环境采用centos 6.5最小化安装,hadoop下载的hadoop2.7.6.tar.gz安装,Java下载的oracle官网的1.8.0_172的包安装。
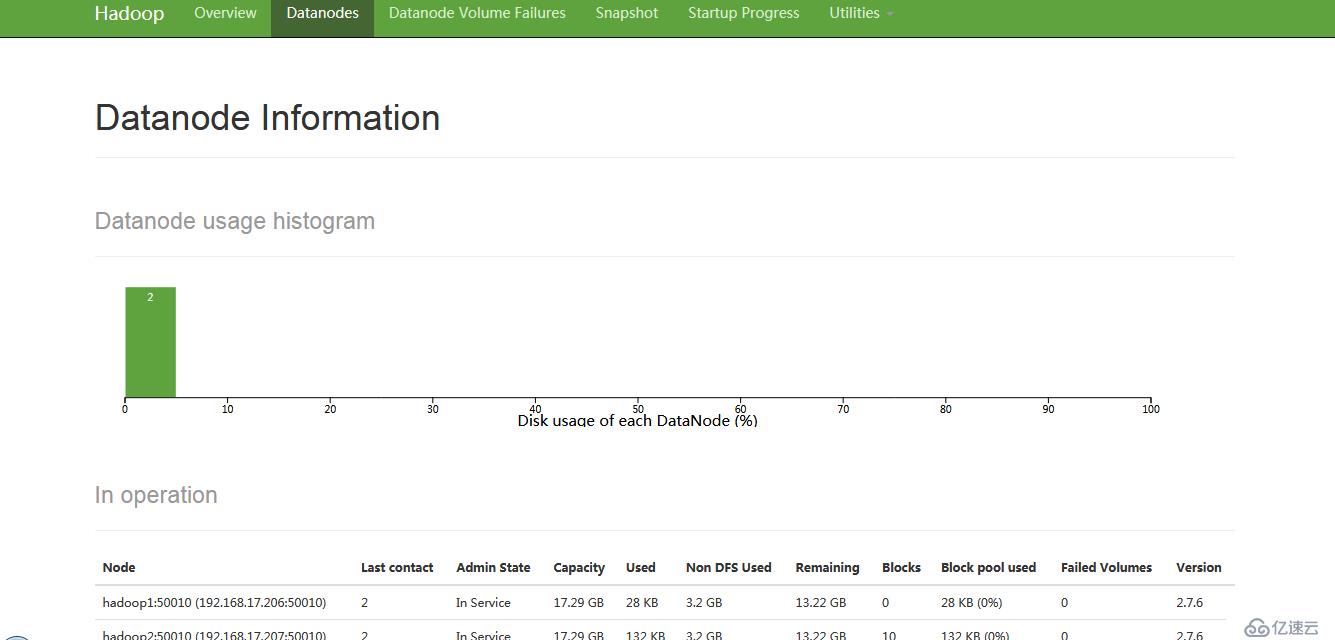
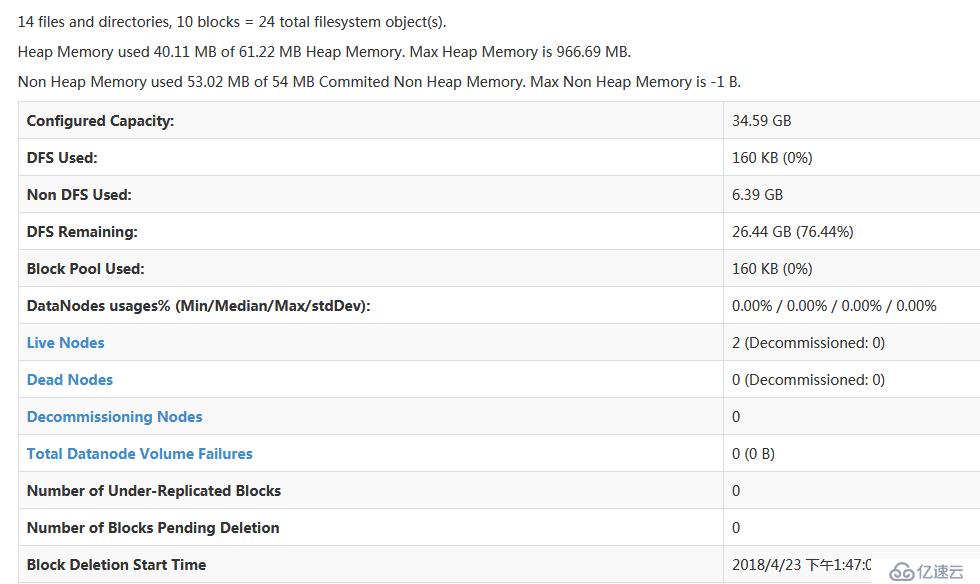
192.168.17.205 Master
192.168.17.206 hadoop1
192.168.17.207 hadoop2
为三台主机添加同一用户,设置密码:
添加用户
useradd hadoop
修改密码
passwd hadoop
SSH 免密码登录安装,配置
保证由master主机能够免密码登录到datanodes节点机上
# ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
#ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.17.206测试
[root@Master ~]# ssh 192.168.17.206
Last login: Mon Apr 23 12:56:33 2018 from 192.168.17.1
[root@hadoop1 ~]#
JDK的安装与卸载
卸载 JDK
# 检查当前安装的JDK
rpm -qa|grep gcj
rpm -qa|grep jdk
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64
#查询当前系统中相关java 目录并删除
whereis java
java: /etc/java /usr/lib/java /usr/share/java
#删除查询出的结果目录
rm -fr /usr/share/java
rm -fr /usr/lib/java
rm -fr /etc/java安装JDK
在usr目录下创建java目录并且下载JDK并且解压到 /usr/java 目录下
cd /usr
mkdir java
cd java
wget http://download.oracle.com/otn-pub/java/jdk/8u102-b14/jdk-8u102-linux-x64.tar.gz
tar -zxvf jdk-8u172-linux-x64.tar.gz可能要手工下载再传进去,下载到的可能是html而不是tar.
