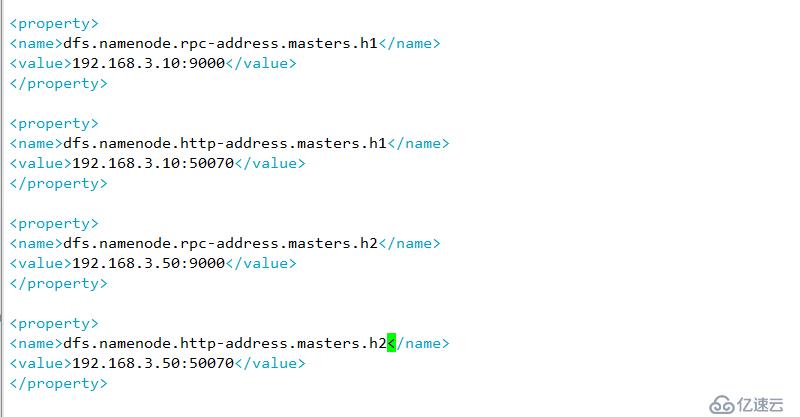
C 指定namenode 元数据在journalNode上的存放位置
D指定journalnode在本地磁盘存放数据的位置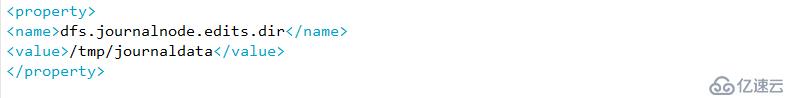
E 开启namenode 失败自动切换,及自动切换实现方式,隔离机制方式以及使用sshfence 隔离机制需要ssh免密以及隔离机制超时时间等参数