SpringдёӯжҖҺд№Ҳи§ЈеҶіеҫӘзҺҜдҫқиө–
д»ҠеӨ©е°ұи·ҹеӨ§е®¶иҒҠиҒҠжңүе…іSpringдёӯжҖҺд№Ҳи§ЈеҶіеҫӘзҺҜдҫқиө–пјҢеҸҜиғҪеҫҲеӨҡдәәйғҪдёҚеӨӘдәҶи§ЈпјҢдёәдәҶи®©еӨ§е®¶жӣҙеҠ дәҶи§ЈпјҢе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеёҢжңӣеӨ§е®¶ж №жҚ®иҝҷзҜҮж–Үз« еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
дёҖгҖҒеҫӘзҺҜдҫқиө–жҳҜд»Җд№Ҳпјҹ
еҫӘзҺҜдҫқиө–пјҢе…¶е®һе°ұжҳҜеҫӘзҺҜеј•з”ЁпјҢе°ұжҳҜдёӨдёӘжҲ–иҖ…дёӨдёӘд»ҘдёҠзҡ„ bean дә’зӣёеј•з”ЁеҜ№ж–№пјҢжңҖз»ҲеҪўжҲҗдёҖдёӘй—ӯзҺҜпјҢеҰӮ A дҫқиө– BпјҢB дҫқиө– CпјҢC дҫқиө– AгҖӮеҰӮдёӢеӣҫжүҖзӨәпјҡ
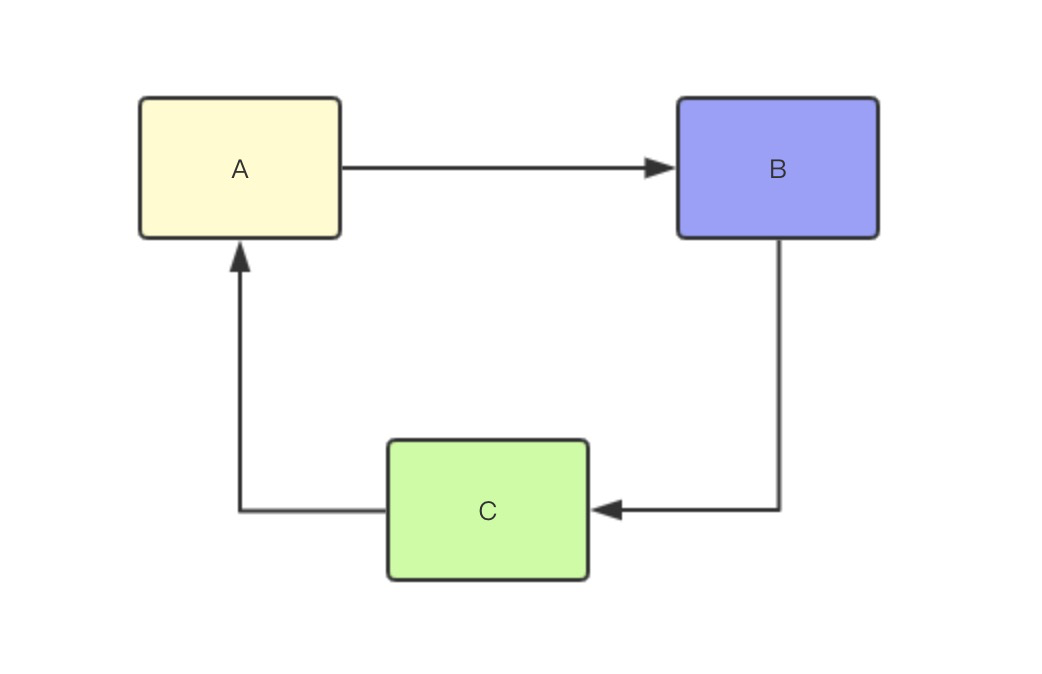
Springдёӯзҡ„еҫӘзҺҜдҫқиө–пјҢе…¶е®һе°ұжҳҜдёҖдёӘжӯ»еҫӘзҺҜзҡ„иҝҮзЁӢпјҢеңЁеҲқе§ӢеҢ– A зҡ„ж—¶еҖҷеҸ‘зҺ°дҫқиө–дәҶ BпјҢиҝҷж—¶е°ұдјҡеҺ»еҲқе§ӢеҢ– BпјҢ然еҗҺеҸҲеҸ‘зҺ° B дҫқиө– CпјҢи·‘еҺ»еҲқе§ӢеҢ– CпјҢеҲқе§ӢеҢ– C зҡ„ж—¶еҖҷеҸ‘зҺ°дҫқиө–дәҶ AпјҢеҲҷеҸҲдјҡеҺ»еҲқе§ӢеҢ– AпјҢдҫқж¬ЎеҫӘзҺҜж°ёдёҚйҖҖеҮәпјҢйҷӨйқһжңүз»Ҳз»“жқЎд»¶гҖӮ
дёҖиҲ¬жқҘиҜҙпјҢSpring еҫӘзҺҜдҫқиө–зҡ„жғ…еҶөжңүдёӨз§Қпјҡ
жһ„йҖ еҷЁзҡ„еҫӘзҺҜдҫқиө–гҖӮ field еұһжҖ§зҡ„еҫӘзҺҜдҫқиө–гҖӮ еҜ№дәҺжһ„йҖ еҷЁзҡ„еҫӘзҺҜдҫқиө–пјҢSpring жҳҜж— жі•и§ЈеҶізҡ„пјҢеҸӘиғҪжҠӣеҮә BeanCurrentlyInCreationException ејӮеёёиЎЁзӨәеҫӘзҺҜдҫқиө–пјҢжүҖд»ҘдёӢйқўжҲ‘们еҲҶжһҗзҡ„йғҪжҳҜеҹәдәҺ field еұһжҖ§зҡ„еҫӘзҺҜдҫқиө–гҖӮ
еңЁеүҚж–Ү Spring Iocжәҗз ҒеҲҶжһҗ д№Ӣ Beanзҡ„еҠ иҪҪпјҲдёүпјүпјҡеҗ„дёӘ scope зҡ„ Bean еҲӣе»ә дёӯжҸҗеҲ°пјҢSpring еҸӘи§ЈеҶі scope дёә singleton зҡ„еҫӘзҺҜдҫқиө–гҖӮеҜ№дәҺscope дёә prototype зҡ„ bean пјҢSpring ж— жі•и§ЈеҶіпјҢзӣҙжҺҘжҠӣеҮә BeanCurrentlyInCreationException ејӮеёёгҖӮ
