Java内存模型可见性的分析,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
给定程序以及一个检测程序是否合法的执行跟踪,JMM工作原理是检查执行跟踪中的每个读,并根据某些规则检查读观察到的写是否有效
JMM中可能产生的行为表现为不论代码是如何实现程序行为,只要保证程序的所有结果执行和JMM预期的结果一致即可
基于上述的第二点,对实现者执行的代码进行转换的实现就比较自由,可以实现操作的重排序甚至删除不必要的同步操作代码
线程共享与独占区域
线程共享区域: JVM运行数据区中的方法区,堆内存存储的数据变量,存在数据竞争,即数据读写的安全问题
线程独占区域: JVM为每个线程单独创建的私有区域,用于存储当前线程私有的数据变量,不存在数据竞争,比如线程局部变量,ThreadLocal/ThreadLocalRandom等
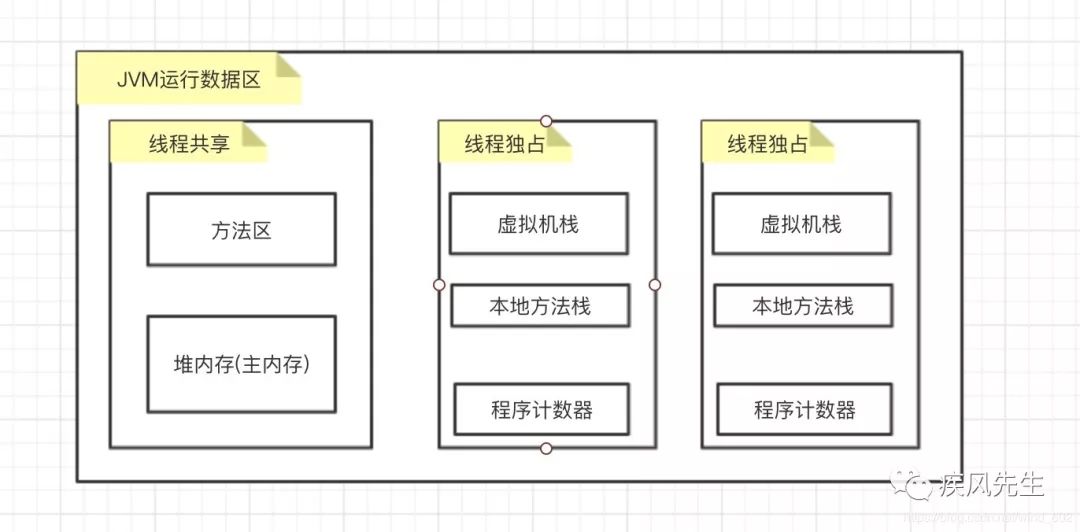
线程通信产生数据竞争
简要的源代码
// constant.java
final int P = 10;
final int C = 20;
// shared.java
int pwrite = 0;
int cwrite = 0;
// producer.java
int pread = 0;
public void run(){
pread = cwrite; // 生产者线程需要消费者线程cwrite的数据
pwrite = P;
}
// consumer.java
int cread = 0;
public void run(){
cread = pwrite;// 消费者线程需要生产者线程的pwrite数据
cwrite = C;
}
//按正常结果输出的预期值推断,不会产生同时pread == C(20)和cread == P(10)结果反推分析(基于我们看到的代码顺序)
如果上述的执行结果成立,那么cwrite = C一定是在pread = cwrite之前执行的;
由于cwrite = C是在cread = pwrite之后执行,所以cread = pwrite一定是在pread = cwrite之前执行的;
也就是cread = pwrite一定是在pwrite = P之前执行的,所以结果是不成立
产生问题
线程既然存在写操作,那么写操作的数据变量一定会让另一个线程读取到对应写后的数据么?
由于线程本身也有自己的工作内存,因此读取数据变量不一定就是另一个线程写操作之后的数据,此时可能读取到工作内存上的缓存数据(脏数据)
同时基于JMM规范,产生优化后可能执行的代码
public void run(){
pread = cwrite; // 生产者线程需要消费者线程cwrite的数据 --1
pwrite = P; // --2
}
// consumer.java
int cread = 0;
public void run(){
cwrite = C; // --3
cread = pwrite;// 消费者线程需要生产者线程的pwrite数据 -4
}在上述两个线程中分析
线程在并发下,可能产生执行的顺序为3-1-2-4,也就是同时产生pread == C(20)和cread == P(10)
数据竞争
当前线程对一个变量执行写操作
同时另一个线程对相同的变量执行读操作
读写操作没有通过同步实现排序
产生问题
不同线程之间通信会对共享变量的数据产生竞争,在这种情况下,JMM作出重排序的优化会导致输出结果与预期的结果不一致,如果放在实际的业务场景中,将会导致很多无法控制的业务逻辑错误,后果不可想象.