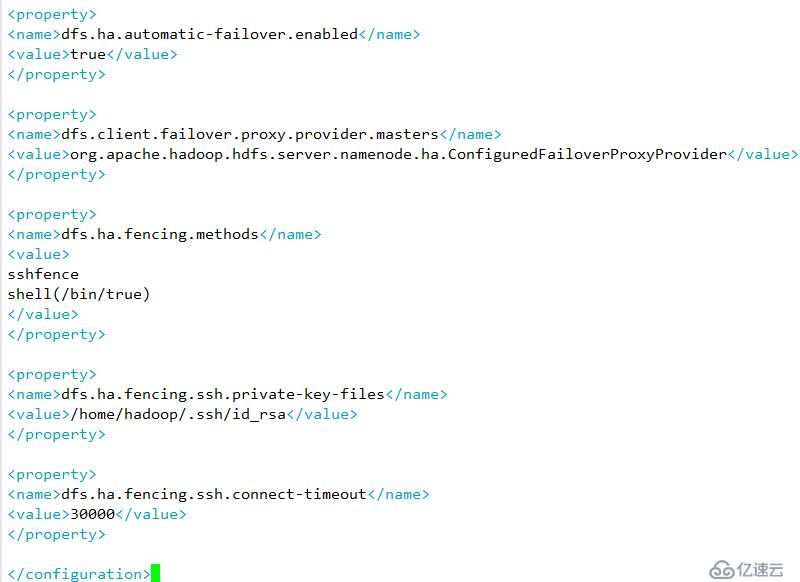










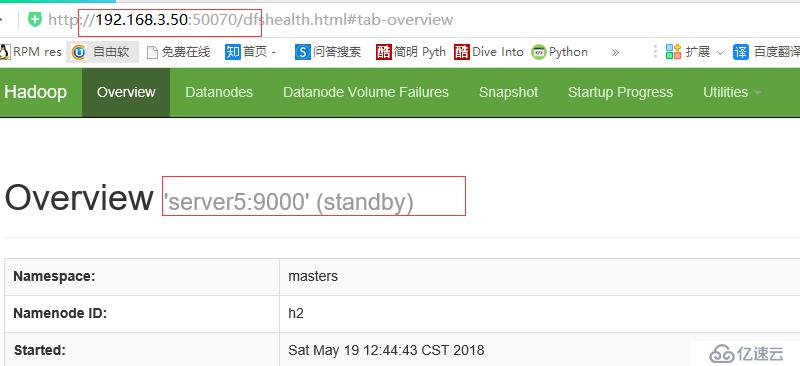
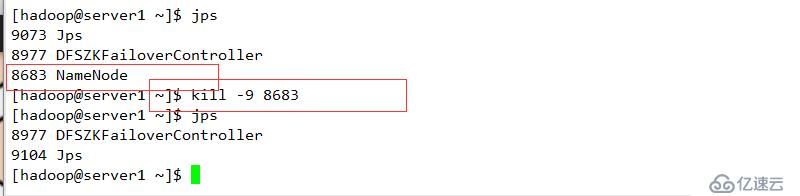

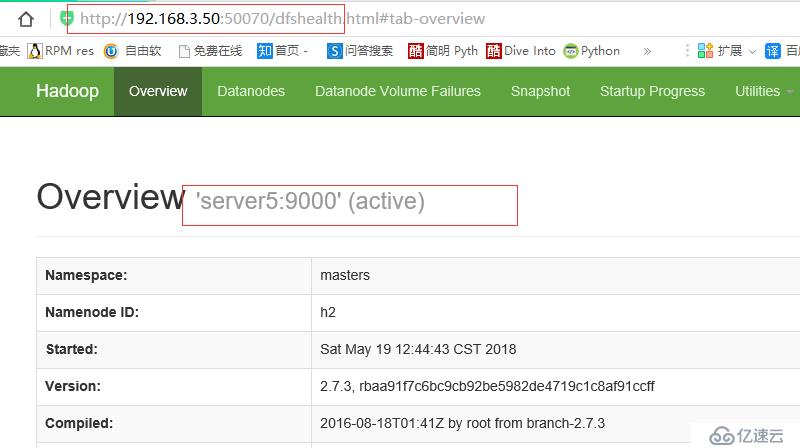

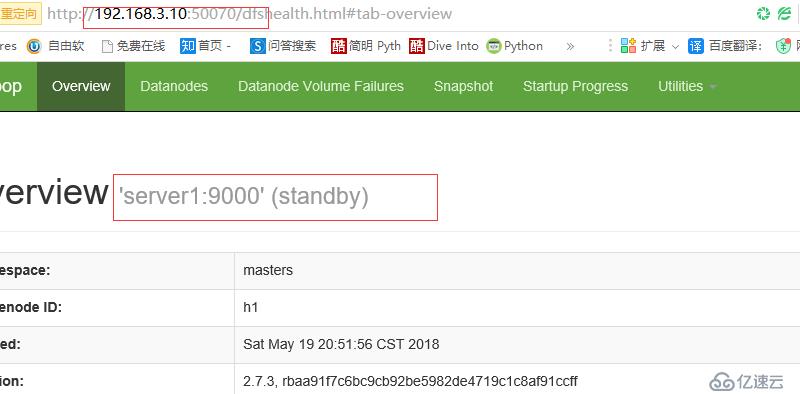






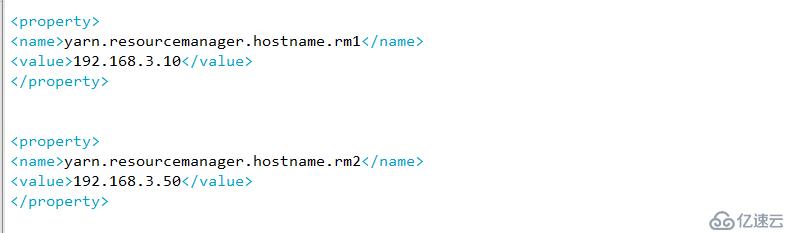




