本篇文章给大家分享的是有关Milvus在流式数据场景下的性能表现是什么,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
Milvus 作为一款开源的特征向量相似度搜索引擎,其开源半年以来,在全球已经有数百家企业或组织用户。这些用户涉及各个领域,包括金融、互联网、电商、生物制药等。在部分用户的生产场景中,其数据大多是持续地、动态地生成,且要求这些动态生成的数据入库后能很快被检索到。
大数据处理可分为批式大数据(又称为“历史大数据”)处理和流式大数据(又称为“实时大数据”)处理两类。在大多数情况下,流数据在处理持续生成的动态新数据方面具有显著优势。流数据是指由多个数据源持续生成的数据,通常同时以较小规模的数据记录的形式发送,约几千字节。流数据可为各种形式的数据,例如网购数据、社交网站信息、地理空间服务,以及通过遥感器测控得到的数据。
在用户需求的驱动下, Milvus 不断增加其功能,探索更多的应用场景。Milvus 动态数据管理策略,使得用户可以随时对数据进行插入、删除、搜索、更新等操作,无需受到静态数据带来的困扰。在插入或更新数据之后,几乎可以立刻对插入或更新过的数据进行检索, Milvus 能够保证搜索结果的准确率和数据一致性。同时在源源不断的数据导入过程中, Milvus 依然能够保持优秀的检索性能。由于这些特性, Milvus 可以很好地适用于流式大数据的场景。
在很多用户场景中,结合了批式大数据和流式大数据两种处理方式,从而构建一种混合模式,来同时维持实时处理和批处理。比如在推荐系统的实现中,无论是文章、音乐、视频等推荐或者是电商平台的商品推荐,都存在许多历史数据。平台给用户做推荐时,部分历史数据依旧有被推荐的价值,因此这些历史数据需要经过去重、过滤等处理然后存入 Milvus 中。除了历史保留的数据,在推荐系统中每天还会产生新的数据,包括新的文章、热点以及新的商品等,这些数据也要及时的导入库中并且要求能够很快被检索到,这些持续产生的数据就是流式数据。
随着越来越多的用户有动态插入数据、实时检索的需求,本文将介绍一下基于 Kafka 实现的 Milvus 在流式数据场景下的参数配置和检索的性能。
Kafka 是一个开源的流处理平台,这里将介绍基于 Kafka 实现的 Milvus 在流式数据下的两个应用示例。
示例一
该系统中使用 Kafka 接收各个客户端产生的数据来模拟生成的流式数据。当 Kafka 消息队列中有数据时,数据接收端持续从 Kafka 队列中读取数据并立即插入 Milvus 中。 Milvus 中插入向量的数据量是可大可小的,用户可一次插入十条向量,也可一次插入数十万条向量。该示例适用于数据实时性要求较高的场景。全过程如图所示:
