这篇文章将为大家详细讲解有关如何解决RocketMQ主从同步若干问题,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
主从同步基本实现过程如下图所示: 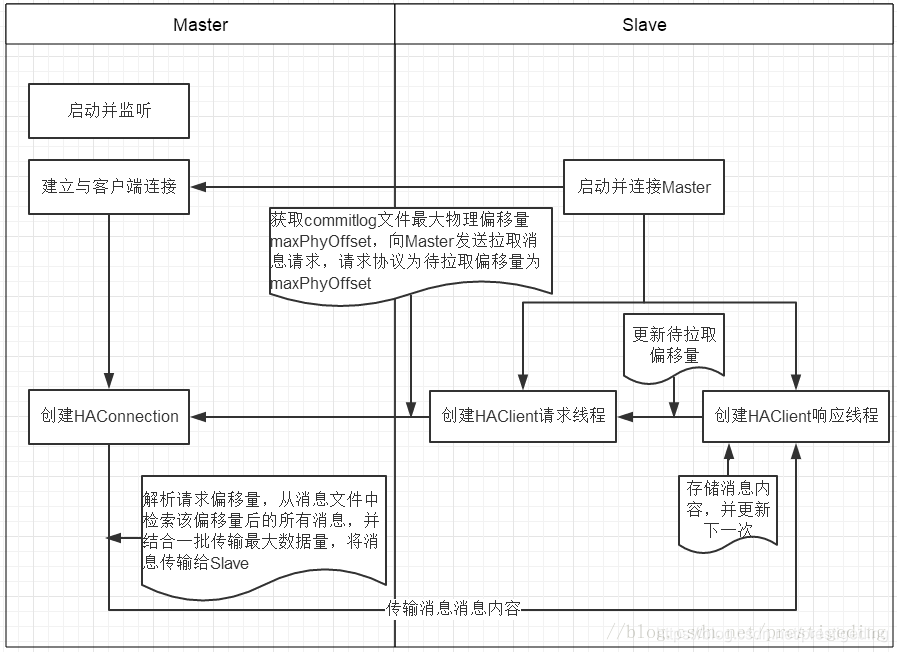
RocketMQ 的主从同步机制如下:
首先启动Master并在指定端口监听;
客户端启动,主动连接Master,建立TCP连接;
客户端以每隔5s的间隔时间向服务端拉取消息,如果是第一次拉取的话,先获取本地commitlog文件中最大的偏移量,以该偏移量向服务端拉取消息;
服务端解析请求,并返回一批数据给客户端;
客户端收到一批消息后,将消息写入本地commitlog文件中,然后向Master汇报拉取进度,并更新下一次待拉取偏移量;
然后重复第3步;
RocketMQ主从同步一个重要的特征:主从同步不具备主从切换功能,即当主节点宕机后,从不会接管消息发送,但可以提供消息读取。
> 温馨提示:本文并不会详细分析RocketMQ主从同步的实现细节,如大家对其感兴趣,可以查阅笔者所著的《RocketMQ技术内幕》或查看笔者博文:RocketMQ主从同步详解
主,从服务器都在运行过程中,消息消费者是从主拉取消息还是从从拉取?
RocketMQ主从同步架构中,如果主服务器宕机,从服务器会接管消息消费,此时消息消费进度如何保持,当主服务器恢复后,消息消费者是从主拉取消息还是从从服务器拉取,主从服务器之间的消息消费进度如何同步?
接下来带着上述问题,一起来探究其实现原理。
RocketMQ的主从同步,在默认情况下RocketMQ会优先选择从主服务器进行拉取消息,并不是通常意义的上的读写分离,那什么时候会从拉取呢?
