本篇文章为大家展示了怎样使用Apache Flink中的Table SQL APIx,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
虽然Flink已经支持了DataSet和DataStream API,但是有没有一种更好的方式去编程,而不用关心具体的API实现?不需要去了解Java和Scala的具体实现。
Flink provides three layered APIs. Each API offers a different trade-off between conciseness and expressiveness and targets different use cases.
Flink提供了三层API,每一层API提供了一个在简洁性和表达力之间的权衡 。
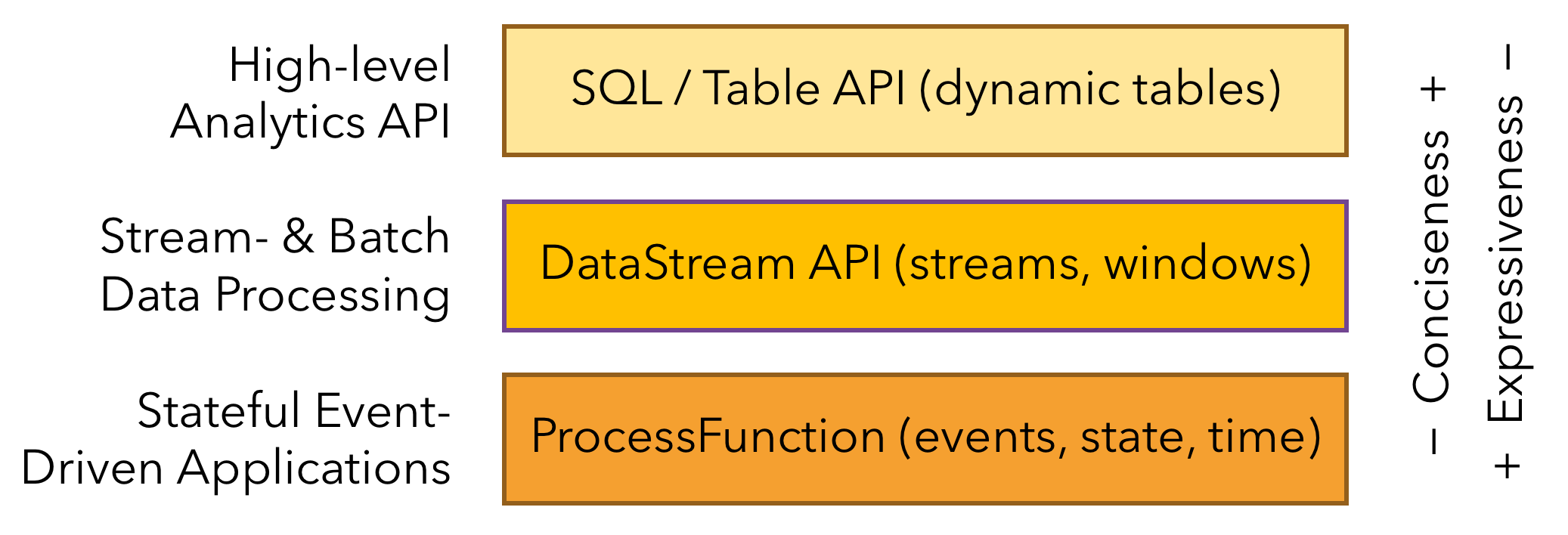
最低层是一个有状态的事件驱动。在这一层进行开发是非常麻烦的。
虽然很多功能基于DataSet和DataStreamAPI是可以完成的,需要熟悉这两套API,而且必须要熟悉Java和Scala,这是有一定的难度的。一个框架如果在使用的过程中没法使用SQL来处理,那么这个框架就有很大的限制。虽然对于开发人员无所谓,但是对于用户来说却不显示。因此SQL是非常面向大众语言。
好比MapReduce使用Hive SQL,Spark使用Spark SQL,Flink使用Flink SQL。
虽然Flink支持批处理/流处理,那么如何做到API层面的统一?
这样Table和SQL应运而生。
这其实就是一个关系型API,操作起来如同操作Mysql一样简单。
Apache Flink features two relational APIs - the Table API and SQL - for unified stream and batch processing. The Table API is a language-integrated query API for Scala and Java that allows the composition of queries from relational operators such as selection, filter, and join in a very intuitive way.
Apache Flink通过使用Table API和SQL 两大特性,来统一批处理和流处理。 Table API是一个查询API,集成了Scala和Java语言,并且允许使用select filter join等操作。
使用Table SQL API需要额外依赖
java:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>scala:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>首先导入上面的依赖,然后读取sales.csv文件,文件内容如下:
transactionId,customerId,itemId,amountPaid 111,1,1,100.0 112,2,2,505.0 113,1,3,510.0 114,2,4,600.0 115,3,2,500.0 116,4,2,500.0 117,1,2,500.0 118,1,2,500.0 119,1,3,500.0 120,1,2,500.0 121,2,4,500.0 122,1,2,500.0 123,1,4,500.0 124,1,2,500.0
object TableSQLAPI {
def main(args: Array[String]): Unit = {
val bEnv = ExecutionEnvironment.getExecutionEnvironment
val bTableEnv = BatchTableEnvironment.create(bEnv)
val filePath="E:/test/sales.csv"
// 已经拿到DataSet
val csv = bEnv.readCsvFile[SalesLog](filePath,ignoreFirstLine = true)
// DataSet => Table
}
case class SalesLog(transactionId:String,customerId:String,itemId:String,amountPaid:Double
)
}首先拿到DataSet,接下来将DataSet转为Table,然后就可以执行SQL了
// DataSet => Table
val salesTable = bTableEnv.fromDataSet(csv)
// 注册成Table Table => table
bTableEnv.registerTable("sales", salesTable)
// sql
val resultTable = bTableEnv.sqlQuery("select customerId, sum(amountPaid) money from sales group by customerId")
bTableEnv.toDataSet[Row](resultTable).print()输出结果如下:
4,500.0 3,500.0 1,4110.0 2,1605.0
这种方式只需要使用SQL就可以实现之前写mapreduce的功能。大大方便了开发过程。
package com.vincent.course06;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.BatchTableEnvironment;
import org.apache.flink.types.Row;
public class JavaTableSQLAPI {
public static void main(String[] args) throws Exception {
ExecutionEnvironment bEnv = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment bTableEnv = BatchTableEnvironment.create(bEnv);
DataSource<Sales> salesDataSource = bEnv.readCsvFile("E:/test/sales.csv").ignoreFirstLine().
pojoType(Sales.class, "transactionId", "customerId", "itemId", "amountPaid");
Table sales = bTableEnv.fromDataSet(salesDataSource);
bTableEnv.registerTable("sales", sales);
Table resultTable = bTableEnv.sqlQuery("select customerId, sum(amountPaid) money from sales group by customerId");
DataSet<Row> rowDataSet = bTableEnv.toDataSet(resultTable, Row.class);
rowDataSet.print();
}
public static class Sales {
public String transactionId;
public String customerId;
public String itemId;
public Double amountPaid;
@Override
public String toString() {
return "Sales{" +
"transactionId='" + transactionId + '\'' +
", customerId='" + customerId + '\'' +
", itemId='" + itemId + '\'' +
", amountPaid=" + amountPaid +
'}';
}
}
}上述内容就是怎样使用Apache Flink中的Table SQL APIx,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/duanvincent/blog/3105069



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