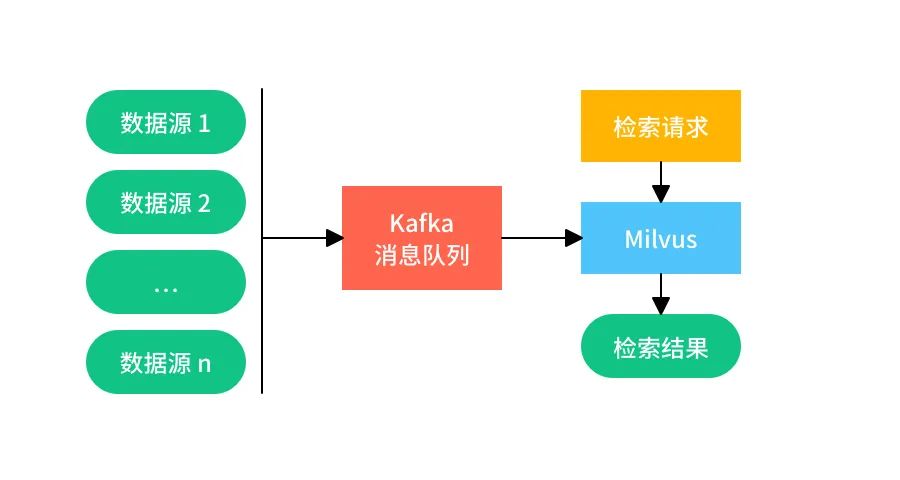
配置:
index_file_size : 在 Milvus 中,数据是分文件存储的,每个数据文件大小在建立集合的时候由参数 index_file_size 值来定义。数据写入磁盘后,成为原始数据文件,保存的是向量的原始数据,每当原始数据文件大小达到 index_file_size 值后,便会触发建立索引,索引建立完成后会生成一个索引数据文件。
Milvus 进行检索时,将在索引文件中去检索。对于未建立索引的数据,将会在原始数据文件中检索。由于未建立索引的部分,检索会比较慢,因此 index_file_size 不宜设置得过大,本示例中该值设置为 512。(若 index_file_size 过大,会使得未建立索引的数据文件较大,降低检索性能。)
nlist : 该值表示 Milvus 建立索引后,每个数据文件里的向量被分为多少个“簇”。本示例中将该值设置为 1024。
Milvus 在不断插入数据的过程中,会不停的建立索引。为了保证检索的效率,这里选择了用 GPU 资源建立索引,用 CPU 资源进行检索。
性能:
本示例中,在持续导入数据之前,向集合中插入了一亿条 128 维的向量,并建立 IVF_SQ8 索引,来模拟历史数据。此后持续的向该集合中随机的间隔 1-8 秒插入 250-350 条向量。随后进行多次检索,检索性能如下:
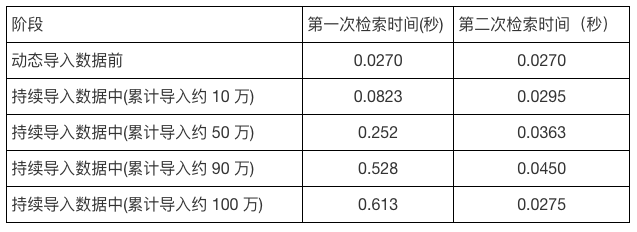
在上述性能记录中,第一次检索时间指的是每次有新增数据导入后的检索时间,第二次检索时间是在第一次检索后没有新的数据导入前的检索时间。
横向比较,发现第一次检索时间大于第二次,是因为第一次检索时会将新导入的数据从磁盘加载到内存。
纵向比较来看,在数据持续导入过程中,第一次检索耗时持续增长。这是因为在持续导入数据的过程中,新增数据文件会和之前未建立索引的数据文件合并,检索时会将新合并的数据文件从磁盘加载到内存。随着导入数据的增多,合并好的这个新文件会越来越大,从磁盘加载到内存的耗时也将增加。其次,导入的这部分数据都未建立索引,随着未建立索引的数据增多,在这部分数据中检索的时间也会逐步增加。第二次检索耗时也越来越长,但其耗时增长幅度相较于第一次较小。是因为第二次检索没有将数据从磁盘加载到内存的过程,耗时增长只是因为未建立索引的数据越来越多。数据在导入到约 100 万条的时候(每个数据文件是 512 MB , 向量 128 维,所以每个数据文件约 100 万条向量),触发了建索引的阈值。当索引建立完成,检索时均是在索引文件中进行检索的,所以这个时候的第二次检索时间又回到动态导入数据前的性能。