> 温馨提示:本节同样不会详细整个流程,只会点出其关键点,如果想详细了解消息拉取、消息消费等核心流程,建议大家查阅笔者所著的《RocketMQ技术内幕》。
在RocketMQ中判断是从主拉取,还是从从拉取的核心代码如下: DefaultMessageStore#getMessage
long diff = maxOffsetPy - maxPhyOffsetPulling; // [@1](https://my.oschina.net/u/1198) long memory = (long) (StoreUtil.TOTAL_PHYSICAL_MEMORY_SIZE * (this.messageStoreConfig.getAccessMessageInMemoryMaxRatio() / 100.0)); // @2 getResult.setSuggestPullingFromSlave(diff > memory); // [@3](https://my.oschina.net/u/2648711)
代码@1:首先介绍一下几个局部变量的含义:
maxOffsetPy 当前最大的物理偏移量。返回的偏移量为已存入到操作系统的PageCache中的内容。
maxPhyOffsetPulling 本次消息拉取最大物理偏移量,按照消息顺序拉取的基本原则,可以基本预测下次开始拉取的物理偏移量将大于该值,并且就在其附近。
diff maxOffsetPy与maxPhyOffsetPulling之间的间隔,getMessage通常用于消息消费时,即这个间隔可以理解为目前未处理的消息总大小。
代码@2:获取RocketMQ消息存储在PageCache中的总大小,如果当RocketMQ容量超过该阔值,将会将被置换出内存,如果要访问不在PageCache中的消息,则需要从磁盘读取。
StoreUtil.TOTAL_PHYSICAL_MEMORY_SIZE 返回当前系统的总物理内存。参数
accessMessageInMemoryMaxRatio 设置消息存储在内存中的阀值,默认为40。 结合代码@2这两个参数的含义,算出RocketMQ消息能映射到内存中最大值为40% * (机器物理内存)。
代码@3:设置下次拉起是否从从拉取标记,触发下次从从服务器拉取的条件为:当前所有可用消息数据(所有commitlog)文件的大小已经超过了其阔值,默认为物理内存的40%。
那GetResult的suggestPullingFromSlave属性在哪里使用呢?
