如何进行移动端SOTA模型MixNet的分析,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
Depthwise卷积在设计更轻量高效的网络中经常被使用,但人们通常都忽略了Depthwise卷积中的卷积核大小(通常都是使用3x3)。我们研究了不同大小卷积核对网络性能的影响,并观察到不同大小卷积核相互组合,能得到更高的准确性。基于这个思想,我们得到了一个以不同大小卷积核组合成Depthwise卷积模块,再AutoML的搜索下,提出了一个更高效的网络Mixnet,超越大部分移动端网络如Mobilenetv1, v2, shufflenet等等。
由于Depthwise卷积是分离各个通道,单独做一个卷积操作。因此在设计网络中,为了减少计算量,研究人员通常把注意力放在如何控制通道数,使得网络计算量不会增长过大。然后网络中通常只采用了3x3大小卷积核的卷积,而在其他工作中表明大卷积核在一定程度上能提高模型性能。我们问题转为使用大卷积核是否就一定提高模型准确率?
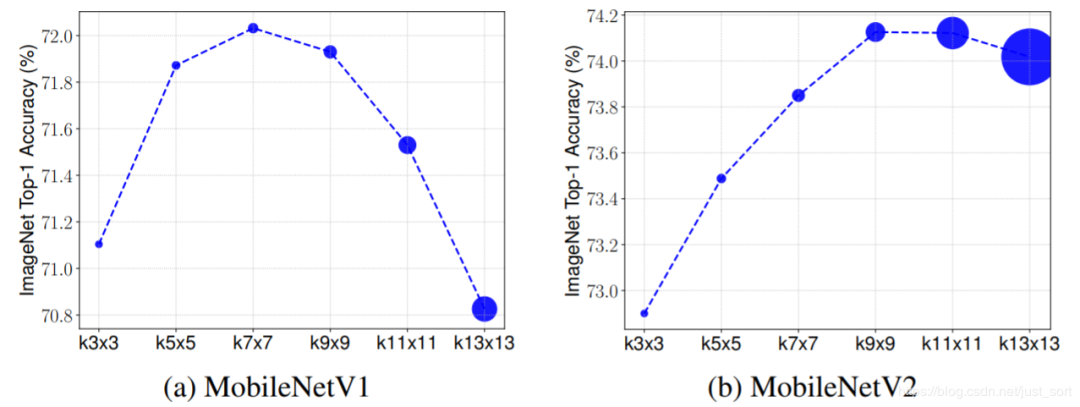
通过对比两种网络结构,我们可以得知不同网络最好的性能对应着不同的卷积核大小
基于观察的结果,我们设置了一个不同大小卷积核构成的MixConv模块
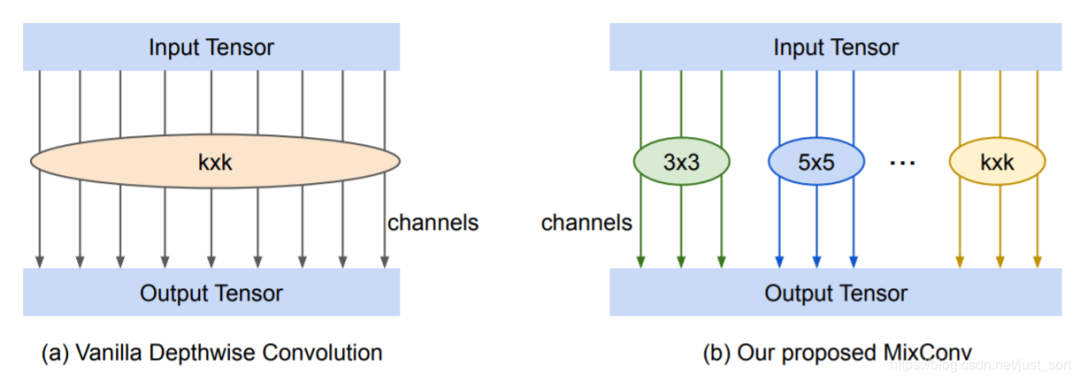
MixConv模块还有很多参数没有实际确定
进行MixConv需要对通道做分组,分配给不同大小的卷积核。实验中,研究人员发现Groups = 4时候,是对MobileNets结构最稳定的。借助于NAS搜索,研究人员分别从1-5的分组数进行结构搜索。
卷积核大小虽然能随意设计,但还是有一定前提的。比如当两个组的卷积核大小相同,其实可以等价于这两个组融合进一个卷积组里(比如2组都是3x3卷积核,输出通道为X,相当于1组由3x3卷积核,输出通道X)
因此我们设定,卷积核起始大小为3,组与组之间卷积核增长为2
比如分4组的话,卷积核为3x3 5x5 7x7 9x9
我们采取了两种策略
空洞卷积往往能得到更大的感受野,相较于同等感受野的大卷积核,它能一定程度上减少参数量,然而根据我们的实验,空洞卷积的性能通常要比大卷积核的差
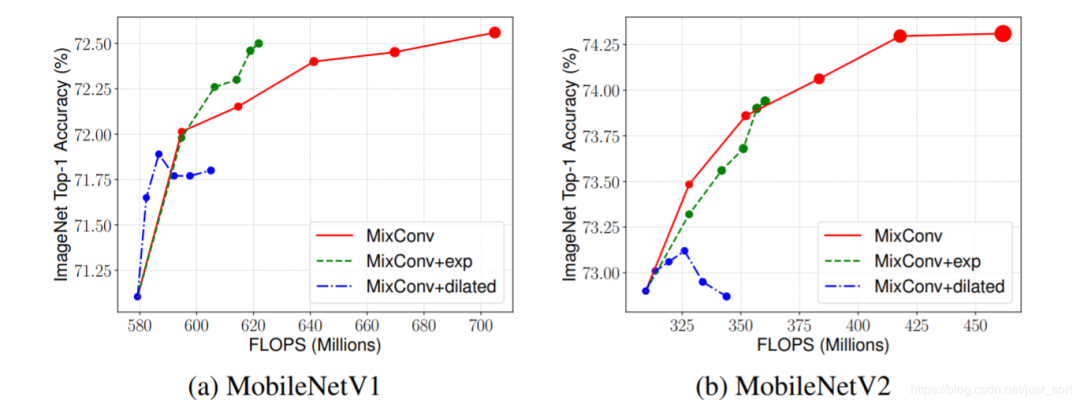
上图是基于Mobilenet结构上,对Mixconv各种策略的进一步验证
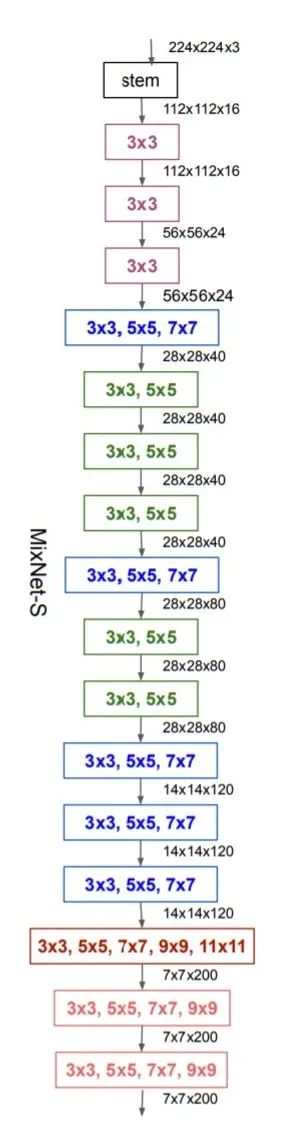
介绍完前面的设计理念后,这篇论文也就差不多了,后续的工作都是AutoML进行搜索得到的,Mixnet有三种大小的模型(MixNet-S, MixNet-M, MixNet-L)
