这篇文章主要讲解了“数据库的分布式事务流程是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“数据库的分布式事务流程是什么”吧!
众所周知,数据库能实现本地事务,也就是说在同一个数据库中,可以保证事务的原子性,就是全部成功或者失败,上篇文章也写过简单的多数据源事务的解决方案(类似2PC)
但现在的系统往往采用微服务架构,业务系统拥有独立的数据库,因此就出现了跨多个数据库的事务需求,这种事务即为“分布式事务”。
针对这样的问题一般常用的方案有:
2PC/3PC (两阶段提交协议/三阶段提交协议)
TCC (补偿型)
基于可靠消息服务的分布式事务(异步确保型)
基于可靠消息服务的分布式事务,我自己实现了一个基于rabbitmq的分布式事务中间件,shine-mq
一开始本来是想用来封装mq的操作方便使用,后续迭代增加了分布式事务的功能。下面就来介绍下这个中间件:
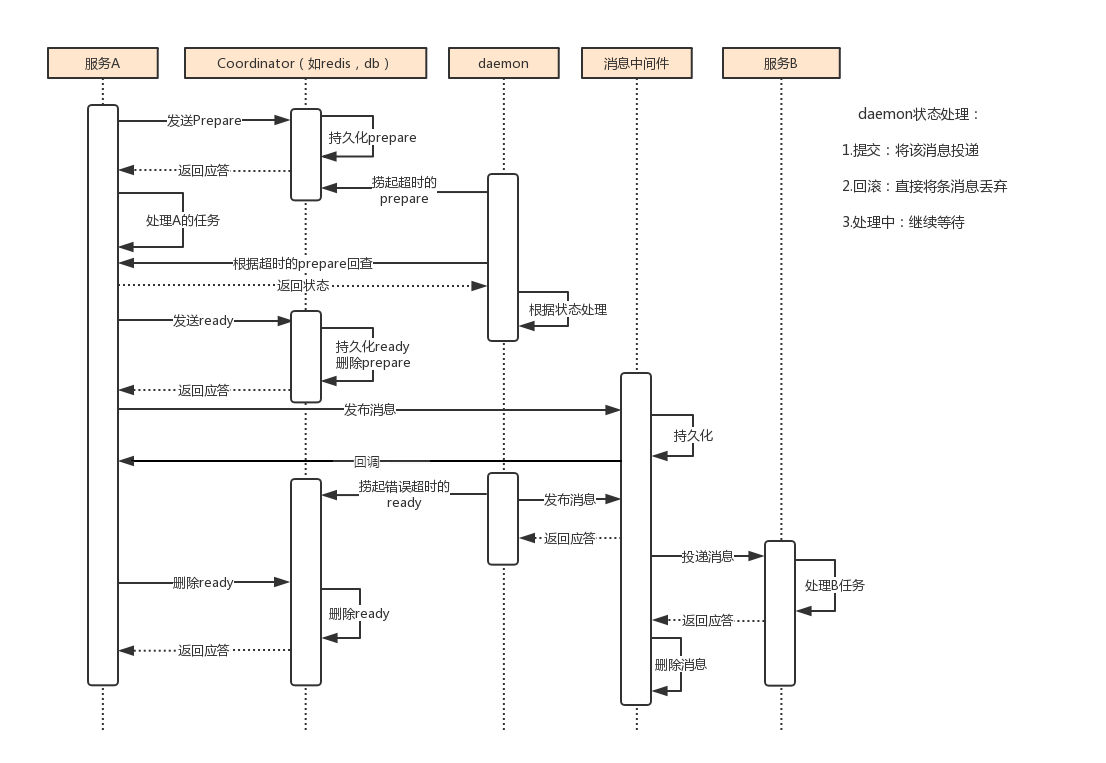
在服务A处理任务A前,首先向Coordinator发送一条prepare(携带回查id)记录,表示要开始这个分布式任务
Coordinator持久化prepare记录后响应服务A
服务A收到确认应答后,服务A处理任务A,成功后发送一条ready记录,Coordinator将删除之前对应的prepare记录,并持久化ready记录和完整的消息
服务A在收到ready记录和消息持久化的应答后,就可以提交消息到消息中间件了,针对rabbitmq可以设置setPublisherConfirms(true)以及实现setConfirmCallback的回调来实现消息中间件持久化应答服务A。这之后对于服务A来说就可以删除之前的ready记录和去处理其他任务了。