PullMessageProcessor#processRequest
if (getMessageResult.isSuggestPullingFromSlave()) { // @1
responseHeader.setSuggestWhichBrokerId(subscriptionGroupConfig.getWhichBrokerWhenConsumeSlowly());
} else {
responseHeader.setSuggestWhichBrokerId(MixAll.MASTER_ID);
}
switch (this.brokerController.getMessageStoreConfig().getBrokerRole()) { // @2
case ASYNC_MASTER:
case SYNC_MASTER:
break;
case SLAVE:
if (!this.brokerController.getBrokerConfig().isSlaveReadEnable()) {
response.setCode(ResponseCode.PULL_RETRY_IMMEDIATELY);
responseHeader.setSuggestWhichBrokerId(MixAll.MASTER_ID);
}
break;
}
if (this.brokerController.getBrokerConfig().isSlaveReadEnable()) { // @3
// consume too slow ,redirect to another machine
if (getMessageResult.isSuggestPullingFromSlave()) {
responseHeader.setSuggestWhichBrokerId(subscriptionGroupConfig.getWhichBrokerWhenConsumeSlowly());
}
// consume ok
else {
responseHeader.setSuggestWhichBrokerId(subscriptionGroupConfig.getBrokerId());
}
} else {
responseHeader.setSuggestWhichBrokerId(MixAll.MASTER_ID);