дёәд»Җд№Ҳ Spring дёҚеӨ„зҗҶ prototype bean е‘ўпјҹе…¶е®һеҰӮжһңзҗҶи§Ј Spring жҳҜеҰӮдҪ•и§ЈеҶі singleton bean зҡ„еҫӘзҺҜдҫқиө–е°ұжҳҺзҷҪдәҶгҖӮиҝҷйҮҢе…Ҳз•ҷдёӘз–‘й—®пјҢжҲ‘们е…ҲжқҘзңӢдёӢ Spring жҳҜеҰӮдҪ•и§ЈеҶі singleton bean зҡ„еҫӘзҺҜдҫқиө–зҡ„гҖӮ
дәҢгҖҒи§ЈеҶіsingletonеҫӘзҺҜдҫқиө–
еңЁAbstractBeanFactory зҡ„ doGetBean()ж–№жі•дёӯпјҢжҲ‘д»¬ж №жҚ®BeanNameеҺ»иҺ·еҸ–Singleton Beanзҡ„ж—¶еҖҷпјҢдјҡе…Ҳд»Һзј“еӯҳиҺ·еҸ–гҖӮ
д»Јз ҒеҰӮдёӢпјҡ
//DefaultSingletonBeanRegistry.java
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// д»ҺдёҖзә§зј“еӯҳзј“еӯҳ singletonObjects дёӯеҠ иҪҪ bean
Object singletonObject = this.singletonObjects.get(beanName);
// зј“еӯҳдёӯзҡ„ bean дёәз©әпјҢдё”еҪ“еүҚ bean жӯЈеңЁеҲӣе»ә
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// еҠ й”Ғ
synchronized (this.singletonObjects) {
// д»Һ дәҢзә§зј“еӯҳ earlySingletonObjects дёӯиҺ·еҸ–
singletonObject = this.earlySingletonObjects.get(beanName);
// earlySingletonObjects дёӯжІЎжңүпјҢдё”е…Ғи®ёжҸҗеүҚеҲӣе»ә
if (singletonObject == null && allowEarlyReference) {
// д»Һ дёүзә§зј“еӯҳ singletonFactories дёӯиҺ·еҸ–еҜ№еә”зҡ„ ObjectFactory
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
//д»ҺеҚ•дҫӢе·ҘеҺӮдёӯиҺ·еҸ–bean
singletonObject = singletonFactory.getObject();
// ж·»еҠ еҲ°дәҢзә§зј“еӯҳ
this.earlySingletonObjects.put(beanName, singletonObject);
// д»Һдёүзә§зј“еӯҳдёӯеҲ йҷӨ