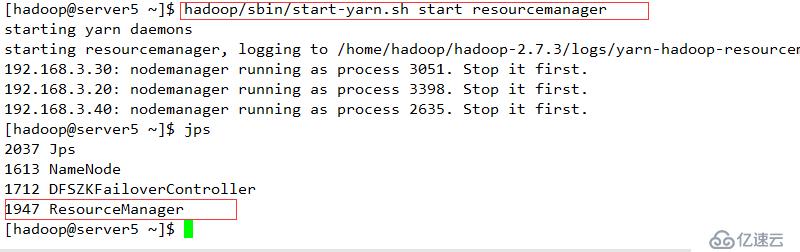
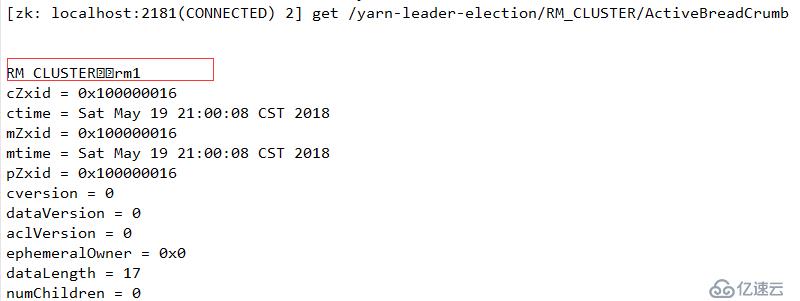
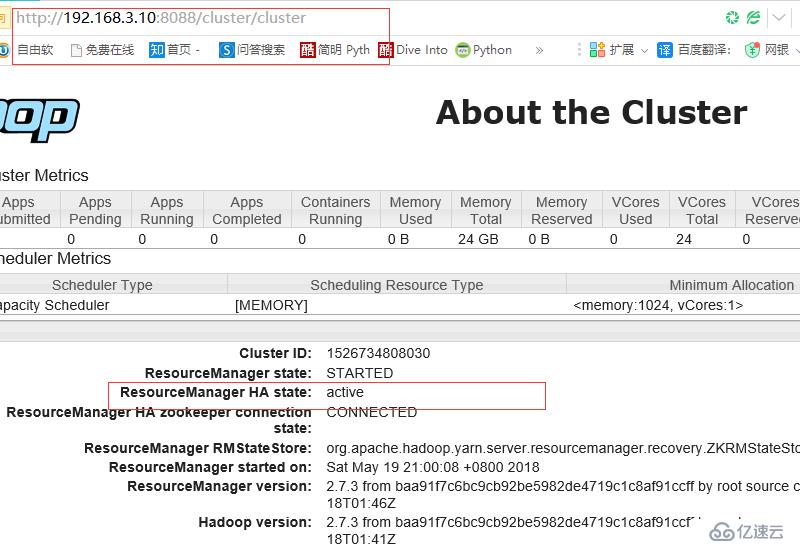
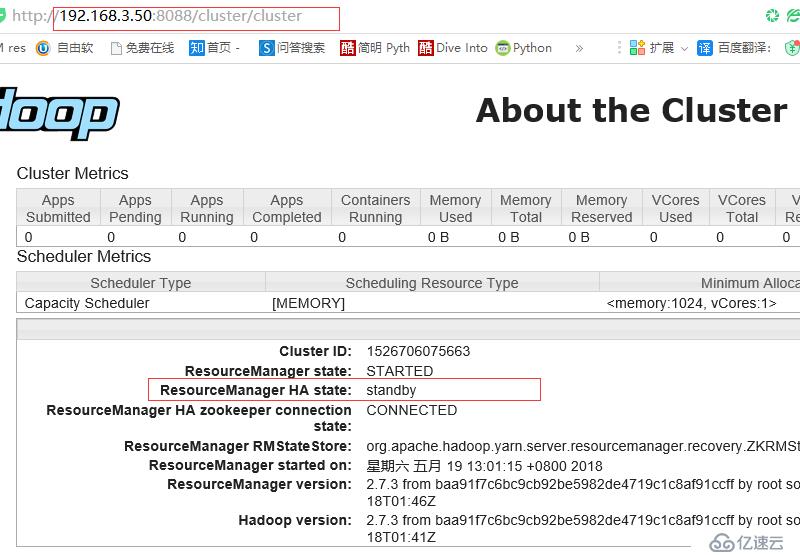
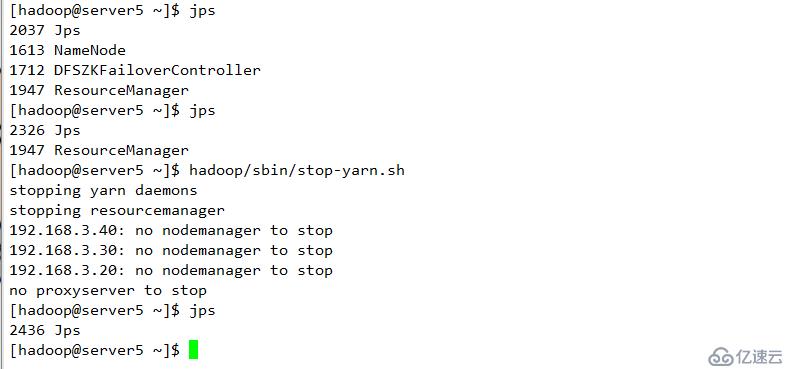