下面两图分别是Mixnet-S和Mixnet-M的结构

这里采用的是https://github.com/romulus0914/MixNet-PyTorch 这版代码,讲解的是研究人员提出的不同kernel_size的DepthwiseConv模块
class MDConv(nn.Module):
"""
实现分离depthwise卷积
"""
def __init__(self, channels, kernel_size, stride):
super(MDConv, self).__init__()
self.num_groups = len(kernel_size)
self.split_channels = _SplitChannels(channels, self.num_groups)
self.mixed_depthwise_conv = nn.ModuleList()
for i in range(self.num_groups):
self.mixed_depthwise_conv.append(nn.Conv2d(
self.split_channels[i], self.split_channels[i],
kernel_size[i], stride=stride, padding=kernel_size[i] // 2,
groups=self.split_channels[i],
bias=False
))
def forward(self, x):
if self.num_groups == 1:
return self.mixed_depthwise_conv[0](x)
x_split = torch.split(x, self.split_channels, dim=1)
x = [conv(t) for conv, t in zip(self.mixed_depthwise_conv, x_split)]
x = torch.cat(x, dim=1)
return x
首先通过splitchannels这个方法,得到每个kernel size对应的通道数。
再用一个for循环,把每个不同kernel size的卷积模块,添加到ModuleList容器中
在前向传播里面,先是调用torch.split方法对输入在通道维度上做分离,通过一个列表,保存所有卷积得到的张量。最后调用torch.cat在通道维上进行连结。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