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}иҝҷж®өд»Јз Ғж¶үеҸҠзҡ„3дёӘе…ій”®зҡ„еҸҳйҮҸпјҢеҲҶеҲ«жҳҜ3дёӘзә§еҲ«зҡ„зј“еӯҳпјҢе®ҡд№үеҰӮдёӢпјҡ
/** Cache of singleton objects: bean name --> bean instance */
//еҚ•дҫӢbeanзҡ„зј“еӯҳ дёҖзә§зј“еӯҳ
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name --> ObjectFactory */
//еҚ•дҫӢеҜ№иұЎе·ҘеҺӮзј“еӯҳ дёүзә§зј“еӯҳ
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name --> bean instance */
//йў„еҠ иҪҪеҚ•дҫӢbeanзј“еӯҳ дәҢзә§зј“еӯҳ
//еӯҳж”ҫзҡ„ bean дёҚдёҖе®ҡжҳҜе®Ңж•ҙзҡ„
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
getSingleton()зҡ„йҖ»иҫ‘жҜ”иҫғжё…жҷ°пјҡ
йҰ–е…ҲпјҢе°қиҜ•д»ҺдёҖзә§зј“еӯҳsingletonObjectsдёӯиҺ·еҸ–еҚ•дҫӢBeanгҖӮ
еҰӮжһңиҺ·еҸ–дёҚеҲ°пјҢеҲҷд»ҺдәҢзә§зј“еӯҳearlySingletonObjectsдёӯиҺ·еҸ–еҚ•дҫӢBeanгҖӮ
еҰӮжһңд»Қ然иҺ·еҸ–дёҚеҲ°пјҢеҲҷд»Һдёүзә§зј“еӯҳsingletonFactoriesдёӯиҺ·еҸ–еҚ•дҫӢBeanFactoryгҖӮ
жңҖеҗҺпјҢеҰӮжһңд»Һдёүзә§зј“еӯҳдёӯжӢҝеҲ°дәҶBeanFactoryпјҢеҲҷйҖҡиҝҮgetObject()жҠҠBeanеӯҳе…ҘдәҢзә§зј“еӯҳдёӯпјҢ并жҠҠиҜҘBeanзҡ„дёүзә§зј“еӯҳеҲ жҺүгҖӮ
2.1гҖҒдёүзә§зј“еӯҳ
зңӢеҲ°иҝҷйҮҢеҸҜиғҪдјҡжңүдәӣз–‘й—®пјҢиҝҷ3дёӘзј“еӯҳжҖҺд№Ҳе°ұи§ЈеҶідәҶsingletonеҫӘзҺҜдҫқиө–дәҶе‘ўпјҹ
е…ҲеҲ«зқҖжҖҘпјҢжҲ‘们зҺ°еңЁеҲҶжһҗдәҶиҺ·еҸ–зј“еӯҳзҡ„д»Јз ҒпјҢеҶҚжқҘзңӢдёӢеӯҳеӮЁзј“еӯҳзҡ„д»Јз ҒгҖӮ еңЁ AbstractAutowireCapableBeanFactory зҡ„ doCreateBean() ж–№жі•дёӯпјҢжңүиҝҷд№ҲдёҖж®өд»Јз Ғпјҡ
// AbstractAutowireCapableBeanFactory.java
boolean earlySingletonExposure = (mbd.isSingleton() // еҚ•дҫӢжЁЎејҸ