}代码@1:如果从commitlog文件查找消息时,发现消息堆积太多,默认超过物理内存的40%后,会建议从从服务器读取。
代码@2:如果当前服务器的角色为从服务器:并且slaveReadEnable=true,则忽略代码@1设置的值,下次拉取切换为从主拉取。
代码@3:如果slaveReadEnable=true(从允许读),并且建议从从服务器读取,则从消息消费组建议当消息消费缓慢时建议的拉取brokerId,由订阅组配置属性whichBrokerWhenConsumeSlowly决定;如果消息消费速度正常,则使用订阅组建议的brokerId拉取消息进行消费,默认为主服务器。如果不允许从可读,则固定使用从主拉取。
> 温馨提示:请注意broker服务参数slaveReadEnable,与订阅组配置信息:whichBrokerWhenConsumeSlowly、brokerId的值,在生产环境中,可以通过updateSubGroup命令动态改变订阅组的配置信息。
如果订阅组的配置保持默认值的话,拉取消息请求发送到从服务器后,下一次消息拉取,无论是否开启slaveReadEnable,下一次拉取,还是会发往主服务器。
上面的步骤,在消息拉取命令的返回字段中,会将下次建议拉取Broker返回给客户端,根据其值从指定的broker拉取。
消息拉取实现PullAPIWrapper在处理拉取结果时会将服务端建议的brokerId更新到broker拉取缓存表中。 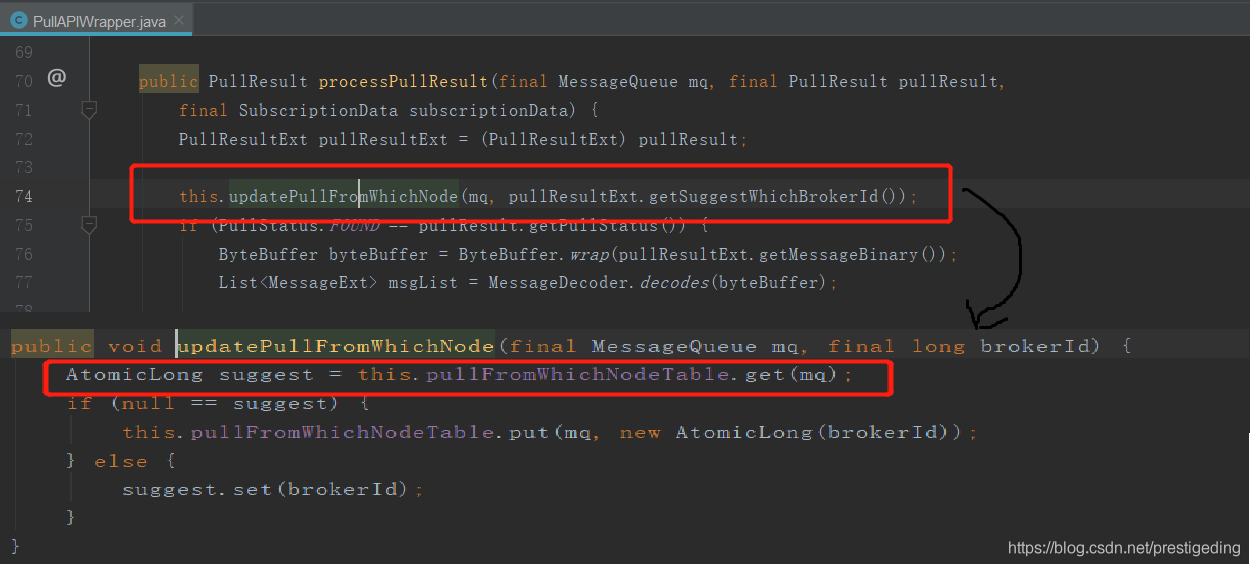
在发起拉取请求之前,首先根据如下代码,选择待拉取消息的Broker。 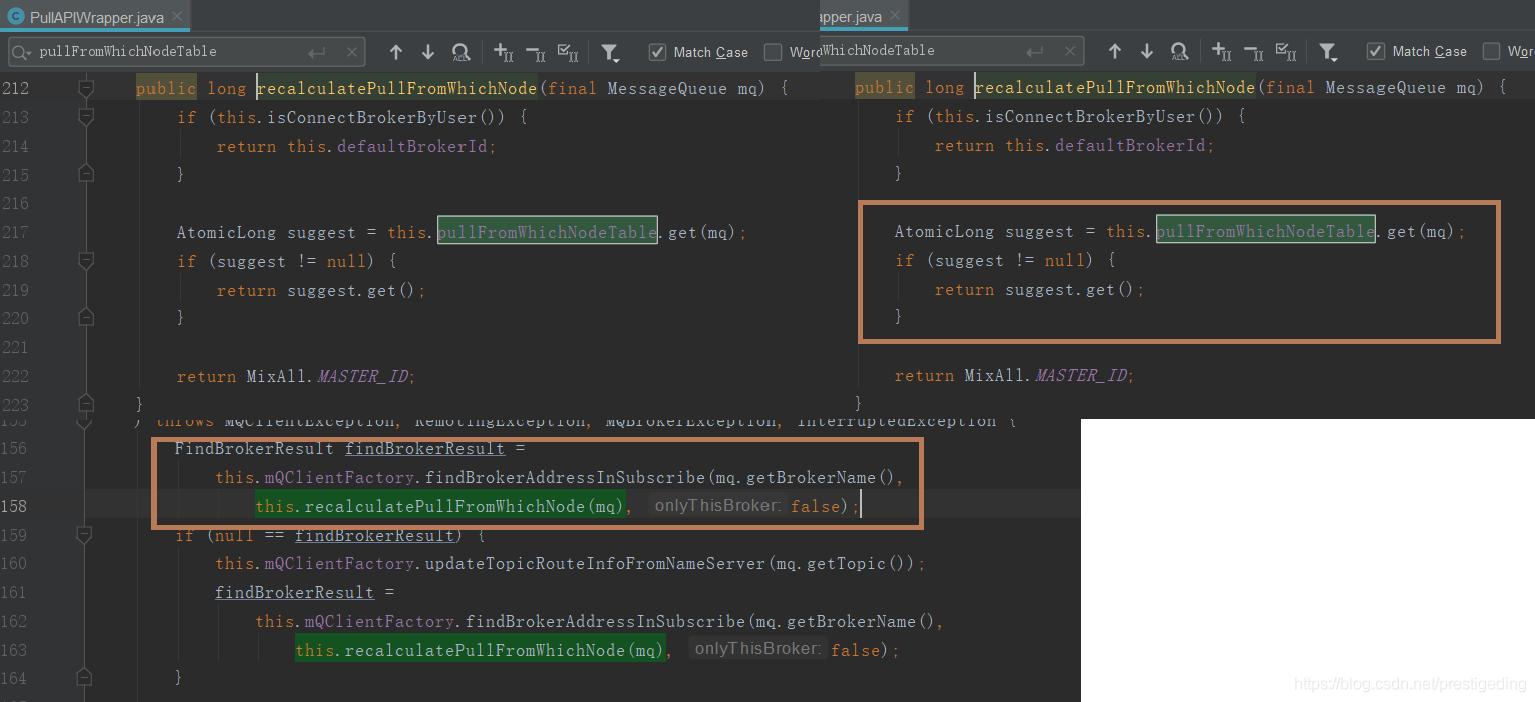
从上面内容可知,主从同步引入的主要目的就是消息堆积的内容默认超过物理内存的40%,则消息读取则由从服务器来接管,实现消息的读写分离,避免主服务IO抖动严重。那问题来了,主服务器宕机后,从服务器接管消息消费后,那消息消费进度存储在哪里?当主服务器恢复正常后,消息是从主服务器拉取还是从从服务器拉取?主服务器如何得知最新的消息消费进度呢?
RocketMQ消息消费进度管理(集群模式): 集群模式下消息消费进度存储文件位于服务端${ROCKETMQ_HOME}/store/config/consumerOffset.json。消息消费者从服务器拉取一批消息后提交到消费组特定的线程池中处理消息,当消息消费成功后会向Broker发送ACK消息,告知消费端已成功消费到哪条消息,Broker收到消息消费进度反馈后,首先存储在内存中,然后定时持久化到consumeOffset.json文件中。备注:关于消息消费进度管理更多的实现细节,建议查阅笔者所著的《RocketMQ技术内幕》。