消息中间件(rabbitmq可以通过镜像队列来实现高可用)在确定将消息落盘之后就可以向服务B投递消息
服务B消费了该消息,并成功处理了任务B,服务B再向消息中间件返回一个确认应答,告诉消息中间件该消息已经成功消费,此时,这个分布式事务完成。
上述是整个流程,服务A完成任务A后,到任务B执行完成之间,会存在一定的时间差。在这个时间差内,整个系统处于数据不一致的状态,但这短暂的不一致性是可以接受的,因为经过短暂的时间后,系统又可以保持数据一致性,满足BASE理论。
BASE理论:
BA:Basic Available 基本可用
S:Soft State:柔性状态 同一数据的不同副本的状态,可以不需要实时一致。
E:Eventual Consisstency:最终一致性 同一数据的不同副本的状态,可以不需要实时一致,但一定要保证经过一定时间后仍然是一致的。
上面的是一个比较理想的流程,但是真正的环境会有很多突发情况,比如任务A处理失败,那么需要进入回滚流程
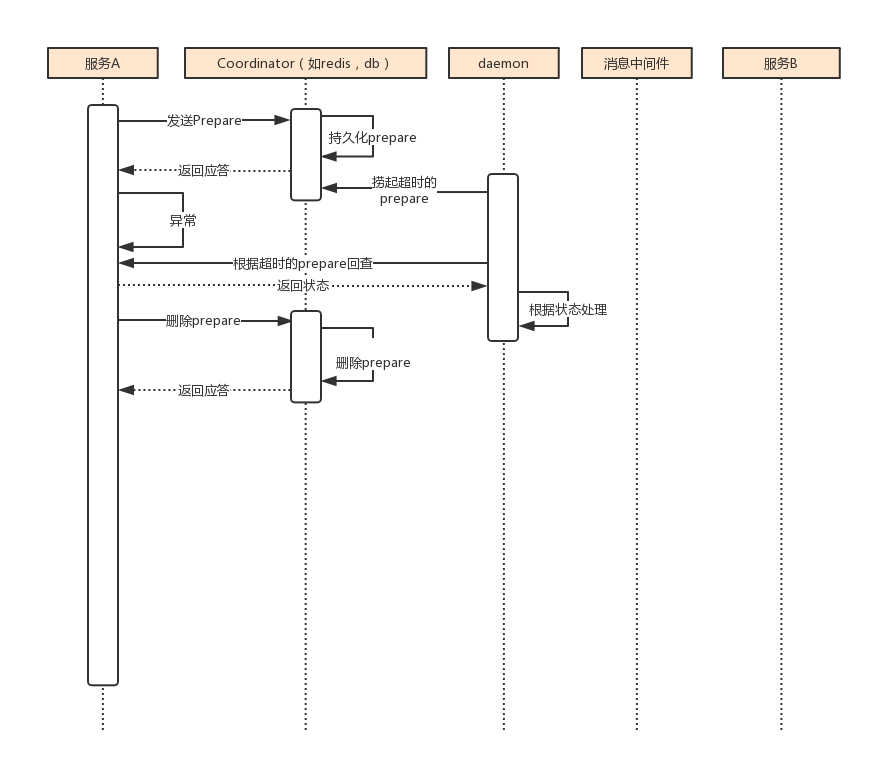
因为任务A的异常对于服务A是可以直接捕获的,回滚异常后删除prepare记录,服务A删除之后便可以认为回滚已经完成,便可以去做其他的事情。
而该消息没有投递到消息中间件,则服务B没有影响。此时系统又处于一致性状态,因为任务A和任务B都没有执行。
Coordinator提供了接口可以自己来实现,我默认实现的方式是用redis。若要使用其他方式可以自行实现接口。
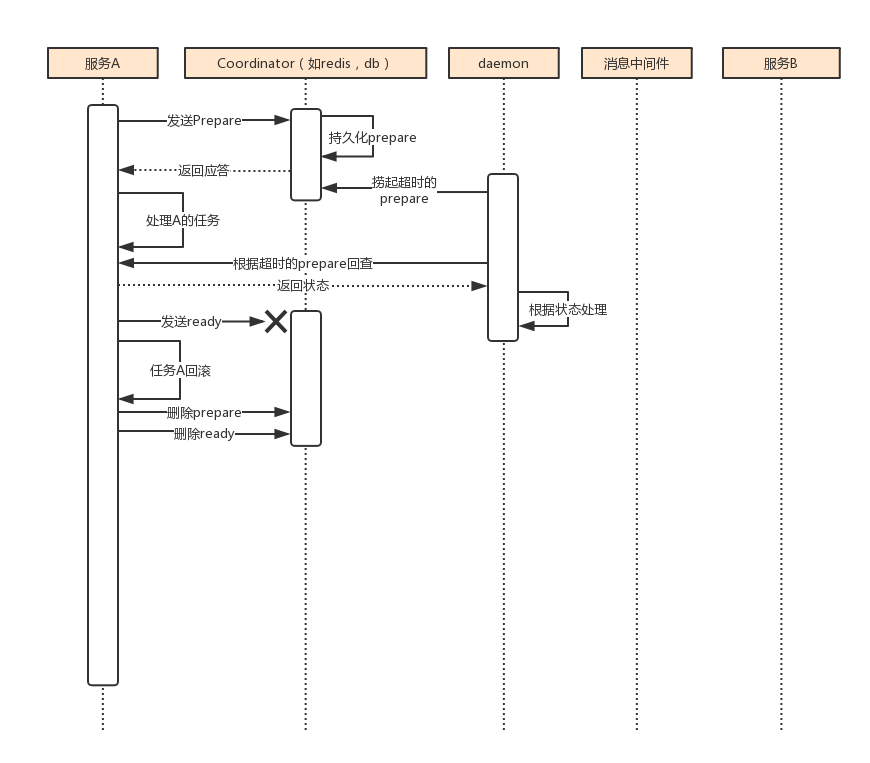
上图表现的是发送ready记录的时候,失败了。这时候对于服务A是会收到异常或者收不到应答,这时候可以直接将之前的任务A进行回滚,任务A在回滚的时候会触发删除ready的操作。同样如果异常是发生在发送prepare的情况下,这时候服务A还没执行任务也不会有影响。