&& this.allowCircularReferences // е…Ғи®ёеҫӘзҺҜдҫқиө–
&& isSingletonCurrentlyInCreation(beanName)); // еҪ“еүҚеҚ•дҫӢ bean жҳҜеҗҰжӯЈеңЁиў«еҲӣе»ә
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
// дёәдәҶеҗҺжңҹйҒҝе…ҚеҫӘзҺҜдҫқиө–пјҢжҸҗеүҚе°ҶеҲӣе»әзҡ„ bean е®һдҫӢеҠ е…ҘеҲ°дёүзә§зј“еӯҳ singletonFactories дёӯ
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}иҝҷж®өд»Јз Ғе°ұжҳҜputдёүзә§зј“еӯҳsingletonFactoriesзҡ„ең°ж–№пјҢе…¶ж ёеҝғйҖ»иҫ‘жҳҜпјҢеҪ“ж»Ўи¶ід»ҘдёӢ3дёӘжқЎд»¶ж—¶пјҢжҠҠbeanеҠ е…Ҙдёүзә§зј“еӯҳдёӯпјҡ
addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) ж–№жі•пјҢд»Јз ҒеҰӮдёӢпјҡ
// DefaultSingletonBeanRegistry.java
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}д»Һиҝҷж®өд»Јз ҒжҲ‘们еҸҜд»ҘзңӢеҮәпјҢsingletonFactories иҝҷдёӘдёүзә§зј“еӯҳжүҚжҳҜи§ЈеҶі Spring Bean еҫӘзҺҜдҫқиө–зҡ„е…ій”®гҖӮеҗҢж—¶иҝҷж®өд»Јз ҒеҸ‘з”ҹеңЁ createBeanInstance(...) ж–№жі•д№ӢеҗҺпјҢд№ҹе°ұжҳҜиҜҙиҝҷдёӘ bean е…¶е®һе·Із»Ҹиў«еҲӣе»әеҮәжқҘдәҶпјҢдҪҶжҳҜе®ғиҝҳжІЎжңүе®Ңе–„пјҲжІЎжңүиҝӣиЎҢеұһжҖ§еЎ«е……е’ҢеҲқе§ӢеҢ–пјүпјҢдҪҶжҳҜеҜ№дәҺе…¶д»–дҫқиө–е®ғзҡ„еҜ№иұЎиҖҢиЁҖе·Із»Ҹи¶іеӨҹдәҶпјҲе·Із»ҸжңүеҶ…еӯҳең°еқҖдәҶпјҢеҸҜд»Ҙж №жҚ®еҜ№иұЎеј•з”Ёе®ҡдҪҚеҲ°е ҶдёӯеҜ№иұЎпјүпјҢиғҪеӨҹиў«и®ӨеҮәжқҘдәҶгҖӮ
2.2гҖҒдёҖзә§зј“еӯҳ
еҲ°иҝҷйҮҢжҲ‘们еҸ‘зҺ°дёүзә§зј“еӯҳ singletonFactories е’Ң дәҢзә§зј“еӯҳ earlySingletonObjects дёӯзҡ„еҖјйғҪжңүеҮәеӨ„дәҶпјҢйӮЈдёҖзә§зј“еӯҳеңЁе“ӘйҮҢи®ҫзҪ®зҡ„е‘ўпјҹеңЁзұ» DefaultSingletonBeanRegistry дёӯпјҢеҸҜд»ҘеҸ‘зҺ°иҝҷдёӘ addSingleton(String beanName, Object singletonObject) ж–№жі•пјҢд»Јз ҒеҰӮдёӢпјҡ