我们先看一下客户端向服务端反馈消息消费进度时如何选择Broker。 因为主服务的brokerId为0,默认情况下当主服务器存活的时候,优先会选择主服务器,只有当主服务器宕机的情况下,才会选择从服务器。
既然集群模式下消息消费进度存储在Broker端,当主服务器正常时,消息消费进度文件存储在主服务器,那提出如下两个问题: 1)消息消费端在主服务器存活的情况下,会优先向主服务器反馈消息消费进度,那从服务器是如何同步消息消费进度的。 2)当主服务器宕机后则消息消费端会向从服务器反馈消息消费进度,此时消息消费进度如何存储,当主服务器恢复正常后,主服务器如何得知最新的消息消费进度。
为了解开上述两个疑问,我们优先来看一下Broker服务器在收到提交消息消费进度反馈命令后的处理逻辑:
客户端定时向Broker端发送更新消息消费进度的请求,其入口为:RemoteBrokerOffsetStore#updateConsumeOffsetToBroker,该方法中一个非常关键的点是:选择broker的逻辑,如下所示: 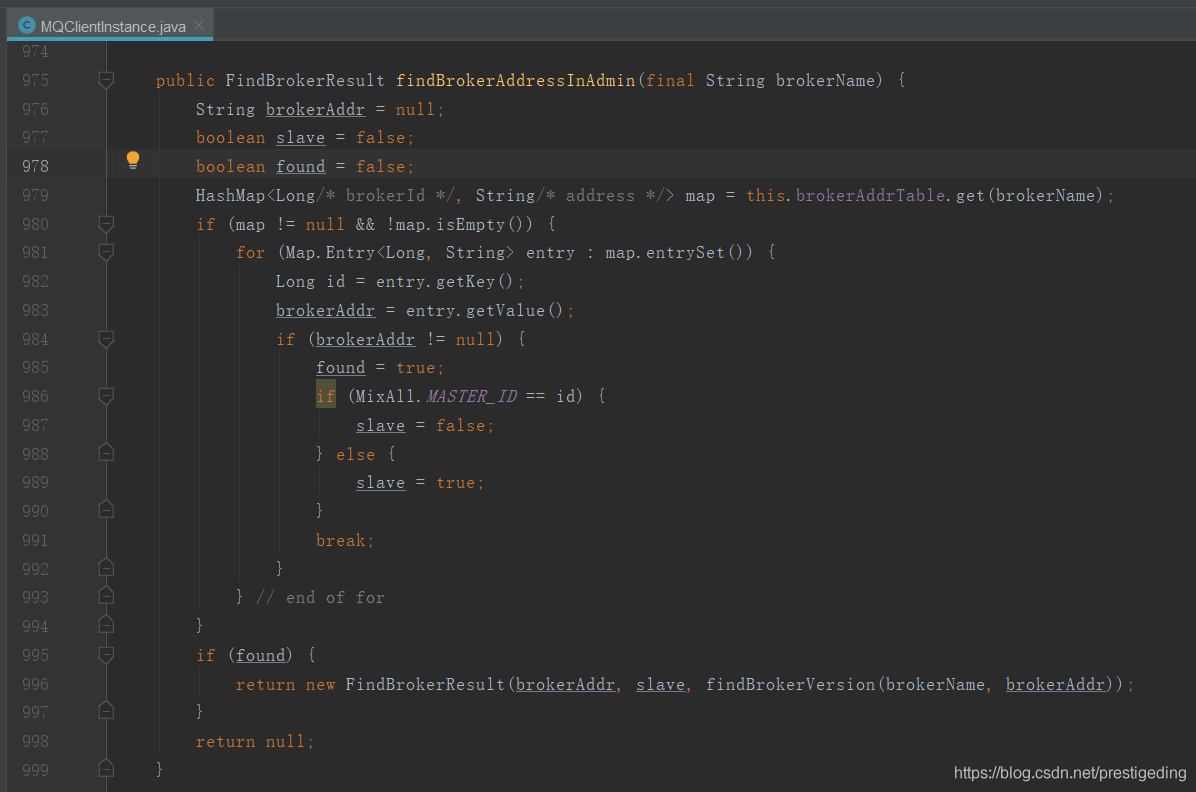
如果主服务器存活,则选择主服务器,如果主服务器宕机,则选择从服务器。也就是说,不管消息是从主服务器拉取的还是从从服务器拉取的,提交消息消费进度请求,优先选择主服务器。服务端就是接收其偏移量,更新到服务端的内存中,然后定时持久化到${ROCKETMQ_HOME}/store/config/consumerOffset.json。
经过上面的分析,我们来讨论一下这个场景: 消息消费者首先从主服务器拉取消息,并向其提交消息消费进度,如果当主服务器宕机后,从服务器会接管消息拉取服务,此时消息消费进度存储在从服务器,主从服务器的消息消费进度会出现不一致?那当主服务器恢复正常后,两者之间的消息消费进度如何同步?
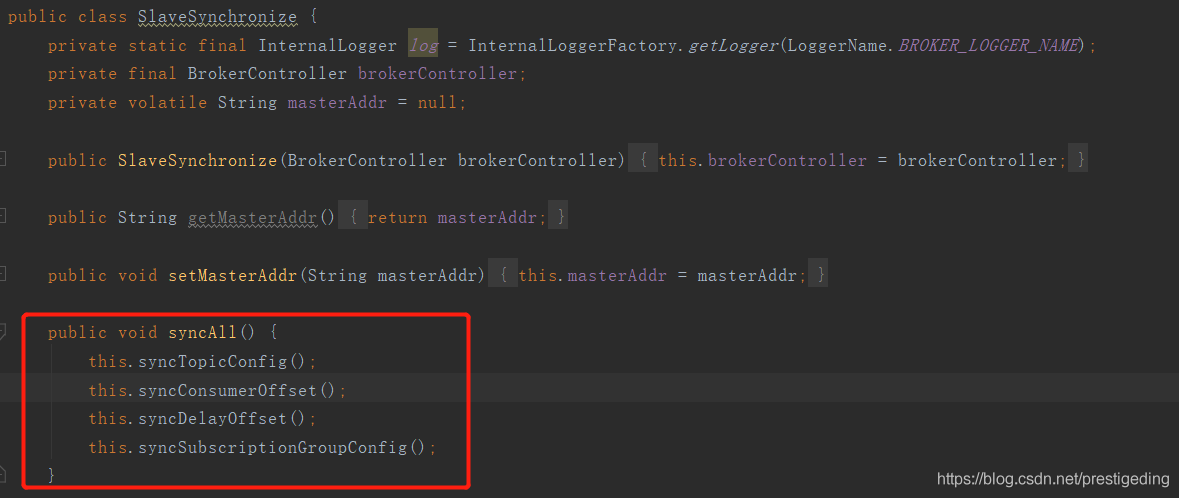
如果Broker角色为从服务器,会通过定时任务调用syncAll,从主服务器定时同步topic路由信息、消息消费进度、延迟队列处理进度、消费组订阅信息。
那问题来了,如果主服务器启动后,从服务器马上从主服务器同步消息消息进度,那岂不是又要重新消费?