断开主节点查看情况
则切换到server5上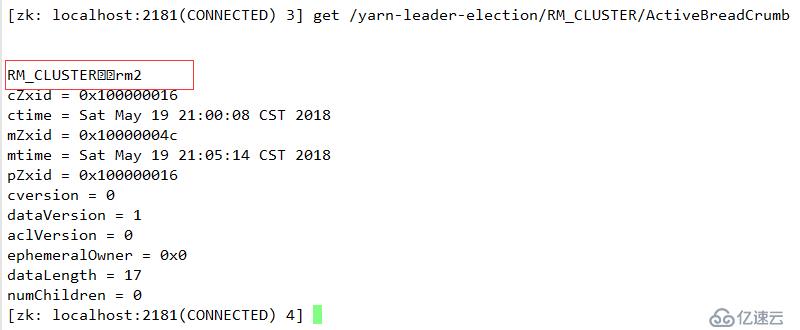
查看server5 状态
启动server1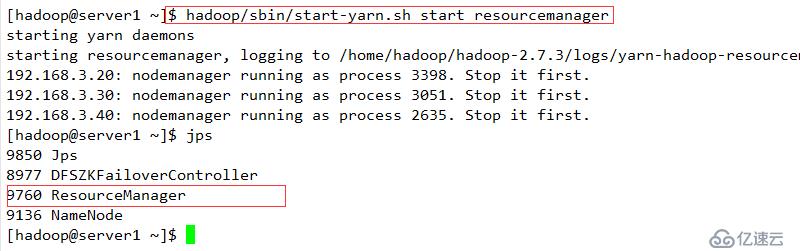
查看server1状态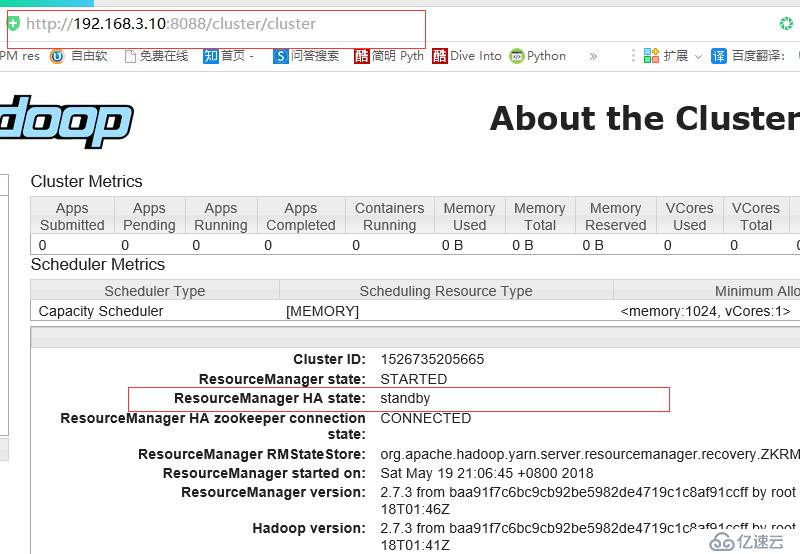
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