// DefaultSingletonBeanRegistry.java
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
//ж·»еҠ иҮідёҖзә§зј“еӯҳпјҢеҗҢж—¶д»ҺдәҢзә§гҖҒдёүзә§зј“еӯҳдёӯеҲ йҷӨгҖӮ
this.singletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}иҜҘж–№жі•жҳҜеңЁ #doGetBean(...) ж–№жі•дёӯпјҢеӨ„зҗҶдёҚеҗҢ scope ж—¶пјҢеҰӮжһңжҳҜ singletonи°ғз”Ёзҡ„пјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
 д№ҹе°ұжҳҜиҜҙпјҢдёҖзә§зј“еӯҳйҮҢйқўжҳҜе®Ңж•ҙзҡ„BeanгҖӮ
д№ҹе°ұжҳҜиҜҙпјҢдёҖзә§зј“еӯҳйҮҢйқўжҳҜе®Ңж•ҙзҡ„BeanгҖӮ
е°Ҹз»“пјҡ
дёҖзә§зј“еӯҳйҮҢйқўжҳҜе®Ңж•ҙзҡ„Bean,жҳҜеҪ“дёҖдёӘBeanе®Ңе…ЁеҲӣе»әеҗҺжүҚput
дёүзә§зј“еӯҳжҳҜдёҚе®Ңж•ҙзҡ„BeanFactory,жҳҜеҪ“дёҖдёӘBeanеңЁnewд№ӢеҗҺе°ұput(жІЎжңүеұһжҖ§еЎ«е……гҖҒеҲқе§ӢеҢ–)
дәҢзә§зј“еӯҳжҳҜеҜ№дёүзә§зј“еӯҳзҡ„жҳ“з”ЁжҖ§еӨ„зҗҶпјҢеҸӘдёҚиҝҮжҳҜйҖҡиҝҮgetObject()ж–№жі•д»Һдёүзә§зј“еӯҳзҡ„BeanFactoryдёӯеҸ–еҮәBean
жҖ»з»“
зҺ°еңЁжҲ‘们еҶҚжқҘеӣһйЎҫдёӢSpringи§ЈеҶіеҚ•дҫӢеҫӘзҺҜдҫқиө–зҡ„ж–№жЎҲпјҡ
Spring еңЁеҲӣе»ә bean зҡ„ж—¶еҖҷ并дёҚжҳҜзӯүе®ғе®Ңе…Ёе®ҢжҲҗпјҢиҖҢжҳҜеңЁеҲӣе»әиҝҮзЁӢдёӯе°ҶеҲӣе»әдёӯзҡ„ bean зҡ„ ObjectFactory жҸҗеүҚжӣқе…үпјҲеҚіеҠ е…ҘеҲ° singletonFactories дёүзә§зј“еӯҳдёӯпјүгҖӮ
иҝҷж ·пјҢдёҖж—ҰдёӢдёҖдёӘ bean еҲӣе»әзҡ„ж—¶еҖҷйңҖиҰҒдҫқиө– bean пјҢеҲҷд»Һдёүзә§зј“еӯҳдёӯиҺ·еҸ–гҖӮ
дёҫдёӘж —еӯҗпјҡ
жҜ”еҰӮжҲ‘们еӣўйҳҹйҮҢиҰҒжҠҘеҗҚеҸӮеҠ жҙ»еҠЁпјҢдҪ дёҚз”ЁдёҠжқҘе°ұжҠҠдҪ зҡ„з”ҹж—ҘгҖҒжҖ§еҲ«гҖҒ家еәӯдҝЎжҒҜд»Җд№Ҳзҡ„е…ЁйғЁеЎ«е®ҢпјҢдҪ еҸӘиҰҒе…ҲжҠҘдёӘеҗҚеӯ—пјҢз»ҹи®ЎдёӢдәәж•°е°ұиЎҢпјҢд№ӢеҗҺеҶҚж…ўж…ўе®Ңе–„дҪ зҡ„дёӘдәәдҝЎжҒҜгҖӮ