JMM下的并发问题
其一,读取到的共享数据不一定是写操作之后的数据,也就是写操作对读操作不可见(缓存导致)
其二,JMM为了提升性能对代码进行重排序,那么就会导致数据产生的结果和预期的不一致(重排序导致)
线程之工作内存
JMM抽象之工作内存(线程本地内存)
线程栈中的存储的变量,如局部变量,方法参数,异常处理参数等
CPU高速缓存
线程,工作内存,JMM与主内存
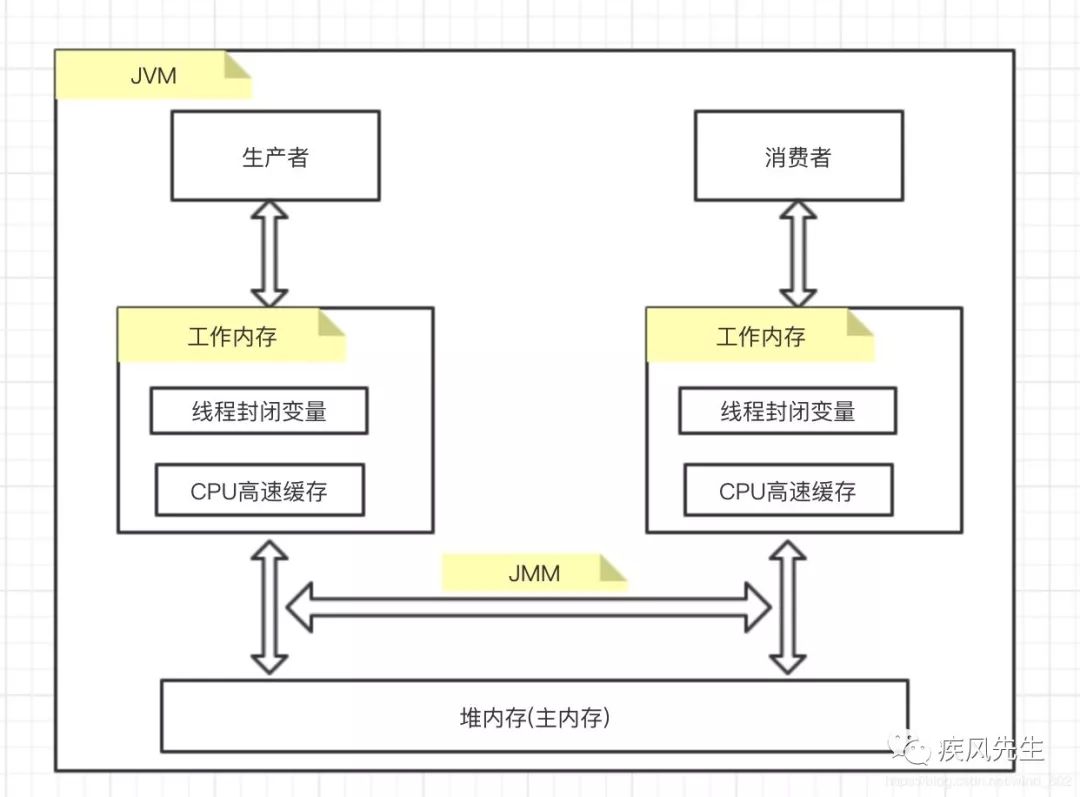 从上述可知,在JVM运行数据区中,工作内存与主内存是通过JMM模型规范来完成彼此之间的数据交互,因此可以通过JMM定义的内存语义规范来提供数据变量的可见性
从上述可知,在JVM运行数据区中,工作内存与主内存是通过JMM模型规范来完成彼此之间的数据交互,因此可以通过JMM定义的内存语义规范来提供数据变量的可见性
基于缓存问题解决方案
JMM规范规定使用针对的技术手段时,将强制线程直接绕过工作内存读取主内存的共享数据
常用技术手段:volatile/synchronized/final/具有内存同步的操作指令
重排序
遵循规则
as-if-serial: 即不管怎么进行重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变.编译器/runtime/处理器都必须遵循as-if-serial语义,也就是说编译器和处理器不会对存在数据依赖关系的操作做重排序
重排序的分类
编译器重排序: 基于单个线程程序的语义前提下,Java开启server模式(clinet不支持)可以对程序代码进行编译优化
处理器重排序:在没有存在数据依赖的前提下,处理器可以改变机器指令的执行顺序
重排序解决方案
编译器会根据JMM特定类型(同步代码标志等)禁止进行重排序
在Java编译器生成指令之前插入特定的内存屏障来禁止处理器重排序
内存屏障类型: 参见CPU高速缓存与内存屏障
关于Java内存模型可见性的分析问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