其实在绝大部分情况下,就算从服务从主服务器同步了很久之前的消费进度,只要消息者没有重新启动,就不需要重新消费,在这种情况下,RocketMQ提供了两种机制来确保不丢失消息消费进度。
第一种,消息消费者在内存中存在最新的消息消费进度,继续以该进度去服务器拉取消息后,消息处理完后,会定时向Broker服务器反馈消息消费进度,在上面也提到过,在反馈消息消费进度时,会优先选择主服务器,此时主服务器的消息消费进度就立马更新了,从服务器此时只需定时同步主服务器的消息消费进度即可。
第二种是,消息消费者在向主服务器拉取消息时,如果是是主服务器,在处理消息拉取时,也会更新消息消费进度。
主服务器在处理消息拉取命令时,会触发消息消费进度的更新,其代码入口为:PullMessageProcessor#processRequest
boolean storeOffsetEnable = brokerAllowSuspend; // @1
storeOffsetEnable = storeOffsetEnable && hasCommitOffsetFlag;
storeOffsetEnable = storeOffsetEnable
&& this.brokerController.getMessageStoreConfig().getBrokerRole() != BrokerRole.SLAVE; // @2
if (storeOffsetEnable) {
this.brokerController.getConsumerOffsetManager().commitOffset(RemotingHelper.parseChannelRemoteAddr(channel),
requestHeader.getConsumerGroup(), requestHeader.getTopic(), requestHeader.getQueueId(), requestHeader.getCommitOffset());
}代码@1:首先介绍几个局部变量的含义:
brokerAllowSuspend:broker是否允许挂起,在消息拉取时,该值默认为true。
hasCommitOffsetFlag:消息消费者在内存中是否缓存了消息消费进度,如果缓存了,该标记设置为true。 如果Broker的角色为主服务器,并且上面两个变量都为true,则首先使用commitOffset更新消息消费进度。
看到这里,主从同步消息消费进度的相关问题,应该就有了答案了。
上述实现原理的讲解有点枯燥无味,我们先来回答如下几个问题:
1、主,从服务器都在运行过程中,消息消费者是从主拉取消息还是从从拉取? 答:默认情况下,RocketMQ消息消费者从主服务器拉取,当主服务器积压的消息超过了物理内存的40%,则建议从从服务器拉取。但如果slaveReadEnable为false,表示从服务器不可读,从服务器也不会接管消息拉取。
2、当消息消费者向从服务器拉取消息后,会一直从从服务器拉取? 答:不是的。分如下情况: 1)如果从服务器的slaveReadEnable设置为false,则下次拉取,从主服务器拉取。 2)如果从服务器允许读取并且从服务器积压的消息未超过其物理内存的30%,下次拉取使用的Broker为订阅组的brokerId指定的Broker服务器,该值默认为0,代表主服务器。 3)如果从服务器允许读取并且从服务器积压的消息超过了其物理内存的30%,下次拉取使用的Broker为订阅组的whichBrokerWhenConsumeSlowly指定的Broker服务器,该值默认为1,代表从服务器。
3、主从服务消息消费进是如何同步的? 答:消息消费进度的同步时单向的,从服务器开启一个定时任务,定时从主服务器同步消息消费进度;无论消息消费者是从主服务器拉的消息还是从从服务器拉取的消息,在向Broker反馈消息消费进度时,优先向主服务器汇报;消息消费者向主服务器拉取消息时,如果消息消费者内存中存在消息消费进度时,主会尝试跟新消息消费进度。
读写分离的正确使用姿势: 1、主从Broker服务器的slaveReadEnable设置为true。 2、通过updateSubGroup命令更新消息组whichBrokerWhenConsumeSlowly、brokerId,特别是其brokerId不要设置为0,不然从从服务器拉取一次后,下一次拉取就会从主去拉取。
关于如何解决RocketMQ主从同步若干问题就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