ж ёеҝғжҖқжғіпјҡжҸҗеүҚжҡҙйңІпјҢе…Ҳз”ЁзқҖ
жңҖеҗҺжқҘжҸҸиҝ°дёӢе°ұдёҠйқўйӮЈдёӘеҫӘзҺҜдҫқиө– Spring и§ЈеҶізҡ„иҝҮзЁӢпјҡ
йҰ–е…Ҳ A е®ҢжҲҗеҲқе§ӢеҢ–第дёҖжӯҘ并е°ҶиҮӘе·ұжҸҗеүҚжӣқе…үеҮәжқҘпјҲйҖҡиҝҮ дёүзә§зј“еӯҳ е°ҶиҮӘе·ұжҸҗеүҚжӣқе…үпјүпјҢеңЁеҲқе§ӢеҢ–зҡ„ж—¶еҖҷпјҢеҸ‘зҺ°иҮӘе·ұдҫқиө–еҜ№иұЎ BпјҢжӯӨж—¶е°ұдјҡеҺ»е°қиҜ• get(B)пјҢиҝҷдёӘж—¶еҖҷеҸ‘зҺ° B иҝҳжІЎжңүиў«еҲӣе»әеҮәжқҘ
然еҗҺ B е°ұиө°еҲӣе»әжөҒзЁӢпјҢеңЁ B еҲқе§ӢеҢ–зҡ„ж—¶еҖҷпјҢеҗҢж ·еҸ‘зҺ°иҮӘе·ұдҫқиө– CпјҢC д№ҹжІЎжңүиў«еҲӣе»әеҮәжқҘ
иҝҷдёӘж—¶еҖҷ C еҸҲејҖе§ӢеҲқе§ӢеҢ–иҝӣзЁӢпјҢдҪҶжҳҜеңЁеҲқе§ӢеҢ–зҡ„иҝҮзЁӢдёӯеҸ‘зҺ°иҮӘе·ұдҫқиө– AпјҢдәҺжҳҜе°қиҜ• get(A)пјҢиҝҷдёӘж—¶еҖҷз”ұдәҺ A е·Із»Ҹж·»еҠ иҮізј“еӯҳдёӯпјҲдёүзә§зј“еӯҳ singletonFactories пјүпјҢйҖҡиҝҮ ObjectFactory жҸҗеүҚжӣқе…үпјҢжүҖд»ҘеҸҜд»ҘйҖҡиҝҮ ObjectFactory#getObject() ж–№жі•жқҘжӢҝеҲ° A еҜ№иұЎпјҢC жӢҝеҲ° A еҜ№иұЎеҗҺйЎәеҲ©е®ҢжҲҗеҲқе§ӢеҢ–пјҢ然еҗҺе°ҶиҮӘе·ұж·»еҠ еҲ°дёҖзә§зј“еӯҳдёӯ
еӣһеҲ° B пјҢB д№ҹеҸҜд»ҘжӢҝеҲ° C еҜ№иұЎпјҢе®ҢжҲҗеҲқе§ӢеҢ–пјҢA еҸҜд»ҘйЎәеҲ©жӢҝеҲ° B е®ҢжҲҗеҲқе§ӢеҢ–гҖӮеҲ°иҝҷйҮҢж•ҙдёӘй“ҫи·Ҝе°ұе·Із»Ҹе®ҢжҲҗдәҶеҲқе§ӢеҢ–иҝҮзЁӢдәҶ
http://cmsblogs.com/?p=todo пјҲе°ҸжҳҺе“Ҙпјү
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们еҜ№SpringдёӯжҖҺд№Ҳи§ЈеҶіеҫӘзҺҜдҫқиө–жңүиҝӣдёҖжӯҘзҡ„дәҶи§Јеҗ—пјҹеҰӮжһңиҝҳжғідәҶи§ЈжӣҙеӨҡзҹҘиҜҶжҲ–иҖ…зӣёе…іеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеӨ§е®¶зҡ„ж”ҜжҢҒгҖӮ