编辑 vim /etc/profile 文件并且在末尾追加
JAVA_HOME=/usr/java/jdk1.8.0_172
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export PATH JAVA_HOME CLASSPATH在不重新启动操作系统的情况下使 /etc/profile 文件生效
source /etc/profile
检查java的安装状态
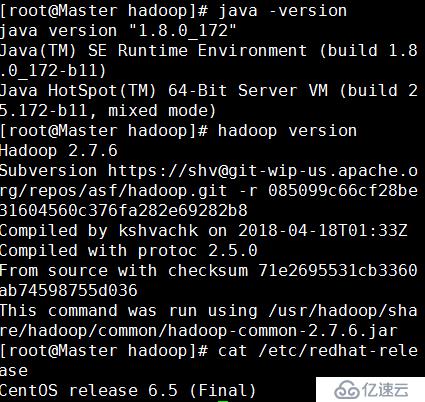
java -version
下载hadoop-2.7.6
cd /tmp
wget http://apache.fayea.com/hadoop/common/hadoop-2.7.3/hadoop-2.7.6.tar.gz
解压 hadoop-2.7.6.tar.gz
tar -zxvf hadoop-2.7.6.tar.gz
复制文件到 /usr 目录下
cp -R /tmp/hadoop-2.7.3 /usr/hadoop
配置hadoop的环境变量,在/etc/profile下追加
vi /etc/profile
追加如下的环境变量设置
HADOOP_HOME=/usr/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin修改 etc/hadoop/hadoop-env.sh 文件
vi etc/hadoop/hadoop-env.sh
# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/java/jdk1.8.0_172修改 etc/hadoop/core-site.xml 文件
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
</configuration>修改 etc/hadoop/hdfs-site.xml 文件
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/tmp/dfs/data</value>
</property>
</configuration>修改 etc/hadoop/yarn-site.xml 文件
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>修改 etc/hadoop/mapred-site.xml 文件
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>修改 etc/hadoop/slaves 文件,添加
192.168.17.206
192.168.17.207
打包文件夹 /usr/hadoop ,复制到 datanode 节点机,保证节点机环境配置与master保持一致格式化文件系统
hdfs namenode -format
启动文件服务
start-dfs.sh
Make the HDFS directories required to execute MapReduce jobs:
关闭文件服务
stop-dfs.sh
创建用户文件系统文件夹
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/hadoop
复制文件本地文件到分布式文件系统 input 下
hdfs dfs -mkdir /input
hdfs dfs -put etc/hadoop/*.xml input
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"把相同配置添加到hadoop-env.sh文件末尾。
对于这些网上的说法已经很多了,主要包括:
1 关闭safemode模式,输入如下命令:
bin/hadoop dfsadmin -safemode leave
2 检查存储空间是否足够,输入如下命令:
df -hl
3 重新格式化hdfs,按照如下步骤
a) 删除master和所有slave上的 hadoop目录下的logs文件,并重新建立
b) 删除master和所有slave上的hdfs存储目录,即conf/core-site.xml配置文件中 hadoop.tmp.dir属性对应的value所指向的目录,并重新建立
4 检查防火墙是否关闭,输入下面命令查看状态:
service iptables status
输入下面命令关闭防火墙
service iptables stop
5 重新检查配置文件
不过上述方法都用过了,依然没有解决问题,下面一点是如何解决了该问题的操作。
检查每台机器上的/etc/hosts文件,将没有用或不清楚作何用的ip:name对删除,最后只留下了
[root@hadoop1 hadoop]# cat /etc/hosts
127.0.0.1 localhost
192.168.17.205 Master
192.168.17.206 hadoop1
192.168.17.207 hadoop2免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