分析完服务A,Coordinator和消息中间件之间的一些情况后,现在分析下消息中间件和服务B之间的一些特殊情况。
当消息成功发布到消息中间件之后,服务A就可以做自己的事情去了,消息中间件会保证消息能成功投递到服务B。这个就是消息中间件在消息投递情况下的可靠性保证,具体流程是消息中间件向下游系统投递完消息后便进入阻塞等待状态,下游系统便立即进行任务的处理,任务处理完成后便向消息中间件返回应答。消息中间件收到确认应答后便认为该事务处理完毕!如果消息在投递过程中丢失,或消息的确认应答在返回途中丢失,那么消息中间件在等待确认应答超时之后就会重新投递,直到下游消费者返回消费成功响应为止。
这之间可以设置消息重试的次数和时间间隔,如果一直失败这时候就会用到死信队列。具体看下图:
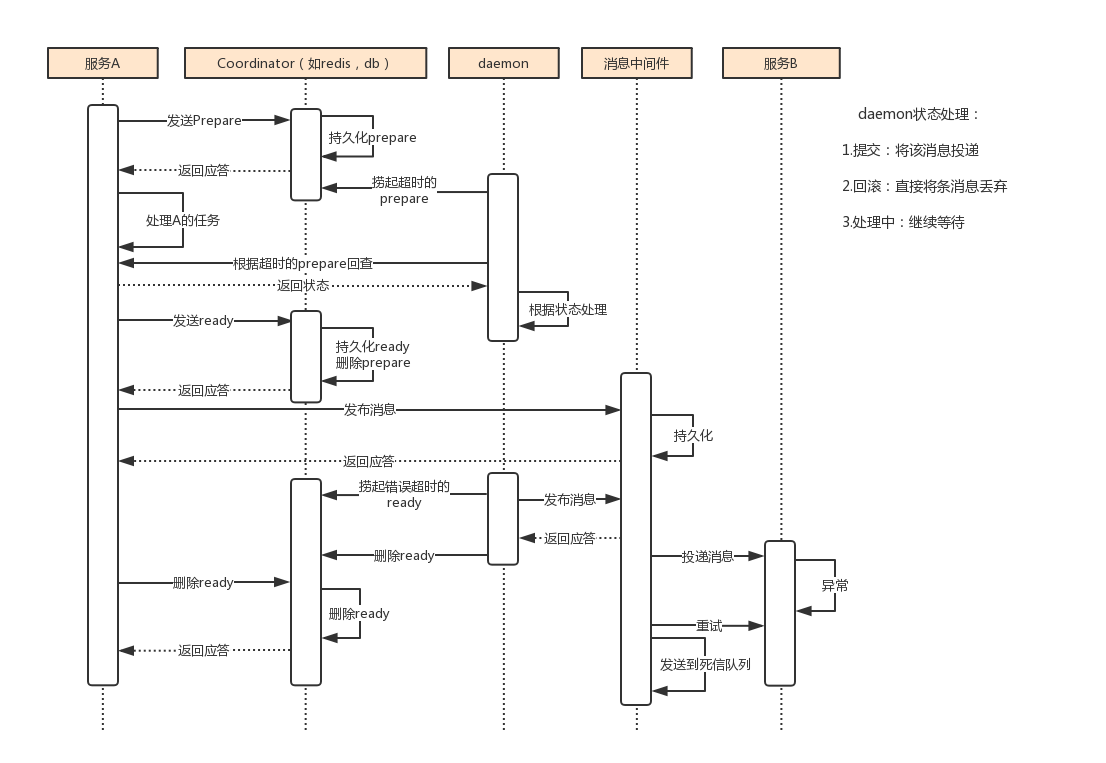
当消息一直无法被正常消费,超过设置的重试阈值就会投递到死信队列,死信队列的exchange和routeKey默认是@DistributedTrans中设置的值。
通过消费死信队列的消息来处理这种异常情况(可以设置短信或邮箱提醒,人工介入),这里暂时不实现服务A的回滚,因为让服务A事先提供回滚接口,这无疑增加了额外的开发成本,业务系统的复杂度也将提高。对于一个业务系统的设计目标是,在保证性能的前提下,最大限度地降低系统复杂度,从而能够降低系统的运维成本。
最后整理一下整个中间件的设计思路
上面已经分析了一些异常情况,对于下游服务和消息中间件的原子性,我们可以通过消息中间件投递的可靠性来保证(就是ACK模式,失败或未收到应答进行重试)。 那么我们要实现分布式事务,剩下的就是要保证上游服务执行的任务和向消息中间件投递消息这2个操作的原子性。