在本示例持续导入数据的过程中(累计导入约 100 万),每隔 5 秒采样查询一次,并记录其查询时间。整个过程查询性能趋势如下图所示,纵坐标表示查询耗时,横坐标表示整个查询过程的时刻,以秒为单位。
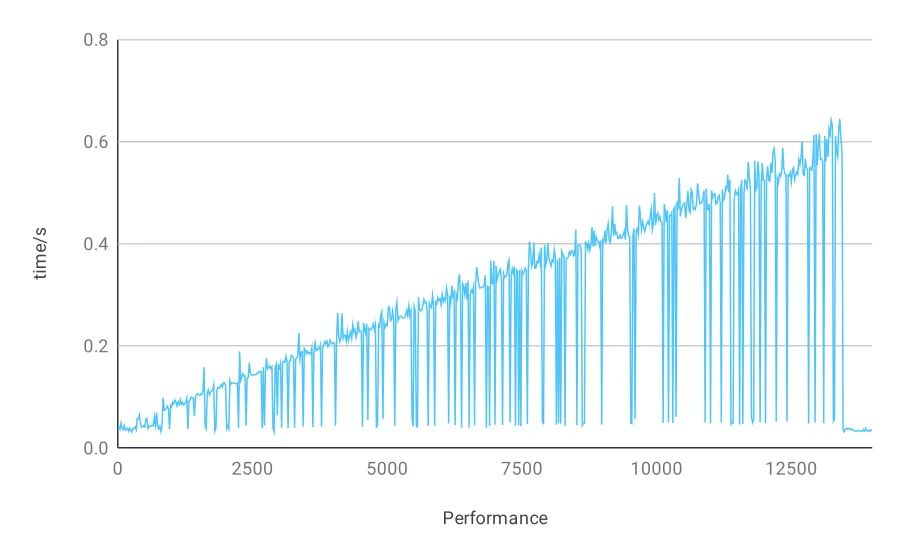
在这个折线图中,大部分点(图中处于上方的这些点)对应上述表格中的第一次检索时间。从图可以看出,导入数据后的第一次检索时间有较大幅度上升的趋势。少数点(图中处于下方的这些点)对应上述表格中的第二次检索时间,第二次检索时间有一个稍微上升的趋势。在该示例中,因为数据频繁导入,所以检索时更多的是在有新数据导入后去检索的情况。从上述图中还可以看到,当导入数据总量达到建索引的阈值时,建立完索引之后的查询时间又恢复到动态导入数据之前的水平。
同时经测试,新插入的数据,在一两秒后即能被检索到。
示例二
该系统中使用 Kafka 接收各个客户端产生的数据来模拟生成的流式数据,当 Kafka 队列中有数据到达时,读取 Kafka 中的数据,当数据积累到一定量(本示例中为 10 万)的时候,批量插入 Milvus 中,这样能够减少插入次数,提高整体检索性能。该示例适用于对数据实时性要求不那么高的场景。该过程流程如图:
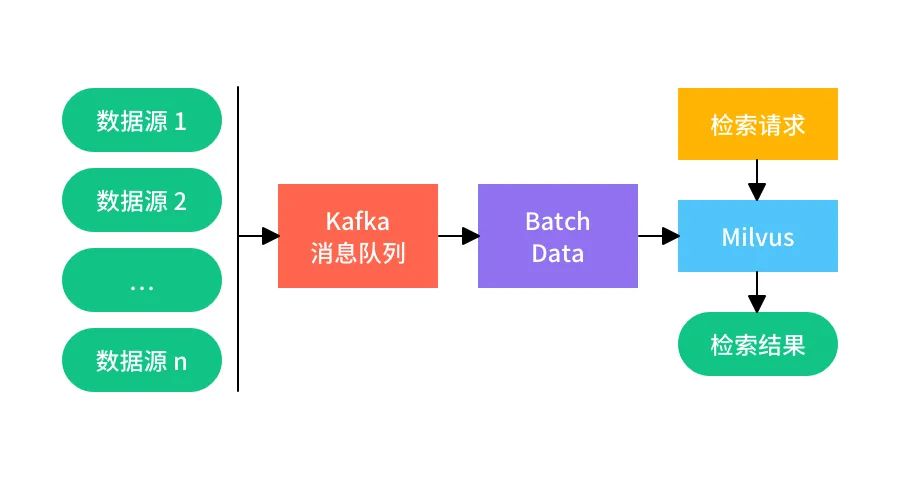
配置:该示例的配置同示例一。
性能:在导入新的数据之前,查询耗时约 0.027 秒。在后续导入过程中,每次批量插入 10 万条数据。数据导入过程中,数据导入后的第一次检索时间以及第二次检索时间和示例一的表中显示时间差不多。由于没有频繁的数据导入操作,所以在检索时,大多数时候的检索时间都对应上述表中的第二次检索时间。
在本示例持续批量导入数据的过程中(累计导入约 100 万),每隔 5 秒采样查询一次,并记录其查询时间。整个过程查询性能趋势如下图所示,纵坐标表示查询耗时,横坐标表示整个查询过程的时刻,以秒为单位。
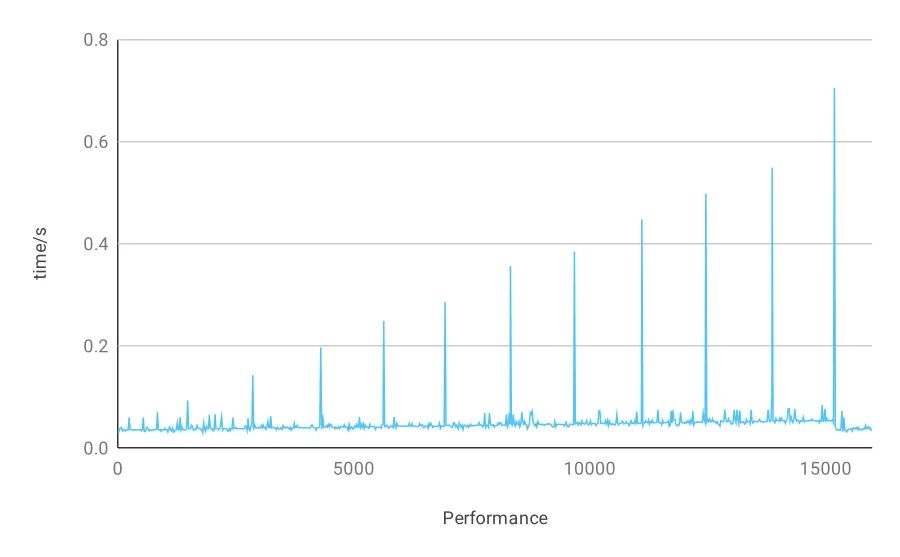
在该该折线图中可以看到,由于插入频率降低,所以大多数检索时对应示例一表格中的第二次检索时间。只有在每次导入十万数据后,检索耗时相对较长。同样的,在建完索引之后,查询时间也恢复到导入数据之前的水平。
从上述两个示例的性能表现折线图来看,在有频繁的检索操作,同时对新增数据的实时性要求不高的情况,累计批量数据插入是更优的选择。
以上就是Milvus在流式数据场景下的性能表现是什么,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4209276/blog/4349823



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