这时候一般就会有两种方案,同步和异步通信。通过之前的时序图,很显然上游系统和消息中间件之间采用的是异步通信,也就是说当上游服务提交完消息后便可以去做别的事情,接下来提交、回滚就完全交给消息中间件来完成,并且完全信任消息中间件,认为它一定能正确地完成事务的提交或回滚。这主要是为了提高系统并发度,另外业务系统直接和用户打交道,用户体验尤为重要,因此这种异步通信方式能够极大程度地降低用户等待时间。
Rabbitmq其实有提供事务机制,使用txSelect(), txCommit()以及txRollback()来实现,通过测试抓包发现,Tx.Commit后直接发送Tx.Commit-Ok,两者之间的时间间隔会比较长,简单的测试能到300ms,这是很耗时的。所以我没有用这种方式,而是引入一个Coordinator(协调者)来实现。
另外还有一个比较关键的daemon(守护线程),是处理在Coordinator一些错误超时的记录(类似Rocketmq的超时询问机制)。所以服务A除了实现正常的业务流程外,还需提供一个事务询问的接口,供Coordinator调用,来保障服务A在执行任务出现宕机的情况。当有prepare超时就会触发访问这个回查接口,该接口会返回三种结果:
提交 将该消息投递
回滚 直接将条消息丢弃
处理中 继续等待,重置时间。
而超时的ready的消息,就直接捞起发送到消息中间件,因为只要是ready消息持久化到协调者,那就说明服务A的任务已经完成。
这样就能保证上游服务和消息中间件的原子性了(具体可以看分布式事务:消息可靠发送),再通过消息中间件可靠的投递结合下游服务,就完成了分布式事务。
感谢各位的阅读,以上就是“数据库的分布式事务流程是什么”的内容了,经过本文的学习后,相信大家对数据库的分布式事务流程是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





